

Although many companies today possess massive amounts of data, the vast majority of that data is often unstructured and unlabeled. In fact, the amount of data that is appropriately labeled for a specific business need is typically quite small (possibly even zero), and acquiring new labels is usually a slow, expensive endeavor. As a result, algorithms that can extract features from unlabeled data to improve the performance of data-limited tasks are quite valuable.
Most machine learning practitioners are first exposed to feature extraction techniques through unsupervised learning. In unsupervised learning, an algorithm attempts to discover the latent features that describe a data set's "structure" under certain (either explicit or implicit) assumptions. For example, low-rank singular value decomposition (of which principal component analysis is a specific example) factors a data matrix into three reduced rank matrices that minimize the squared error of the reconstructed data matrix.
Representation learning
Although traditional unsupervised learning techniques will always be staples of machine learning pipelines, representation learning has emerged as an alternative approach to feature extraction with the continued success of deep learning. In representation learning, features are extracted from unlabeled data by training a neural network on a secondary, supervised learning task.
Due to its popularity, word2vec has become the de facto "Hello, world!" application of representation learning. When applying deep learning to natural language processing (NLP) tasks, the model must simultaneously learn several language concepts:
- the meanings of words
- how words are combined to form concepts (i.e., syntax)
- how concepts relate to the task at hand
For example, you may have heard of the neural network that generates color names. Essentially, the model was trained to generate names for colors from RGB values using paint swatch data. While the concept was really neat, the results were fairly underwhelming; the model seemed to produce nonsensical color names and randomly pair names with colors. The task, as attempted, was simply too difficult for the model to learn, given the paucity of data.
Word2vec makes NLP problems like these easier to solve by providing the learning algorithm with pre-trained word embeddings, effectively removing the word meaning subtask from training. The word2vec model was inspired by the distributional hypothesis, which suggests words found in similar contexts often have similar meanings. Specifically, the model is trained to predict a central word given its surrounding words in a window of a certain size. For example, for the sentence "Natural language processing can be difficult" and a window size of three, the input/target combinations for the neural network would be:
["natural", "processing"] → "language"
["language", "can"] → "processing"
["processing", "be"] → "can"
["can", "difficult"] → "be"
When trained with enough data, the word embeddings tend to capture word meanings quite well, and are even able to perform analogies, e.g., the vector for "Paris" minus the vector for "France" plus the vector for "Italy" is very close to the vector for "Rome." Indeed, by incorporating word2vec vectors into the color names model, I achieved much more compelling results.
Customer2vec
Red Hat, like many business-to-business (B2B) companies, is often faced with data challenges that are distinct from those faced by business-to-consumer (B2C) companies. Typically, B2B companies handle orders of magnitude fewer "customers" than their B2C counterparts. Further, feedback cycles are generally much longer for B2B companies due to the nature of multi-year contracts. However, like B2C companies, many B2B companies possess mountains of behavioral data. Representation learning algorithms give B2B companies like Red Hat the ability to better optimize business strategies with limited historical context by extracting meaningful information from unlabeled data.
In many ways, web activity data resembles the data found in NLP tasks. There are terms (= specific URLs), sentences (= days of activity), and documents (= individual customers). With that being the case, web activity data is a perfect candidate for doc2vec. Doc2vec is a generalization of word2vec that, in addition to considering context words, considers the specific document when predicting a target word. This architecture allows the algorithm to learn meaningful representations of documents, which, in this instance, correspond to customers.
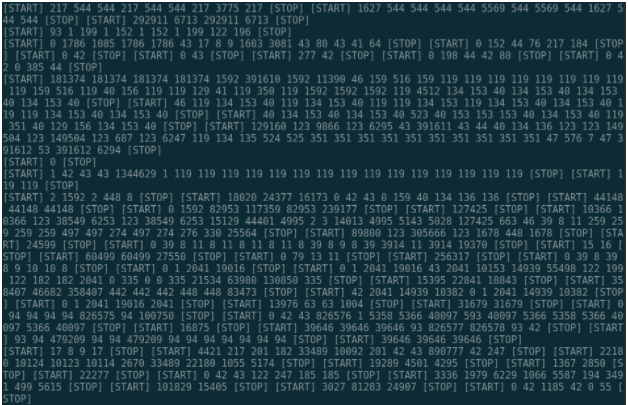
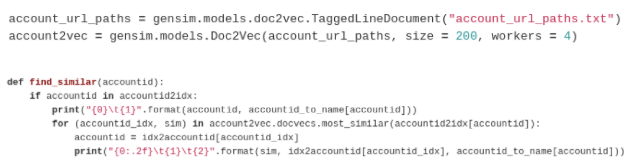
As an example, Red Hat data can be seen in Figure 1, where each line represents a different customer, each number represents a distinct URL, and the special [START] and [STOP] tokens denote the start and end of a day of activity. Once the data is in this format, training the model is as simple as two lines of code with gensim (Figure 2). These customer representations can then be used to form better segments for sales campaigns and product recommendations.
opensource.com
opensource.com
But representation learning models can be even more flexible than word2vec and doc2vec. For example, I've found that predicting at-bat outcomes for Major League Baseball batter/pitcher pairs can generate highly intuitive player embeddings.
Duplicate detection
Red Hat is also exploring the applicability of representation learning for detecting duplicate support content. Here, "duplicate" doesn't mean "exact copy," rather it indicates content that is conceptually redundant. Duplicate content can cause issues with information retrieval and introduce challenges when identifying support trends, so being able to effectively detect and remove duplicate content is important.
One strategy for duplicate detection is to look for similar latent semantic analysis (LSA) vectors, but there are assumptions and design elements in LSA that limit its effectiveness. Specifically, the model
- ignores word ordering
- implicitly assumes a Gaussian distribution on the term values by minimizing the squared error on the reconstructed matrix
- assumes that the term values are generated from a linear combination of the latent document and term vectors
Neural networks relax these assumptions, which makes them a good candidate for learning semantic representations of documents.
But the question remains of how to use a neural network for duplicate detection without any labeled data. To do so, we adapted the Deep Semantic Similarity Model (DSSM) developed by Microsoft Research for the task (a Keras implementation of the model can be found on my GitHub). The original motivation for the DSSM was to improve the relevance of search results by mapping documents and queries into a latent semantic space and use the cosine similarity of these vectors as a proxy for relevance. Essentially, the model compresses the documents and queries down to their essential concepts. To adapt the model for duplicate detection, we simply used document titles in place of queries and trained an otherwise nearly identical architecture (though we did use internally trained word2vec embeddings instead of letter-gram representations for words). The semantic document vectors were then used to find conceptually similar content.
Learn more about representation learning
This barely scratches the surface of representation learning, which is an active area of machine learning research (along with the closely related field of transfer learning). For an extensive, technical introduction to representation learning, I highly recommend the "Representation Learning" chapter in Goodfellow, Bengio, and Courville's new Deep Learning textbook. For more information on word2vec, I recommend checking out this nice introduction by the folks over at DeepLearning4J.
Article republished with permission from MLConf.com. Use promo code "Redhat18" to save 18% off registration for the 2017 Machine Learning Conference in Atlanta, which will be held September 15.





Comments are closed.