

I've been working on a data scraping project for a customer and started using Apache Tika after some experimentation showed me that it does a nice job of pulling text out of PDF files. This week, I was confronted with a new data source in DBF format, and it turns out Tika handles that as well.
Encouraged by this pleasantly seamless experience, I decided it was time to learn a bit more about Tika. I found myself stumbling around a fair bit trying to understand how to deal with the decoded information. Neither the Tika website nor the book Tika in Action covered what I needed, nor could I find anything with my favorite search engine that addressed the problem I was trying to solve.
Because Tika is open source, I downloaded the source code to get some working examples and started experimenting. Here's how I ultimately did what I needed to do—I hope some people find it useful.
Before I start, I should mention that Tika is written in Java and my examples are written in Groovy.
The problem
Tika's architecture consists of several components. Of special interest are the Parser, which takes apart the input data and converts it into a sequence of Simple API for XML (SAX) events, and the ContentHandler interface, which puts that SAX information into the programmer's hands.
From my perspective (as someone with a bunch of data in various formats), Tika is one of those wonderful open source "platform" projects that has encouraged participants in other open source projects to contribute (in this case with parsers that decode information), fostering its sharing and use. And there are a remarkable number of source formats handled by Tika (see the git page showing its mimetypes.xml).
Using Tika in my code made it easy-peasy to decode tabular file formats such as DBF or XLS. However, I could not find a content handler that met my needs. The content handlers that Tika provides seemed to fall into two main categories: the first delivered my converted input on a field-by-field basis or as a set of lines of text, with fields delimited by tab characters; the second gave me an XML/HTML document. Neither of these really fit my needs.
For example, this LibreOffice spreadsheet:
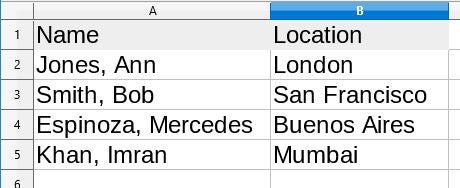
opensource.com
saved as an XLS file, then processed by BodyContentHandler, comes out looking like this:
Sheet1
→ Name → Location
→ Jones, Ann → London
→ Smith, Bob → San Francisco
→ Espinoza, Mercedes → Buenos Aires
→ Khan, Imran → Mumbai
&C&"Times New Roman,Regular"&12&A
&C&"Times New Roman,Regular"&12Page &Pwhere → represents a tab character.
When it is processed by ToXMLContentHandler, its body comes out looking like this:
<body><div class="page"><h1>Sheet1</h1>
<table><tbody><tr> <td>Name</td> <td>Location</td></tr>
<tr> <td>Jones, Ann</td> <td>London</td></tr>
<tr> <td>Smith, Bob</td> <td>San Francisco</td></tr>
<tr> <td>Espinoza, Mercedes</td> <td>Buenos Aires</td></tr>
<tr> <td>Khan, Imran</td> <td>Mumbai</td></tr>
</tbody></table>
<div class="outside">&C&"Times New Roman,Regular"&12&A</div>
<div class="outside">&C&"Times New Roman,Regular"&12Page &P</div>
</div>
</body>Neither of these seemed ideal. I didn't like using tab characters as delimiters—what if one of my fields contains a tab?—nor could I find a way to set that character to anything else. And as for the XML/HTML, it seemed downright weird to invoke an XML parser on this text, just to pick it apart.
As I was thinking this over and looking for examples of customizing the content handler, I noticed two key things: first of all, content handlers specifically and SAX in general are separate from Tika, so I started looking elsewhere for information on them; and second, Tika provides (with too little fanfare for me) the perfect starting point for customization: the ContentHandlerDecorator. As the ContentHandlerDecorator API page notes, "subclasses can provide extra decoration by overriding one or more of the SAX event methods." (For more about decorator, read about the decorator pattern on Wikipedia.)
Could ContentHandlerDecorator give me a nice way to convert my SAX event sequence into what I needed, without a lot of extra tomfoolery?
The solution
Basically, I wanted a way to produce a list of hash tables, where each hash table corresponds to a row in the tabular data, with keys set to the column names and values set to the cell contents in the appropriate row and column. In Groovy, my spreadsheet, presented in this fashion, would be declared as:
def data = [
[Name: 'Jones, Ann', Location: 'London'],
[Name: 'Smith, Bob', Location: 'San Francisco'],
[Name: 'Espinoza, Mercedes', Location: 'Buenos Aires'],
[Name: 'Khan, Imran', Location: 'Mumbai']
]I read over the source code for Tika's various content handlers, and I learned that I could accomplish my aim by overriding just three methods in the ContentHandlerDecorator:
- the startElement() method would be called for every HTML element, e.g., <TABLE>, <TR>, <TD>, at the beginning of each one of those document elements;
- the endElement() method would be called for every HTML element, e.g., </TABLE>, </TR>, </TD>, at the end of each one of those document elements; and
- the characters() method would be called whenever text needed to be written out.
