

Today, when best practices for backup and recovery are more important than ever before, it's good to know that high-end fully open source enterprise backup solutions exist for even the largest organizations. Perhaps the most powerful open source solution in its class is Bacula, a highly scalable software for backup, recovery, and data verification. It is a mature yet still significantly developing project used by MSPs, defense organizations, ISVs, and e-commerce companies worldwide and runs on many different Linux flavors. Bacula has a thriving community, and many Linux enthusiasts use it to provide a strong level of data protection.
With the many severe disruptions that ransomware causes today, it's critical that the client system being backed up is never aware of storage targets and has no credentials for accessing them. This is true in Bacula's case, and in addition:
- Storage and Storage Deamon hosts are dedicated systems, strictly secured, allowing only Bacula-related traffic and admin access and nothing else.
- Bacula's "Director" (core management module) is a dedicated system with the same restrictive access.
Bacula has plenty of additional configuration options to tune backups to user needs. It functions in networks and can back up both remote and local hosts. For first-time users, it can look complex, but fortunately, the Bacula Project also provides the Baculum web interface to ease administration. Many Linux users are more than happy to rely on Bacula's command-line interface to exploit its considerable range of capabilities, but sometimes it's good to have an effective GUI, too. That's where the open source Baculum comes in.
Baculum
Baculum's installation process is reasonably simple because its repositories provide binary packages for popular Linux distributions. After installation, you have access to two wizards:
- The Baculum API - a REST API component for working with Bacula data.
- The Baculum Web component - the web interface itself.
The Baculum API is installed on hosts with Bacula components which you manage from the web interface level. Baculum Web is usually one instance that connects all Baculum API hosts and makes it possible to manage all of them. This architecture fits well with the Bacula network architecture because you can manage all Bacula hosts from one interface. It's important to know that the web interface does not store any Bacula-specific configuration from any host but manages them by sending API requests instead. When you modify the interface or run Bacula actions, they are done in real-time. When you click on the save configuration button, the modification is done simultaneously on the targeted hosts.
Below is a sample Bacula and Baculum topology.
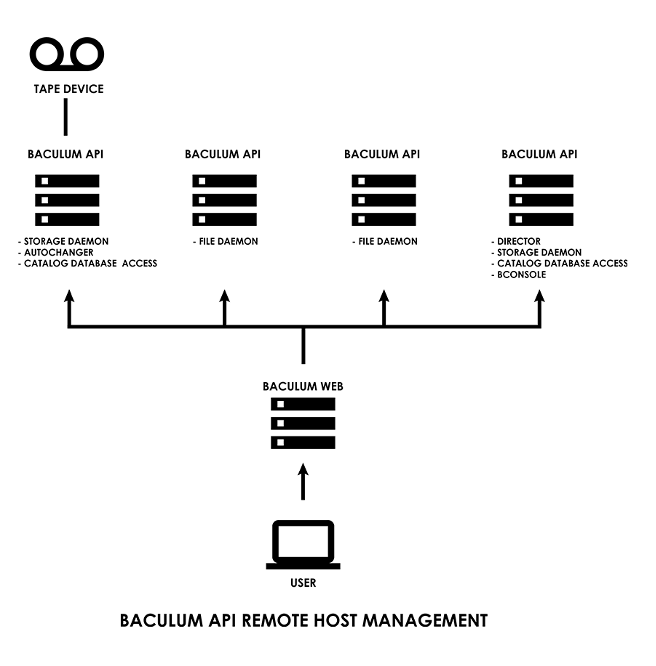
(Rob Morrison, CC BY-SA 4.0)
One disadvantage of this approach is that you need to install one Baculum API instance on each Bacula host that you want to manage. If there are many servers to back up, it is possible to automate the installation process using an application-deployment tool like Ansible.
In my case, I have a much simpler topology with only one host managed by Baculum. My topology looks like the one below.
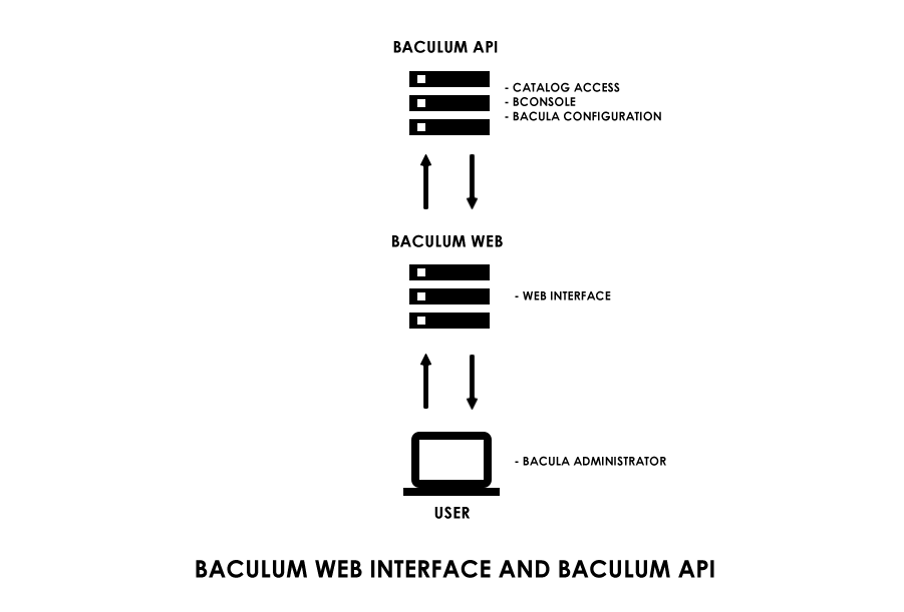
(Rob Morrison, CC BY-SA 4.0)
You can decide what Bacula resources to share on each Baculum API host. You can set the API hosts to do configuration work, access the Bacula catalog database, run Bacula console commands, or any combination.
