

Code review is a practice that facilitates the rapid collaboration, sharing of knowledge, and supreme quality typical in open source projects. The code review social structure is a defining characteristic of a project. What is the best social structure for an open source project?
In this article, we examine this question by analyzing three common models: the benevolent dictator for life (BFDL), hierarchy, and community models with two graph theory metrics that quantify their robustness and information transmission capabilities.
Quantifying their properties
We can assess models in Figures 1-3 with metrics defined in social network theory. In these models, each node represents a person and each edge represents a code review.
The size of nodes in the graph visualizations are scaled by a measure of information transmission, closeness centrality. Closeness centrality is a normalized measure, with values that range from zero to one, that quantifies the inverse of the average distance to all other people in the code review network. When closeness centrality is high, knowledge is communicated well. High closeness means that experiences and knowledge of many peers are transmitted so individual contributions are strengthened by the size of the network.
The color of nodes in the graph visualization are mapped according to how critical they are to maintaining communication within the network. Blue nodes have a low betweenness centrality, red nodes a high betweenness centrality, and purple hued nodes are somewhere in the middle. Betweenness centrality is a normalized measure of the number of shortest paths that pass through a reviewer. Nodes with high betweenness centrality reflect poorly on the robustness of that network—if those nodes would fail, communication in the network will fall apart.
How the models perform
The BDFL model, Figure 1, performs very well in information transmission (closeness centrality), but lacks robustness. Since the central BFDL node is involved in all the reviews, they impart their knowledge and pass on information from every other participant in the network. However, the central BFDL node is also a single point of failure. Should the BDFL switch jobs, go on vacation, discover a new programming language, get hit by a bus, be abducted by aliens, etc., the network will collapse. The degree of the central node, how many code reviews that are performed, is also very high. This is likely to cause burnout and makes it difficult for the network to scale.
While the hierarchical structure in Figure 2 can scale without requiring any single node to have a high degree, it fails in both and robustness and information transmission properties. The network is vulnerable to losses at the top of the hierarchy. And the information transmission, visualized as the size of the nodes, is poor throughout the entire network.
While the community code review structure in Figure 3 lacks the regularity found in Figure 1 or Figure 2, it both has high information transmission capabilities and is very robust. While there is not an express BFDL or top of the hierarchy, leaders still emerge in this structure. Leading roles are determined by actions, e.g. the amount of reviews performed, instead of their position in the network. But there are additional requirements in this free form organization. Higher amounts of communication are necessary—there are more edges than the other models. Also, this situation requires tools and objective criteria to make effective decisions; whether to merge a patch can depend on whether it passes all unit tests, has reached the standard testing code coverage, passes automated style checks, etc. as opposed to "whether Lieutenant Dan says so."
Conclusions
We have seen that a community code review structure is mathematically superior to centralized or hierarchical systems in its ability to spread knowledge effectively and its vulnerability to people's changing life situations or poor performance or burnout. Of course, these are not the only important factors -- for example, these models do not capture the value of an individual's level of experience.
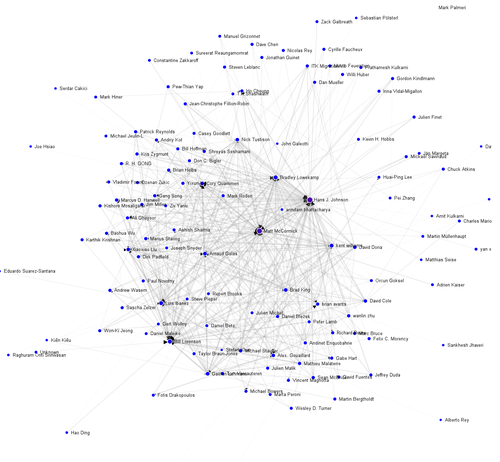
Figure 4: Code review network of a real project, the Insight Toolkit (ITK). Like the other figures, the size of the nodes is related to its closeness centrality, and the color of nodes is coded by their betweenness centrality. The width of edges is related to the number of reviews. Click for the full visualization.
Also, real projects are not cleanly classified in one of these idealized models; most are a hybrid of the described models or other models. An example based on real data is the code review structure of the Insight Toolkit, Figure 4. Projects that claim to operate under a BFDL model cannot scale without some distributed workload. Projects that claim to operate under a community structure are influenced by tenured operations.
Finally, it is important to remember that the code review structure is secondary to the quality and quantity of those performing code reviews. The practice of code reviews in open source communities is an opportunity to learn from each other and serve one another.
Source code for the analysis and visualizations presented in this article are available on GitHub. The data and visualization in Figure 4 are derived from an article describing ITK's role in reproducible research.


2 Comments