I needed to implement those methods to:
- decide when to save the text sent to characters();
- use startElement() to watch for <TD> and turn on saving of text;
- use endElement() to watch for </TD> and turn off saving of text;
- use startElement() to watch for <TR> and create an empty list for saving the row data;
- use endElement() to watch for </TR> and convert the list of row data to a map and add that map to the list of row maps; and, oh yeah,
- use endElement() to treat the first row as headings instead of data and save it to a list of headings rather than row data.
Simple! Let's write some code!
First, in Groovy I created a ContentHandlerDecorator as follows:
def handler = new ContentHandlerDecorator() {
// we know we need a row counter and a list of row maps
int rowCount = 0
def rowMapList = []
// we also know we need a list of column names and row values
def columnNameList = []
def rowValueList
// we know we want to give the user access to rowMapList[]
public def getRowMapList() {
rowMapList
}
// we may as well offer a String version of rowMapList[]
@Override
public String toString() {
rowMapList.toString()
}
// rest of the code goes in here
}Next, I needed to save the text that is of interest:
boolean inDataElement = false
StringBuffer dataElement
@Override
public void characters(char[] ch, int start, int length) {
if (inDataElement)
dataElement.append(ch, start, length)
}I used a StringBuffer, which is essentially a mutable string. It seems to be a perfect fit with the parameters of characters(). This code follows the comment, "the rest of the code goes in here" in the previous block of code.
Next, I needed to process the end of data elements and rows:
@Override
void endElement(String uri, String localName, String name) {
switch (name) {
case 'td':
inDataElement = false
if (rowCount == 0)
columnNameList.add(dataElement.toString())
else
rowValueList.add(dataElement.toString())
break
case 'tr':
if (rowCount > 0)
rowMapList.
add([columnNameList, rowValueList].
transpose().
collectEntries { e ->
[(e[0]): (e[1].trim())]
})
rowCount++
break
default: break
}
}This code snippet goes right after the previous one. It contains good lessons—and a bit of pretty groovy Groovy—so it's worthwhile going over it in detail:
- In testing how the SAX event sequence works, I determined that I really only needed to look at the name parameter of the start and end elements.
- I'm using Groovy's ability to switch () { … } on string values to pick up the </TR> and </TD> elements.
- When I encounter </TD>, I know that the data element just processed will go into the column name list if it's on the first record, otherwise it will go into the row value list.
- When I encounter </TR>, I know that if I am on the second or subsequent rows, I need to convert the column name list and the row value list to my row map.
- I use transpose() to interleave the column name / row value pairs in a list.
- Then I use collectEntries() to convert the pairs of column name and row value to map entries.
- And I remember to update the row count!
Finally, I set it to process the start of data elements and rows:
@Override
void startElement(String uri, String localName, String name,
org.xml.sax.Attributes atts) {
switch (name) {
case 'tr':
if (rowCount > 0)
rowValueList = []
break
case 'td':
inDataElement = true
dataElement = new StringBuffer()
break
default: break
}
}This looks for <TR> to (re)initialize the row value list and for <TD> to note that it's processing a useful data element and it's time to save the characters passed to the helper in the new string buffer. Once again, this code immediately follows the previous code.
That's it! To use this code, run something like this:
import org.apache.tika.*
import org.apache.tika.parser.*
import org.apache.tika.metadata.*
import org.apache.tika.sax.*
// define the file we’re reading and get an input stream
// based on that file
def file = new File('test.xls')
def fis = new FileInputStream(file)
// define the metadata and parser
def metadata = new Metadata()
def parser = new AutoDetectParser()
// define the content handler (copy the code created above)
def handler = new ContentHandlerDecorator() {
// …
};
// parse the input file
parser.parse(fis, handler, metadata)
// here we visit all the elements in the row map list
// and print out each row map, one per line
handler.rowMapList.each { map ->
println map
}
fis.close()to get this output:
[Name:Jones, Ann, Location:London]
[Name:Smith, Bob, Location:San Francisco]
[Name:Espinoza, Mercedes, Location:Buenos Aires]
[Name:Khan, Imran, Location:Mumbai]Just what the doctor ordered!
So now in place of the handler.rowMapList.each { map -> … } closure, I can study each cell value. For example:
if (map.Name == ‘Smith, Bob’)
map.Location = ‘Nairobi’when I want to move Bob Smith from London to Nairobi, or
new Employee(name: map.Name, location: map.Location).save()when I want to insert the data into my Grails database.
As I've discovered, the Tika Parser is great for picking things apart, but the ContentHandler interface is key to putting it back together in a useful way.





Comments are closed.