After installing the web interface in the Bacula environment, you see a dashboard page like this:
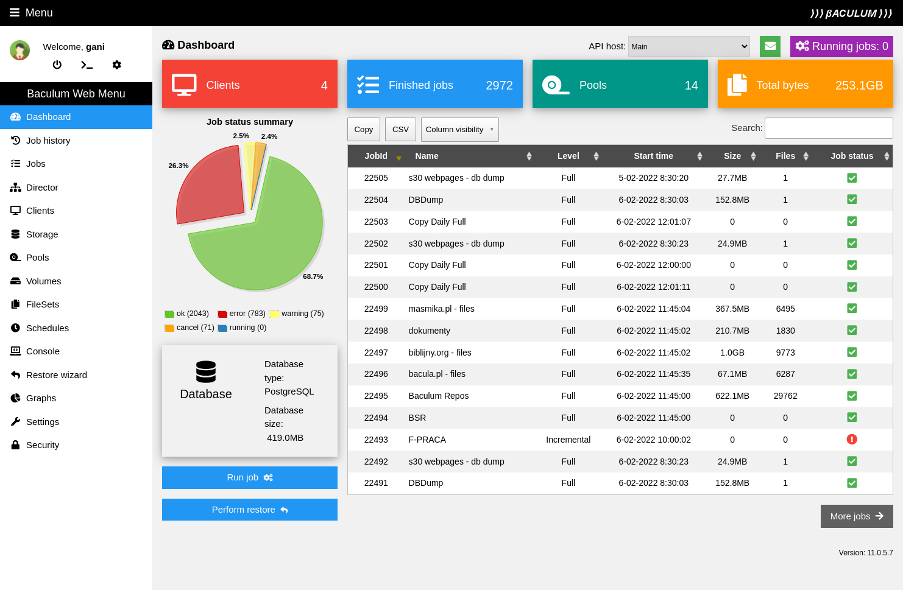
(Rob Morrison, CC BY-SA 4.0)
Create a backup job
To define a new backup job, go to the job page to see some wizards for creating backup, copy, or migrate jobs using a custom job form. For this demonstration, I chose the backup job, which displays the first wizard step:
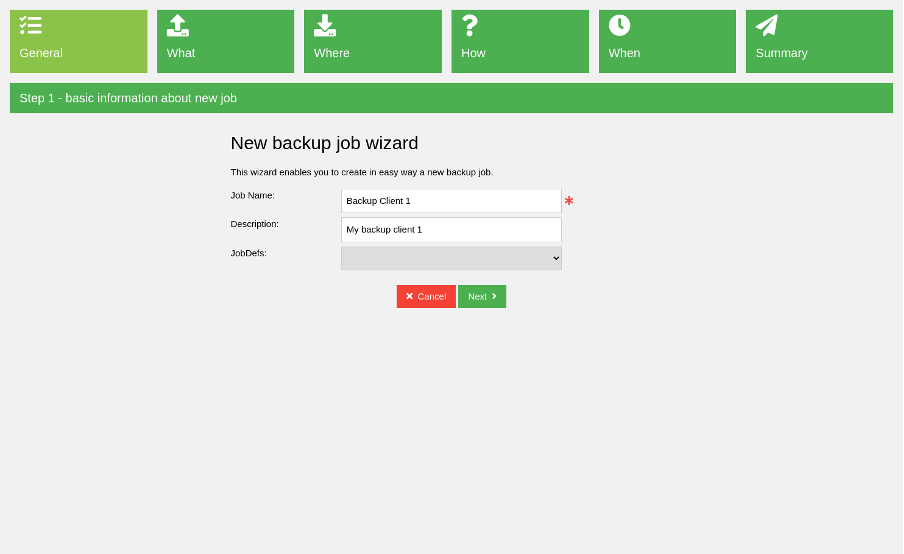
(Rob Morrison, CC BY-SA 4.0)
First, type the new job name and optional description. In the second step, decide what to backup. For this example, I chose a Bacula client and FileSet, which defines the paths to be backed up. Usually, in this window, there aren't any FileSet options to choose from yet, but you can create one with the Add new fileset button in the wizard. To define paths, I decided to browse the client filesystem and select paths in the drag and drop browser, as in the image below.
