

Programming is an activity that helps implement a model. What is a model? Typically, programmers model real-world situations, such as online shopping.
When you go shopping in the real world, you enter a store and start browsing. When you find items you'd like to purchase, you place them into the shopping cart. Once your shopping is done, you go to the checkout, the cashier tallies up all the items, and presents you with the total. You then pay and leave the store with your newly purchased items.
Thanks to the advancements in technology, you can now accomplish the same shopping activities without traveling to a physical store. You achieve that convenience by having a team of software creators model actual shopping activities and then simulate those activities using software programs.
Such programs run on information technology systems composed of networks and other computing infrastructure. The challenge is to make a reliable system in the presence of failures.
Why failures?
The only way to offer virtual capabilities such as online shopping is to implement the model on a network (i.e., the internet). One problem with networks is that they are inherently unreliable. Whenever you plan to implement a network app, you must consider the following pervasive problems:
- The network is not reliable.
- The latency on the network is not zero.
- The bandwidth on the network is not infinite.
- The network is not secure.
- Network topology tends to change.
- The transport cost on the network is not zero.
- The network is not homogenous.
- "Works on my machine" is not a proof that the app is actually functional.
As can be seen from the above list, there are many reasons to expect failures when planning to launch an app or service.
What is a system?
You depend on a system to support the app. So, what is a system?
A system is something that stands together, meaning it's a composition of programs that offer services to other programs. Such a design is loosely coupled. It is distributed and decentralized (i.e., it does not have global supervision/management).
What is a reliable system?
Consider the attributes that make up a reliable system:
- A reliable system is a system that is always up and running. Such a system is capable of graceful degradation, meaning that when performance starts to degrade, the system will not suddenly stop working.
- A reliable system is not only always up and running, but it is also capable of progressive enhancement. As the demand for the system's capabilities increases, a reliable system scales to meet the needs.
- A reliable system is also easily maintainable without expensive changes.
- A reliable system is low-risk. It is safe and simple to deploy changes to such a system, either by rolling back or forward.
Everything built eventually exceeds the ability to understand it
Every successful system was created from a much simpler design. As systems are enhanced and embellished, they eventually reach a point where their complexity cannot be easily understood.
Consider a system that consists of many moving parts. As the number of moving parts in the system increases, the degree of interdependence between those moving parts also increases (Figure 1).
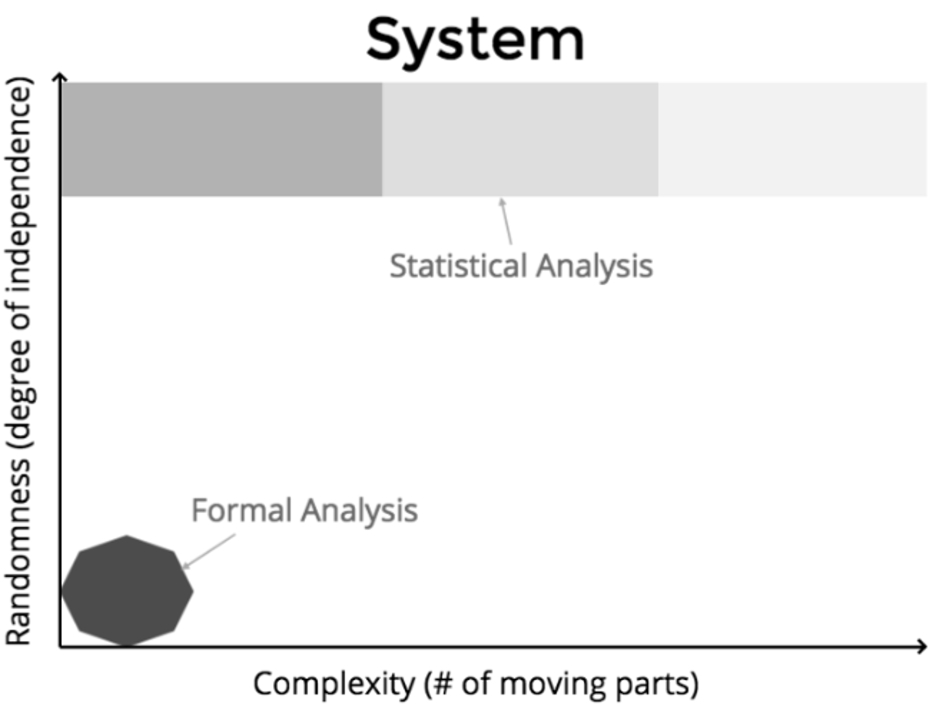
(Alex Bunardzic, CC BY-SA 4.0)
It is only during the early stages of the growth of that system that people can perform a formal analysis of the system. After a certain point of system complexity, humans can only reason about the system by applying statistical analysis.
There is a gap between formal analysis and statistical analysis (Figure 2).
