

Today, new storage system interfaces are created regularly to resolve emerging challenges in distributed storage. For example, Amazon Simple Storage Service [S3] (an opaque object store) and Amazon Elastic Block Storage [EBS] (a virtual machine image provider) both provide an essential, scalable storage service within a cloud ecosystem; however even with these new technologies, the conventional file system remains the most-widely used storage interface in computing.
Virtually all programs are written to use a file system at some level. This makes the file system the lingua franca for all storage access on any computing device—from small devices such as smartphones, to large high-performance computing (HPC) clusters at CERN and national labs. Programs are still written to communicate and store data through file systems because of their convenience, familiarity, and interoperability.
People generally don't think much about the details of how computing systems provide the familiar environments they are accustomed to. Even though file systems underpin all types of computing as a means for storing data in a persistent, organized, and useful way, it's not something that's on most people's radar screens. That's why few know that the Portable Operating System Interface (POSIX) has been the most widely used type of file system, ever since UNIX began dominating multi-user systems in the 1970s, even operating on today's Android and iOS mobile devices.
Unlike smartphones, HPC clusters need scalable, available, and cooperative (shared) storage. Distributed file systems provide an interface for programs from multiple, independent systems to operate and enable them to share storage in a consistent, persistent, and reliable way.
The Ceph distributed file system
The Ceph distributed storage system has included a distributed file system (CephFS) ever since it was developed by researchers at University of California, Santa Cruz. In fact, its object store, RADOS (which stands for reliable autonomic distributed object store), was originally designed and implemented for using CephFS in HPC clusters at national labs.
Since 2006, CephFS has seen incremental changes, mostly to improve stability. Ceph's development has focused on emerging trends in cloud storage, where its distributed object storage technology was expected to shine. In particular, RADOS Block Storage (RBD) and RADOS Gateway (RGW) provided storage solutions for opaque block devices and object storage, respectively. These technologies showed that Ceph was a suitable open source alternative to commercial and proprietary cloud storage solutions.
The Ceph team has rededicated itself to CephFS development, as file storage remains a dominant trend in distributed systems. The Jewel release of Ceph in April 2016 introduced CephFS as stable and ready for prime time, subject to a few caveats. Namely, multiple active metadata—which provides scalability—was still considered experimental.
CephFS's architecture
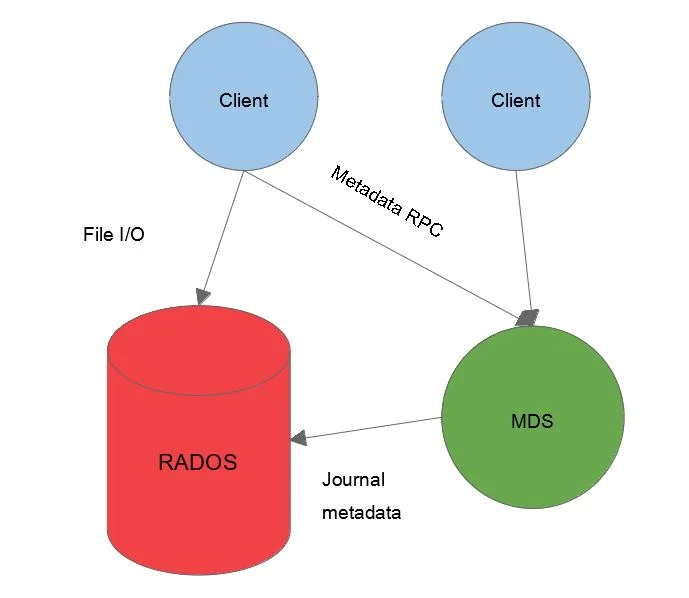
CephFS is a file storage solution part of Ceph. It works as a higher-level component within the system that provides file storage on top of RADOS, the object store upon which all Ceph storage solutions are built. Two types of entities cooperate to provide a file system interface: clients and metadata servers (MDS).
opensource.com
The MDS is a synchronization point and caching layer for all the metadata of the file system. Its primary function is to allow the clients to safely store metadata about the file system (e.g., which files a directory contains) without becoming inconsistent (e.g., two clients disagree on which files are in a directory).
A distinguishing feature of CephFS is the ability of the clients to read and write files without significant hand-holding from the MDS. A client just needs to open a file (i.e., tell the MDS it wants to use the file) and then read/write as desired, with only occasional updates to the MDS.
The consequence of this design is improved scalability of the system, where clients can perform large read/writes that linearly scale with the number of object storage devices in the RADOS cluster (but with each client limited by the bandwidth of its network link).
What's next for Ceph
The Luminous release of Ceph will provide many important enhancements for CephFS.
Multiple Active Metadata Servers
The most important change is the stability of multiple active metadata servers exporting a CephFS file system. An administrator can launch multiple metadata servers and configure the file system to use these servers together to spread metadata load evenly. This change is the product of extensive testing and bug fixes by the developers. Information on configuring a cluster to use multiple active metadata servers is available in the documentation.
Directory fragmentation
Directory fragmentation is now enabled by default in Luminous. This change allows a directory to be internally fragmented into smaller directories, which can improve performance and allow splitting a directory's metadata load across multiple servers. Like the multiple active metadata servers, this feature has been available in CephFS since the beginning but is now considered stable due to increased testing and bug fixes. This feature is transparent and does not require any administrator or user input.
Subtree Pinning
Administrators now can also explicitly pin a directory subtree to a particular metadata server. This allows the administrator to override the metadata balancer in a multiple active metadata server cluster when it is considered ineffective or undesirable. For example, an operator may decide that a particular directory should only use the resources of a single metadata server. These pins permit such a basic policy. Learn more about this feature in the documentation.
CephFS users can expect improved scalability and stability of their file system. Future work on CephFS will continue to improve usability and stability. Learn more about Ceph and CephFS on ceph.com.
Learn more about Ceph in Gregory Farnum's talk, CephFS — The Stable Distributed Filesystem, at the Open Source Summit in Los Angeles.




1 Comment