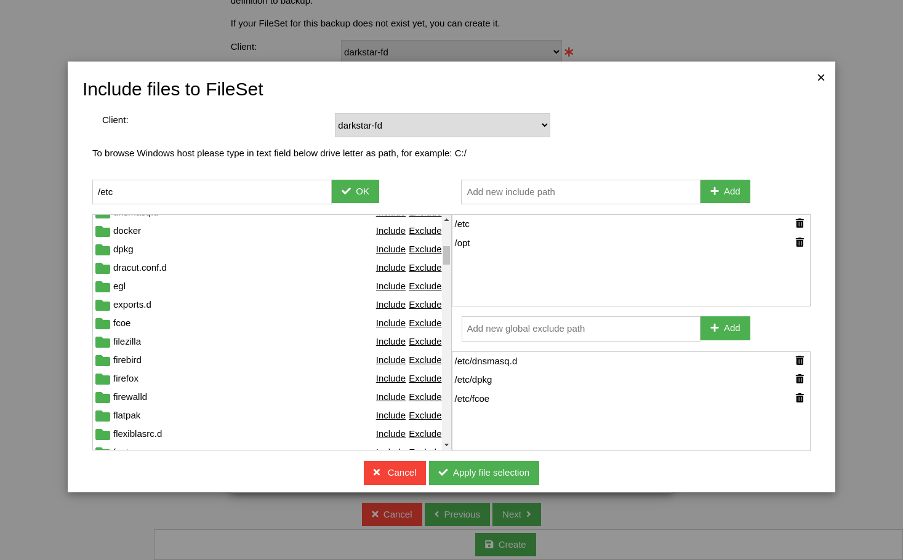
(Rob Morrison, CC BY-SA 4.0)
Once the FileSet is ready, the next step is to select where to save the backed-up data for this job. Select a storage location and a volume pool.
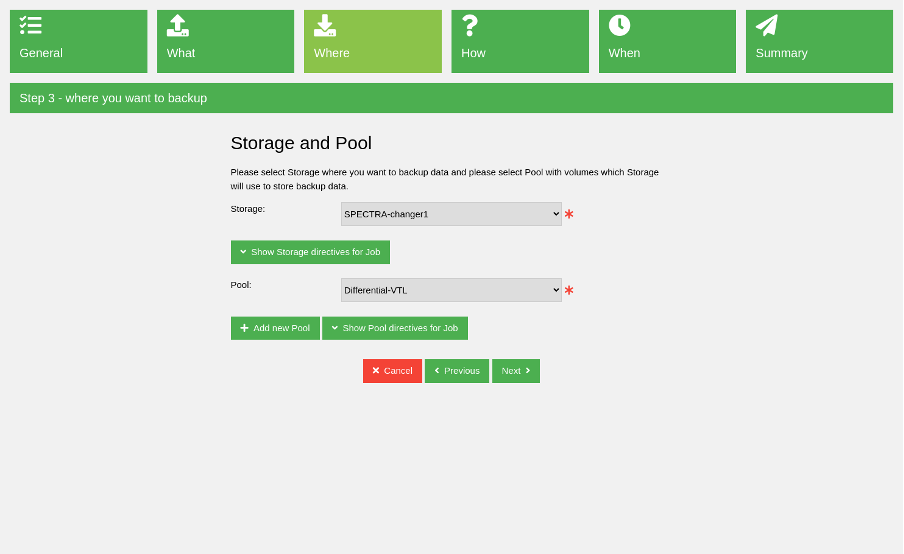
(Rob Morrison, CC BY-SA 4.0)
As with FileSets, you have an option to create a new pool. In this example, I chose an existing volume pool.
In the next step are job-specific options like choosing the job level (full, incremental, differential, etc.), job priority, and a few other settings.
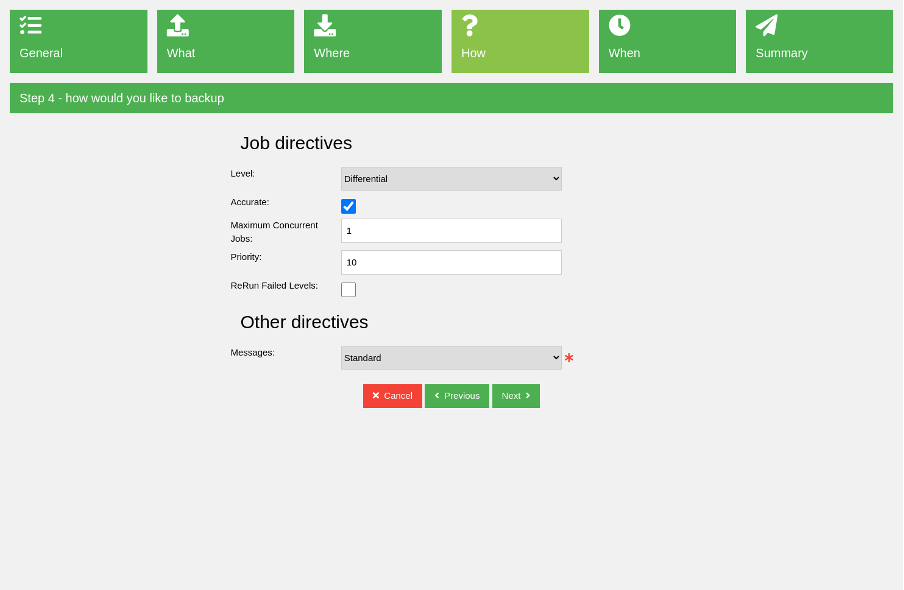
(Rob Morrison, CC BY-SA 4.0)
On the next wizard page, specify when to run this backup job. Backups are usually run periodically, and here you can choose a schedule for this job. If you don't have a schedule, you can create it in this interface:
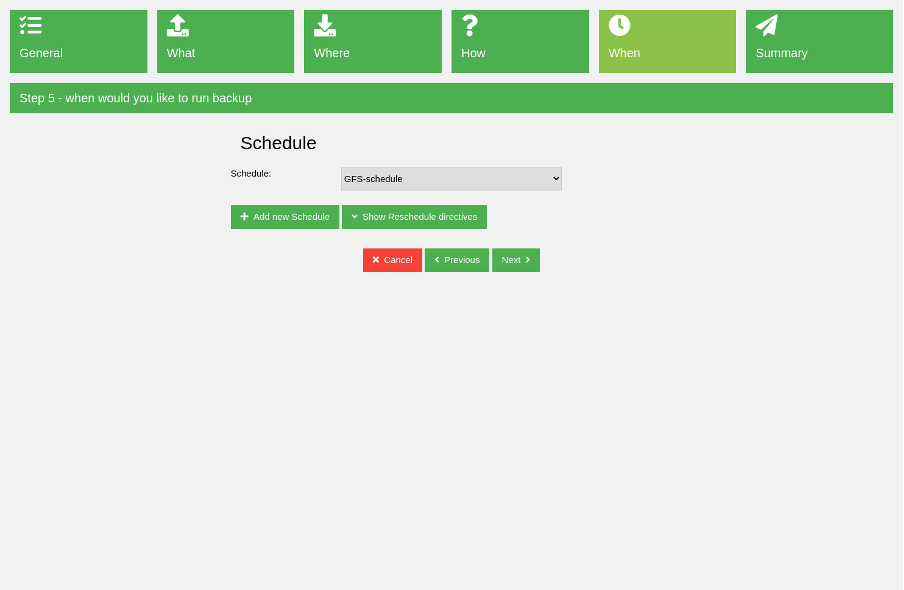
(Rob Morrison, CC BY-SA 4.0)
The last wizard step is just a summary of all values selected in the previous steps.
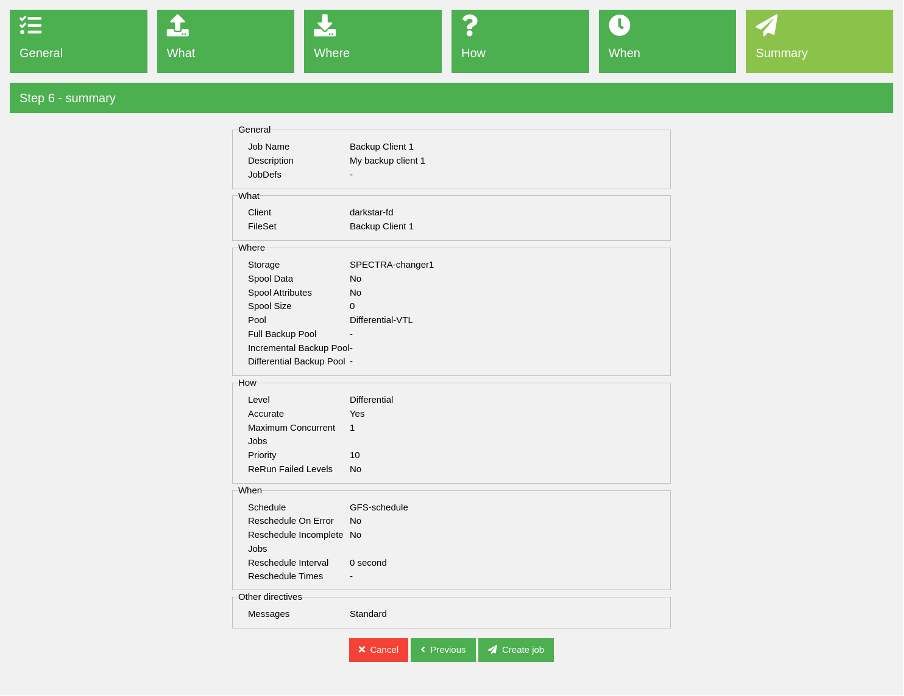
(Rob Morrison, CC BY-SA 4.0)
Review all the values, and if they look correct, create the new job.
Run the backup
OK, you have a new backup job. To run the initial backup, you may choose to start it manually using the Run job button. There is a useful capability in the Run job window to estimate a job before running it. Run this estimation to know in advance how many files and how many bytes will be backed up by this job.
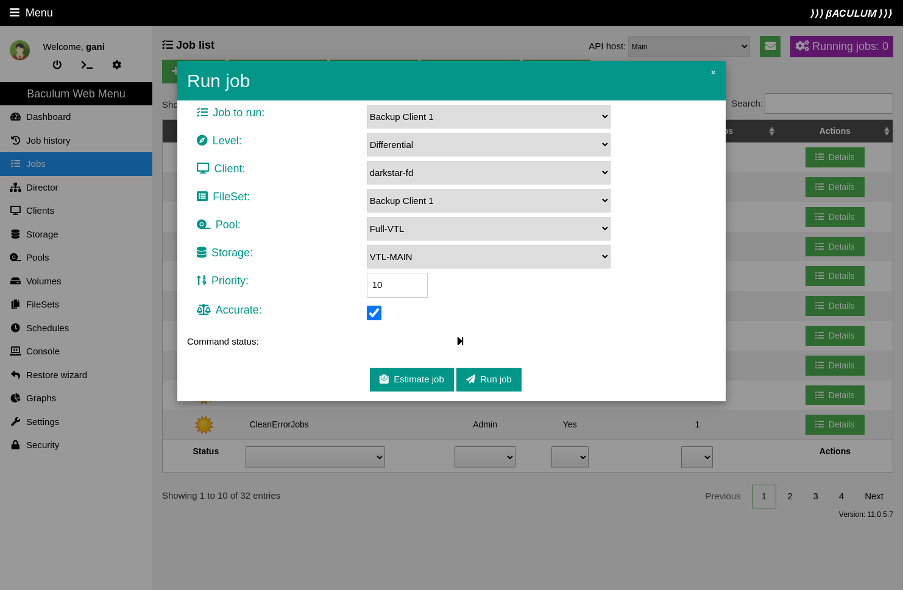
(Rob Morrison, CC BY-SA 4.0)
After running the job, you move to a job view page where you can see backup progress from the client's perspective.