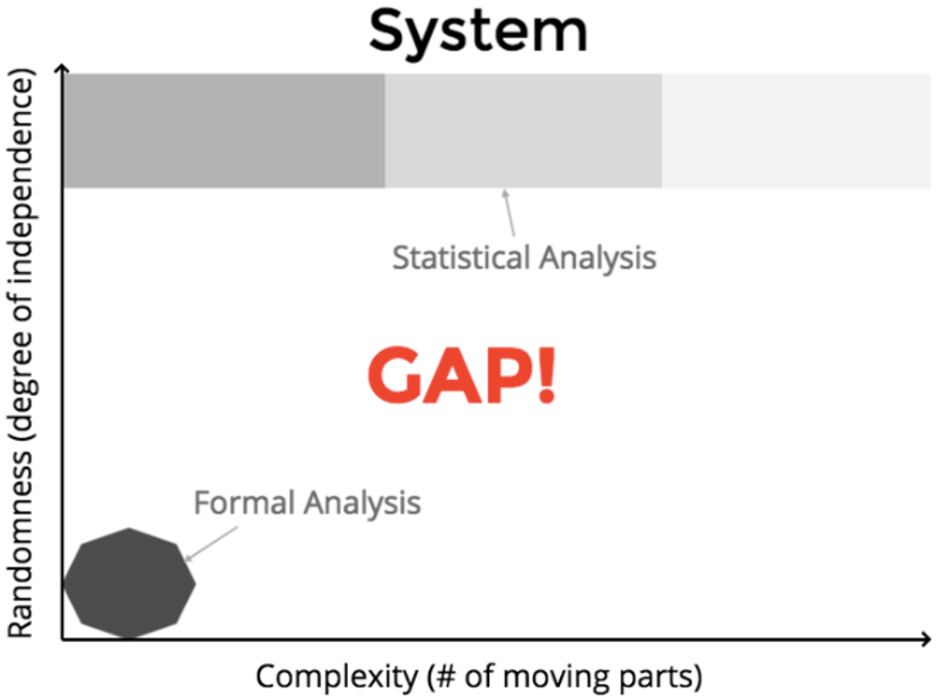
(Alex Bunardzic, CC BY-SA 4.0)
How to program a system?
Developers know how to write useful apps, but they must also know how to program a system that enables the app to function on the network.
It turns out that there doesn't seem to be a system programming language available. While developers may know many programming languages (e.g., C, Java, C++, C#, Python, Ruby, JavaScript, etc.), all those languages specialize in modeling and emulating the functioning of an app. But how does one model system functionality?
Look at how the system is assembled. Basically, in a system, programs talk to each other. How do they do that?
They communicate over a network. Since there cannot be a system without two or more programs talking to each other, it is clear that the only way to program a system is to program a network.
Before looking more closely at how to program a network, I will examine the main problem with networks—failure.
Failures are at the system level
How do failures occur in a system? One way is when one or more programs suddenly becomes unavailable.
That failure has nothing to do with programming errors. Actually, programming errors are not really errors—they are bugs to be squashed!
A network is basically a chain, and as everyone knows, a chain is only as strong as its weakest link.
When a link breaks (i.e., when one of the programs becomes unavailable), it is critical to prevent that outage from bringing the entire system down.
How do administrators do that? They provide an abstraction boundary that stops the propagation of errors. I will now examine ways to provide such an abstraction boundary inside the system. Doing that amounts to programming a system.
Best practices in system programming
It is very important to design programs and services to meet the needs of the machines. It is a common mistake to create programs and services to serve human needs. But when doing systems programming, such an approach is incorrect.
There is a fundamental difference between designing services for machines versus humans. Machines do not need operational interfaces. However, humans cannot consume services without a functional interface.
What machines need is programming interfaces. Therefore, when doing systems programming, focus entirely on the application programming interfaces (APIs). It will be easy to bolt operational interfaces on top of the already implemented programming interfaces, so do not rush into creating operational interfaces first.
It is also important to build only simple services. This may seem unreasonable at first, but once you understand that simple services are easily composable into more complex ones, it makes more sense.
Why are simple services so essential when doing systems programming? By focusing on simple services, developers minimize the risk of slipping into premature abstraction. It becomes impossible to over-abstract such simple services. The result is a system component that is easy to make, reason about, deploy, fix, and replace.
Developers must avoid the temptation to turn the service into a monolith. Abstain from doing that by refusing to add functionalities and features. Furthermore, resist turning service into a stack. When other users (programs) decide to use the services the component offers, they should be free to choose commodities suitable for the consumption of the services.
Let the service users decide which datastore to use, which queue, etc. Programmers must never dictate a custom stack to clients.
Services must be fully isolated and independent. In other words, services must remain autonomous.
Value of values
What is a value in the context of programming? The following attributes characterize a value:
- No identity
- Ephemeral
- Nameless
- On the wire
Consider an example value of a service that returns the total monthly service charge. Suppose a customer receives $425.00 as a monthly service charge. What are the characteristics of the value $425.00?
- It has no identity.
- No name – it is just four hundred twenty-five dollars—no need for a separate name.
- It is ephemeral – as the time progresses, the monthly charge keeps changing.
- It is always sent on a wire and received by the client.
The ephemeral nature of values implies flow.
Systems are not place-oriented
A place-oriented product could be depicted as a ship being built in a shipyard.
Systems are flow-oriented
For example, cars are built on a moving assembly line.
How do values flow in the system?
