

The role of data has changed. Data is more than a record; it is a form of communication. Data enhances lives. It makes us more efficient in navigation, banking, shopping, and managing our day-to-day lives. Ultimately, the exchange, valuation, and intelligence of data are currency. Beyond storing it, data must be captured, preserved, accessed, and transformed to take advantage of its possibilities.
Most all discussions about today's data begin with it growing at an exponential rate, doubling every two years that will reach hundreds of zettabytes next decade. This data deluge is driving the multiple Vs (volume, velocity, variety, and value), and requires a longer shelf life for future analysis, extracting further value and intelligence that enables better business and operational decisions.
What's driving this data-centric world is that the role of data is changing, evolving from just being a record or a log of events, recordings or measurements, to forms of communication that deliver efficiencies in productivity and automation, and ultimately, the value that data delivers, become a form of currency. Also driving data growth is that the abundance of sources for data generation is increasing as well. Data no longer is just generated from applications, but it now comes from mobile devices, production equipment, machine sensors, video surveillance systems, Internet of Things (IoT) and industrial IoT (IIoT) devices, healthcare monitors, and wearables, to name a few.
And, the data that is being generated is created in both large-scale data centers at the "core," and in remote and mobile sources at the "edge" of the network.

opensource.com
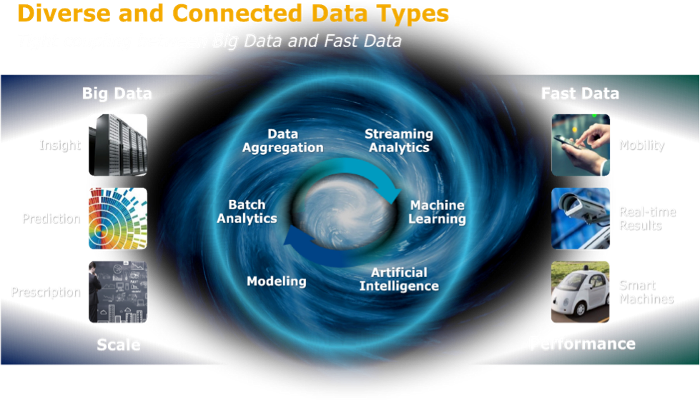
Big data applications that analyze very large and disparate datasets using computations and algorithms are spawning. These applications reveal trends, patterns, and associations. These valuable insights connect and drive more precise predictions and enable better decisions to achieve better outcomes. Because big data analysis is based on information captured from the past, today's applications also require immediate analysis of information as it happens.
As a result, there's a parallel track accompanying big data: fast data, where the immediacy of data is critical. Fast data has a different set of characteristics. Fast data applications process or transform data as it is captured, leveraging the algorithms derived from big data to provide real-time decisions and results. Whereas big data provides insights derived from "what happened" to forecast "what will likely happen" (predictive analysis), fast data delivers insights that drive real-time actions. This is particularly beneficial to "smart" machines, environmental monitors, security and surveillance systems, securities trading systems, and applications that require analysis, answers, and actions in real time.
Data drives the need for purpose-built processing
The big data revolution has created the need to manage and control large datasets. This is typically achieved with general-purpose (GP) processors. Today, all data centers are based on this type of compute platform. As big data applications like artificial intelligence (AI), machine learning, and analytics emerge, and as we collect data from mobile devices, surveillance systems, and smart machines, more special-purpose compute capabilities are required.
opensource.com
With processor technologies evolving from GP central processing units (CPUs) to specialty (purpose-built) processors designed to solve a particular problem—such as graphics processing units (GPUs), field-programmable gate arrays (FPGAs), and application-specific integrated circuits (ASICs)—general compute capabilities can be expanded to attack specific challenges that big data and fast data applications need to solve. And, it's not just the compute part of the architecture that needs attention, but the entire solutions stack built around it, as the needs are expanding far beyond what general compute can deliver.
General compute focuses only on the CPU, not the data. It provides the lowest common denominator of resources. It is unlikely that the ratio of resources is implemented optimally for fast data applications, new machine learning implementations, or genomics. While GP compute supports many applications, it cannot solve all problems. This is a call to consider purpose-built processing.
Addressing big data and fast data applications
Data-intensive workloads create opportunities and a new breed of purpose-built processing requirements, storage-centric architectures (which support big data applications), and memory-centric architectures (which support fast data applications). Big data has massive, petabyte storage requirements and its processing needs may vary. For example, analytics requires moderate processing when the analysis needs to be performed, yet in a machine learning environment, massive specialty processing is required continuously as the machine is taught.
Conversely, in a fast data application, you need immediate access to data for security detection (video surveillance), event correlation (relationship analysis between events), and blockchain (cryptographically securing blocks of records). In addition to specialty processing, large memory plays a key role in this scenario, since a vast amount of main memory can solve problems that otherwise cannot be solved by having I/O operations go through a deep I/O stack.

opensource.com
Appointing decision-making to the CPU, allowing it to dictate memory, I/O, and other resources is a barrier to development.
Processing at the edge
The ability to compute data and obtain real-time intelligence at the edge of the network, where the data lives, is important to support new, creative applications. These types of applications are developed and designed to take valuable context from captured content immediately.
Advancements in computing enable this new class of applications at the edge, generated by the Internet of Things (IoT) and industrial IoT (IIoT) devices and systems. The RISC-V open instruction set architecture (ISA) plays a powerful role here.
How RISC-V supports tomorrow's data needs
RISC-V is an ISA that that enables processor innovation through open standard collaboration. It delivers a new level of open, extensible software and hardware freedom on processor architectures, paving the way for a new era of computing design and innovation. In contrast to RISC-V's open standards approach, some commercial chip vendors charge license fees for the use of their proprietary source code and patents.
Based on its open, modular approach, RISC-V is ideally suited to serve as the foundation for data-centric compute architectures. As an operating system processor, it can enable purpose-built architectures by supporting the independent scaling of resources. Its modular design approach allows for more efficient processors in support of edge-based and mobile systems. As big data and fast data applications start to create more extreme workloads, purpose-built architectures will be required to pick up where today's GP architectures have reached their limit.

opensource.com
RISC-V has the capabilities, foundation, ecosystem, and openness required for storage-centric architectures that support big data applications like AI, machine learning, and analytics. RISC-V can also support memory-centric architectures that support fast data and all edge-based and real-time applications. If a design requires multiple petabytes of main memory, RISC-V enables optimized design. If the application has minor processor design needs, but large memory requirements, or thousands of processing cores and very little I/O, RISC-V enables independent scaling of resources and a modular design approach.
Soon the world will see new classes of processor design optimized for a specific application or to solve a particular need. RISC-V has many capabilities to support this requirement. It provides 16 to 128 bits of independent scalability and a modular design well-suited for both embedded and enterprise applications. RISC-V's ability to deliver capabilities across both big data and fast data spectrums, process across both storage-centric and memory-centric architectures, and deliver value from the data, will help move processor designs to become data-centric.
Future direction
RISC-V opens a wealth of opportunities to extend data-centric architectures, bring new instructions to the fold, and process data where it resides. Currently, we see ecosystems that unnecessarily shuttle data around the data center. There is value in processing data where it lives.
There are many options to develop purpose-built processors for big data and fast data environments. These include leveraging the broad community of RISC-V inventors who can bring processing closer to data within storage and memory products, or who will actively partner, co-develop, or invest in the ecosystem to undertake a development effort. The result will be processors that can deliver special-purpose capabilities and add value to the data captured.




Comments are closed.