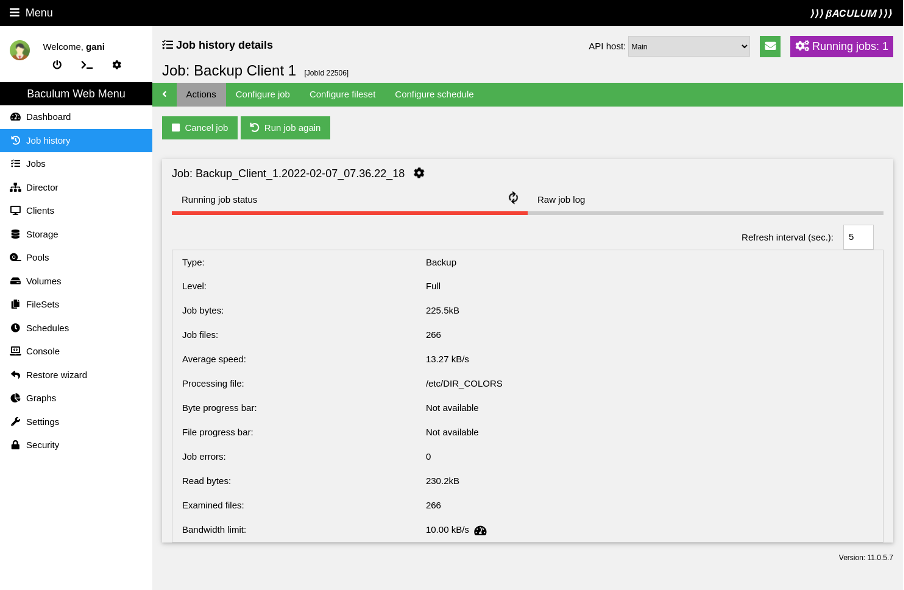
(Rob Morrison, CC BY-SA 4.0)
You can track job status from three places on the interface:
- The Bacula client (shown above).
- The Bacula director component side.
- The storage daemon perspective.
Here you can see the job progress on the director and storage daemon side:
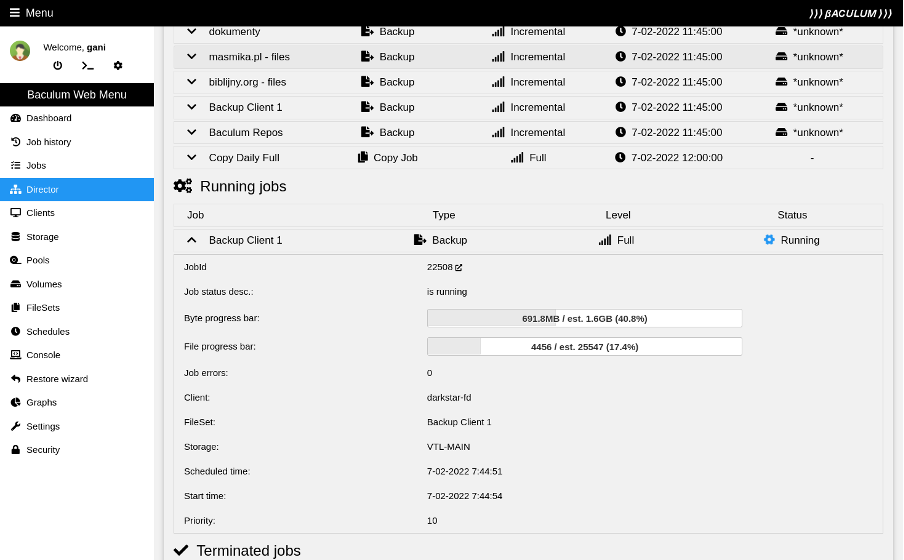
(Rob Morrison, CC BY-SA 4.0)
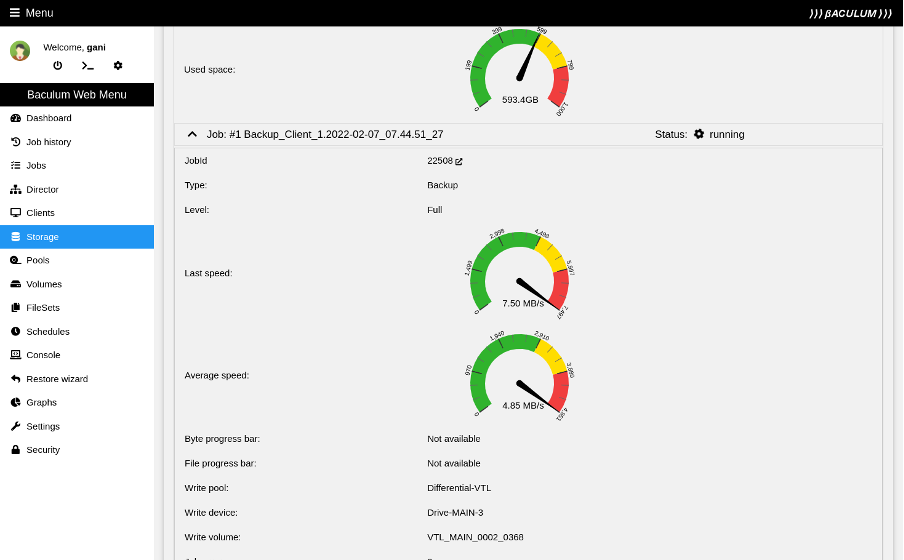
(Rob Morrison, CC BY-SA 4.0)
The backup job completes.
