

The point-and-click graphical user interface available on Linux is a wonderful thing... but if your favorite interactive development environment consists of the terminal window, Bash, Vim, and your favorite language compiler, then, like me, you use the terminal a lot.
But even people who generally avoid the terminal can benefit by being more aware of the riches that its environment offers. A case in point – the cp command. According to Wikipedia, the cp (or copy) command was part of Version 1 of Unix. Along with a select group of other commands—ls, mv, cd, pwd, mkdir, vi, sh, sed, and awk come to mind—cp was one of my first few steps in System V Unix back in 1984. The most common use of cp is to make a copy of a file, as in:
cp sourcefile destfile
issued at the command prompt in a terminal session. The above command copies the file named sourcefile to the file named destfile. If destfile doesn't exist before the command is issued, it's created; if it does exist, it's overwritten.
I don't know how many times I've used this command (maybe I don't want to know), but I do know that I often use it when I'm writing and testing code and I have a working version of something that I want to retain as-is before I move on. So, I have probably typed something like this:
cp test1.py test1.bakat a command prompt at least a zillion times over the past 30+ years. Alternatively, I might have decided to move on to version 2 of my test program, in which case I may have typed:
cp test1.py test2.pyto accomplish the first step of that move.
This is such a common and simple thing to do that I have rarely ever looked at the reference documentation for cp. But, while backing up my Pictures folder (using the Files application in my GUI environment), I started thinking, "I wonder if there is an option to have cp copy over only new files or those that have changed?" And sure enough, there is!
Great use #1: Updating a second copy of a folder
Let's say I have a folder on my computer that contains a collection of files. Furthermore, let's say that from time to time I put a new file into that collection. Finally, let's say that from time to time I might edit one of those files in some way. An example of such a collection might be the photos I download from my cellphone or my music files.
Assuming that this collection of files has some enduring value to me, I might occasionally want to make a copy of it—a kind of "snapshot" of it—to preserve it on some other media. Of course, there are many utility programs that exist for doing backups, but maybe I want to have this exact structure duplicated on a removable device that I generally store offline or even connect to another computer.
The cp command offers a dead-easy way to do this. Here's an example.
In my Pictures folder, I have a sub-folder called Misc. For illustrative purposes, I'm going to make a copy of it on a USB memory stick. Here we go!
me@desktop:~/Pictures$ cp -r Misc /media/clh/4388-D5FE
me@desktop:~/Pictures$The above lines are copied as-is from my terminal window. For those who might not be fully comfortable with that environment, it's worth noting that me @mydesktop:~/Pictures$ is the command prompt provided by the terminal before every command is entered and executed. It identifies the user (me), the computer (mydesktop), and the current working directory, in this case, ~/Pictures, which is shorthand for /home/me/Pictures, that is, the Pictures folder in my home directory.
The command I've entered and executed, cp -r Misc /media/clh/4388-D5FE, copies the folder Misc and all its contents (the -r, or "recursive," option indicates the contents as well as the folder or file itself) into the folder /media/clh/4388-D5FE, which is where my USB stick is mounted.
Executing the command returned me to the original prompt. Like with most commands inherited from Unix, if the command executes without detecting any kind of anomalous result, it won't print out a message like "execution succeeded" before terminating. People who would like more feedback can use the -v option to make execution "verbose."
Below is an image of my new copy of Misc on the USB drive. There are nine JPEG files in the directory.
opensource.com
Suppose I add a few new files to the master copy of the directory ~/Pictures/Misc, so now it looks like this:
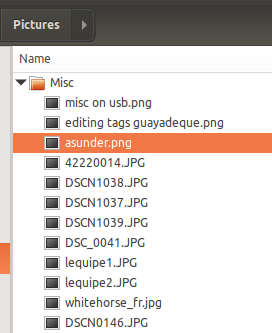
opensource.com
Now I want to copy over only the new files to my memory stick. For this I'll use the "update" and "verbose" options to cp:
me@desktop:~/Pictures$ cp -r -u -v Misc /media/clh/4388-D5FE
'Misc/asunder.png' -> '/media/clh/4388-D5FE/Misc/asunder.png'
'Misc/editing tags guayadeque.png' -> '/media/clh/4388-D5FE/Misc/editing tags guayadeque.png'
'Misc/misc on usb.png' -> '/media/clh/4388-D5FE/Misc/misc on usb.png'
me@desktop:~/Pictures$The first line above shows the cp command and its options (-r for "recursive", -u for "update," and -v for "verbose"). The next three lines show the files that are copied across. The last line shows the command prompt again.
Generally speaking, options such as -r can also be given in a more verbose fashion, such as --recursive. In brief form, they can also be combined, such as -ruv.
Great use #2 – Making versioned backups
Returning to my initial example of making periodic backups of working versions of code in development, another really useful cp option I discovered while learning about update is backup.
Suppose I'm setting out to write a really useful Python program. Being a fan of iterative development, I might do so by getting a simple version of the program working first, then successively adding more functionality to it until it does the job. Let's say my first version just prints the string "hello world" using the Python print command. This is a one-line program that looks like this:
print 'hello world'and I've put that string in the file test1.py. I can run it from the command line as follows:
me@desktop:~/Test$ python test1.py
hello world
me@desktop:~/Test$Now that the program is working, I want to make a backup of it before adding the next component. I decide to use the backup option with numbering, as follows:
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
clh@vancouver:~/Test$ ls
test1.py test1.py.~1~
clh@vancouver:~/Test$ So, what does this all mean?
First, the --backup=numbered option says, "I want to do a backup, and I want successive backups to be numbered." So the first backup will be number 1, the second 2, and so on.
Second, note that the source file and destination file are the same. Normally, if we try to use the cp command to copy a file onto itself, we will receive a message like:
cp: 'test1.py' and 'test1.py' are the same fileIn the special case where we are doing a backup and we want the same source and destination, we use the --force option.
Third, I used the ls (or "list") command to show that we now have a file called test1.py, which is the original, and another called test1.py.~1~, which is the backup file.
Suppose now that the second bit of functionality I want to add to the program is another print statement that prints the string "Kilroy was here." Now the program in file test1.py looks like this:
print 'hello world'
print 'Kilroy was here'See how simple Python programming is? Anyway, if I again execute the backup step, here's what happens:
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
clh@vancouver:~/Test$ ls
test1.py test1.py.~1~ test1.py.~2~
clh@vancouver:~/Test$Now we have two backup files: test1.py.~1~, which contains the original one-line program, and test1.py.~2~, which contains the two-line program, and I can move on to adding and testing some more functionality.
This is such a useful thing to me that I am considering making a shell function to make it simpler.
Three points to wrap this up
First, the Linux manual pages, installed by default on most desktop and server distros, provide details and occasionally useful examples of commands like cp. At the terminal, enter the command:
man cpSuch explanations can be dense and obscure to users just trying to learn how to use a command in the first place. For those inclined to persevere nevertheless, I suggest creating a test directory and files and trying the command and options out there.
Second, if a tutorial is of greater interest, the search string "linux shell tutorial" typed into your favorite search engine brings up a lot of interesting and useful resources.
Third, if you're wondering, "Why bother when the GUI typically offers the same functionality with point-and-click ease?" I have two responses. The first is that "point-and-click" isn't always that easy, especially when it disrupts another workflow and requires a lot of points and a lot of clicks to make it work. The second is that repetitive tasks can often be easily streamlined through the use of shell scripts, shell functions, and shell aliases.
Are you using the cp command in new or interesting ways? Let us know about them in the comments.





13 Comments