Values undergo transformations and are moved, routed, and recorded.
- Transform
- Move
- Route
- Record
- Keep the above activities segregated
How do values move in the system?
- Source => destination
- Mover (producer) depends on identity/availability
- Must decouple producers from consumers
- Must remove dependency on identity
- Must remove dependency on availability
- Use queues Pub/sub
It is essential to avoid dependencies for values to flow effectively through the system. Brittle designs include processes that count on a certain service being found by its identity or requiring a certain service to be available. The only robust design that allows values to flow through the system is using queues to decouple dependencies. It is recommended to use the publish/subscribe queuing model.
Design services primarily for machines
Avoid designing services to be consumed by humans. Machines should never be expected to access services via operational interfaces. Build human operational interfaces only after you've built a machine-centric service.
Strive to build only simple services. Simple services are easily composable. When designing simple services, there is no danger of premature abstraction.
It is not possible to over-abstract a simple service.
Avoid turning a service into a monolith
Abstain from adding functionality and features (keep it super simple). Avoid at all costs turning a service into a stack. Allow service users to choose which commodities to use when consuming them. Let them decide which datastore to use, which queue, etc. Don't dictate your custom stack to clients.
System failure model is the only failure model
Next, acknowledge that system failures are guaranteed to happen! It is not the question of if but when and how often.
When do exceptions occur? Any time a runtime system doesn't know what to do, the result is an exception and a system failure.
Those failures are different from programming errors. The errors occur when a team makes mistakes while implementing the processing logic (developers call those errors "bugs").
Whenever a system fails, notice that it is partial and uncoordinated. It is improbable that the entire system would fail at once (almost impossible for such an event to happen).
Minimum requirements for reliable systems
At a minimum, a reliable system must possess the following capabilities:
- Concurrency
- Fault encapsulation
- Fault detection
- Fault identification
- Hot code upgrade
- Stable storage
- Asynchronous message passing
I'll examine those attributes one by one.
Concurrency
For the system to be capable of handling two or more processes concurrently, it must be non-imperative. The system must never block the processing or apply the "pause" button on the process. Furthermore, the system must never depend on a shared mutable state.
In a concurrent system, everything is a process. Therefore, it is paramount that a reliable system must have a lightweight mechanism for creating parallel processes. It also must be capable of efficient context switching between processes and message passing.
Any process in a concurrent system must rely on fault detection primitives to be able to observe another process.
Fault encapsulation
Faults that occur in one process must not be able to damage/impair other processes in the system.
"The process achieves fault containment by sharing no state with other processes; its only contact with other processes is via messages carried by a kernel message system." - Jim Gray
Here is another useful quote from Jim Gray:
"As with hardware, the key to software fault-tolerance is to hierarchically decompose large systems into modules, each module being a unit of service and a unit of failure. A failure of a module does not propagate beyond the module."
To achieve fault tolerance, it is necessary to only write code that handles the normal case.
In case of a failure, the only recommended course of action is to let it crash! It is not a good practice to fix the failure and continue. A different process should handle any error (the escalation error handling model).
It is crucial to constantly ensure clean separation between error recovery code and normal case code. Doing so greatly simplifies the overall system design and system architecture.
Fault detection
A programming language must be able to detect exceptions both locally (in the process where the exception occurred) and remotely (seeing that an exception occurred in a non-local process).
A component is considered faulty once its behavior is no longer consistent with its specification. Error detection is an essential component of fault tolerance.
Try to keep tasks simple to increase the likelihood of success.
In the face of failure, administrators become more interested in protecting the system against damage than offering full service. The goal is to provide an acceptable level of service and become less ambitious when things start to fail.
Try to perform a task. If you cannot perform a task, try to perform a simpler task.
Fault identification
You should be able to identify why an exception occurred.
Hot code upgrade
The ability to change code as it is executing and without stopping the system.
Stable storage
Developers need a stable error log that will survive a crash. Store data in a manner that survives a system crash.
Asynchronous message passing
Asynchronous message passing should be the default choice for inter-service communication.
Well-behaved programs
A system should be composed of well-behaved programs. Such programs should be isomorphic to the specification. If the specification says something silly, then the program must faithfully reproduce any errors in the specification. If the specification doesn't say what to do, raise an exception!
Avoid guesswork—this is not the time to be creative.
"It is essential for security to be able to isolate mistrusting programs from one another, and to protect the host platform from such programs. Isolation is difficult in object-oriented systems because objects can easily become aliased (i.e., at least two or more objects hold a reference to an object)" -Ciaran Bryce
Tasks cannot directly share objects. The only clean way for tasks to communicate is to use a standard copying communication mechanism.
Wrap up
Applications run on systems and understanding how to properly program systems is a critical skill for developers. Systems include reliability and complexity that are best managed using a series of best practices. Some of these include:
- Processes are units of fault encapsulation.
- Strong isolation leads to autonomy.
- Processes do what they are supposed to do or fail as soon as possible (fail fast).
- Allowing components to crash and then restart leads to a simpler fault model and more reliable code. Failure, and the reason for failure, must be detectable by remote processes.
- Processes share no state, but communicate by message passing.





Comments are closed.