Restore data
Of course, you must be able to restore the backed-up data. Baculum provides a Restore wizard in the primary sidebar menu. After opening it, you see a backup client selection to which you can restore the data.
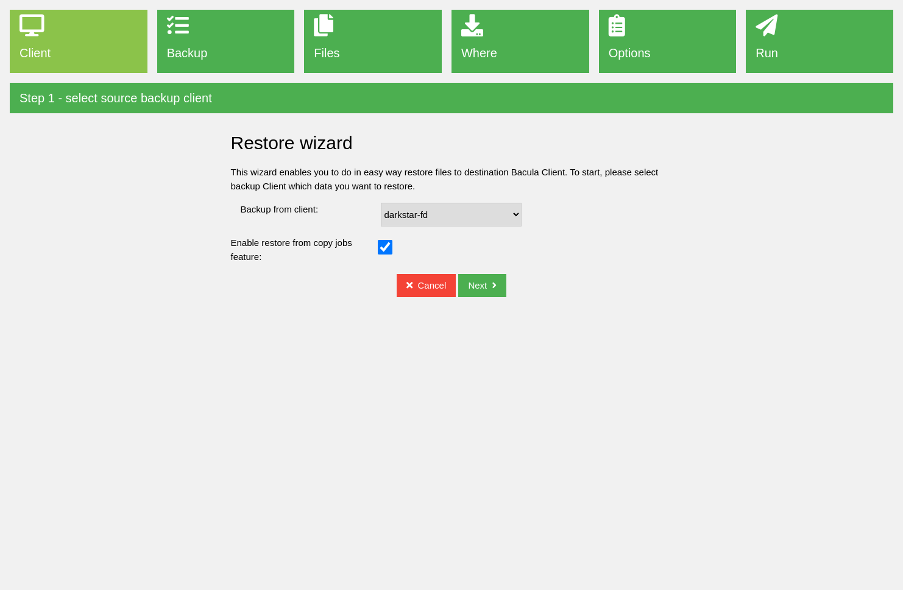
(Rob Morrison, CC BY-SA 4.0)
Select the client and go to the second step. Here you see all backups from that client. Your backup is at the top, so it is easy to choose. However, if you want to find a past backup, search the backups data grid. There is also an option to find a backup by filename, with or without a path.
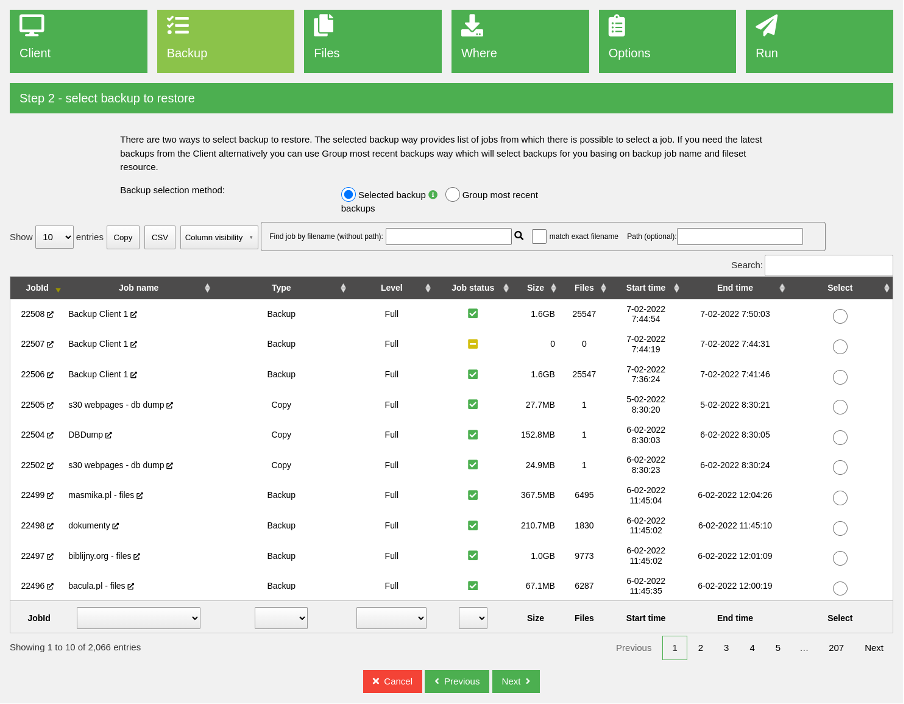
(Rob Morrison, CC BY-SA 4.0)
Select the backup and go to file selection on the third restore wizard step. Here, in the file browser, choose directories and files to restore. The browser also has an area to select a specific file version if it exists in other backups.
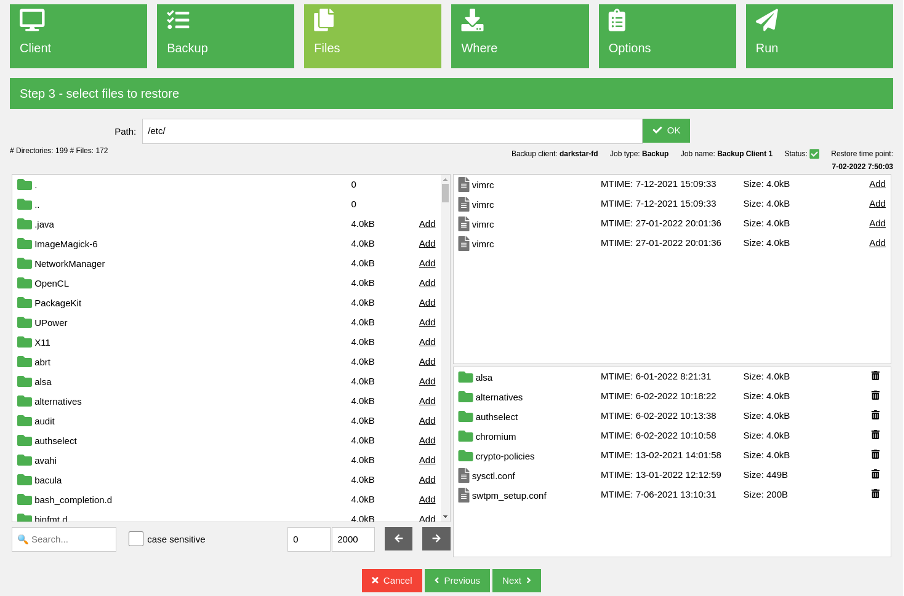
(Rob Morrison, CC BY-SA 4.0)
The next wizard step defines the destination where the restore will save the data. By default, the client from which the backup originates is selected, but you can change that to restore to a different host than the original. You can also define an absolute path on the client to restore the data. The media required to complete this restore is displayed. This is very useful for a backup tape device operator to prepare for the restore job. Personally, I use disk media, and my volumes are available for the storage daemon all the time.
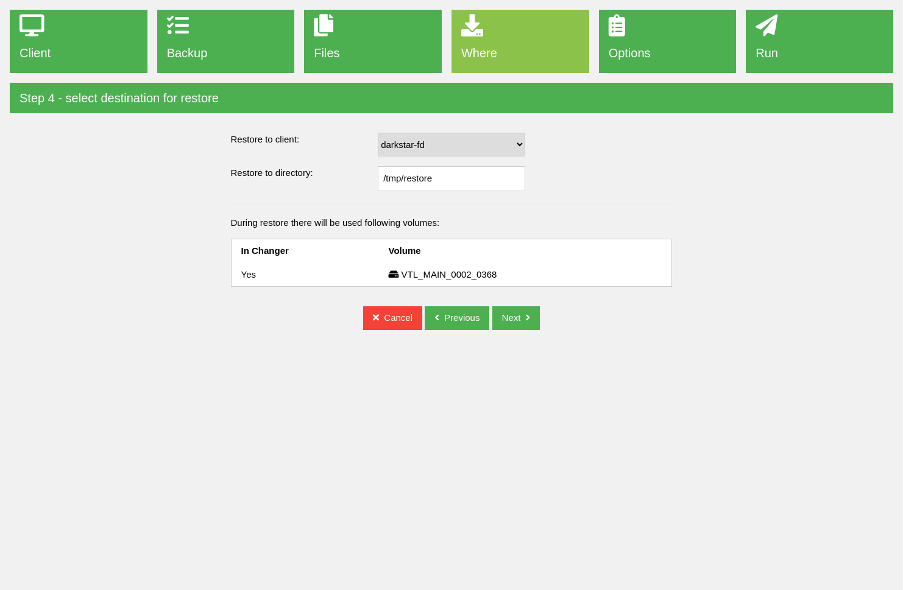
(Rob Morrison, CC BY-SA 4.0)
The next step offers the restore options, such as replacing a policy for existing files on the filesystem or file relocation fields. I keep them untouched and go to the summary step before running the restore.
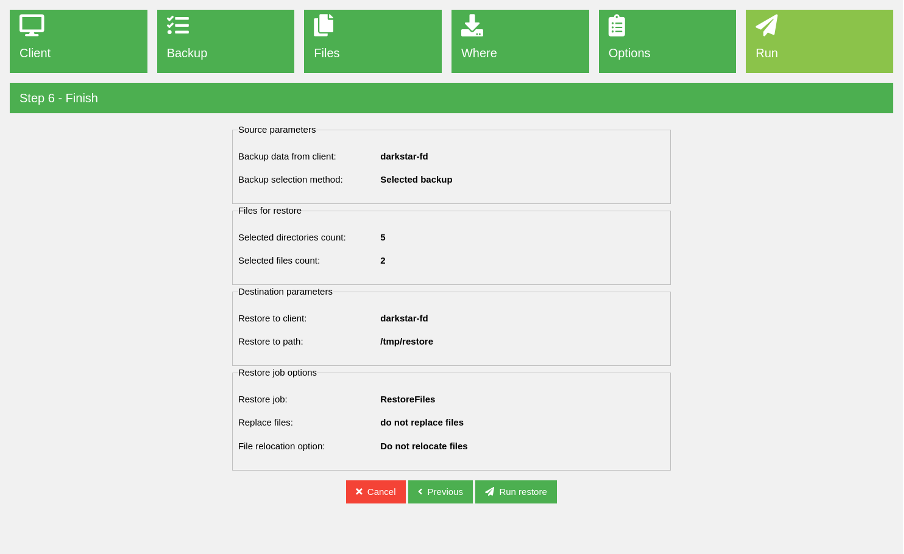
(Rob Morrison, CC BY-SA 4.0)
In the restore job—just like in the backup job—you see the running restore job's progress. After completion, there is a summary of the entire process.
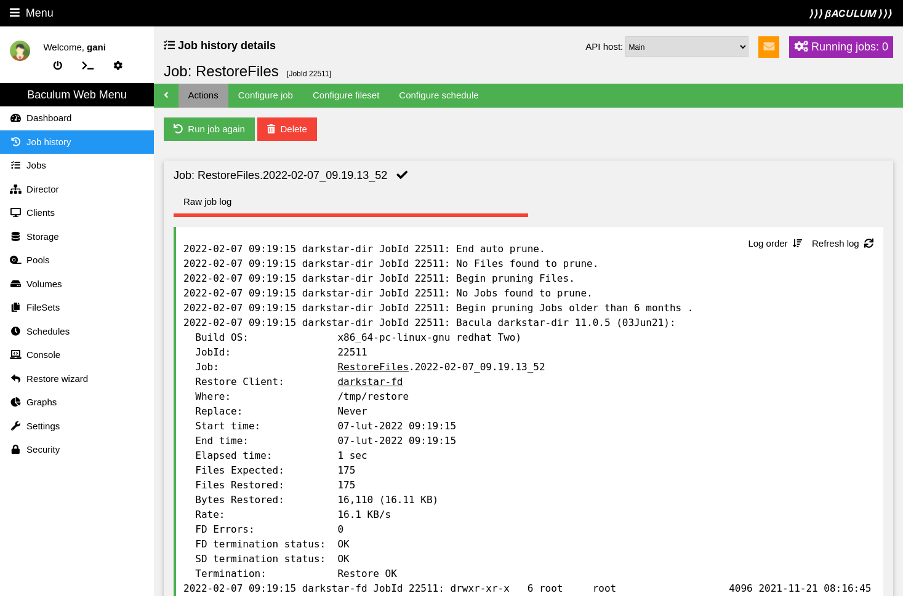
(Rob Morrison, CC BY-SA 4.0)
That's just about it. The backup and a restore are done. The process may be a little simpler with other tools, but Bacula offers Linux enthusiasts hundreds of very useful options. This limits how much you can simplify the interface, and most users of Bacula don't want that.
Copy jobs
Besides doing traditional backup and restore jobs, Bacula also provides a few other job types. One of them is Copy job, which copies backups between storage devices from one pool of volumes to another. One storage device can be a disk, and another can be a tape or tape library. Copy job reads data from file volumes and sends it to tape devices for saving on magnetic tapes. Bacula users can configure a backup D2D2T strategy (disk-to-disk-to-tape). Source and destination storage can be of different types (disk and tape), but it works just as well when copying backup jobs between the same device types.
Baculum has full support for copy jobs, including configuring copy jobs and ending with restoring data directly from copy jobs. Configure a copy job using the copy job wizard visible in the image below.
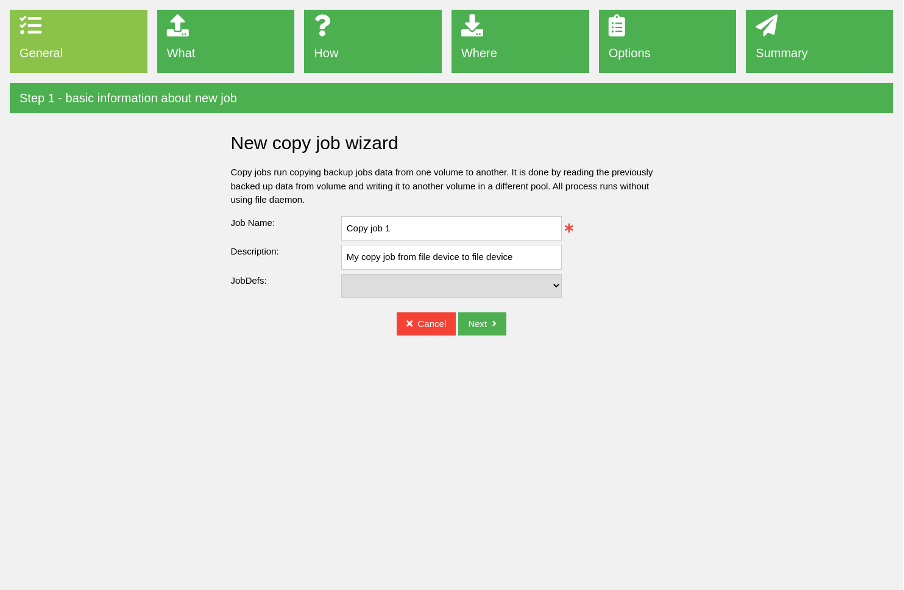
(Rob Morrison, CC BY-SA 4.0)
After typing the new copy job name, choose the source storage and source volume pool. This is the storage that reads data when the copy job runs.
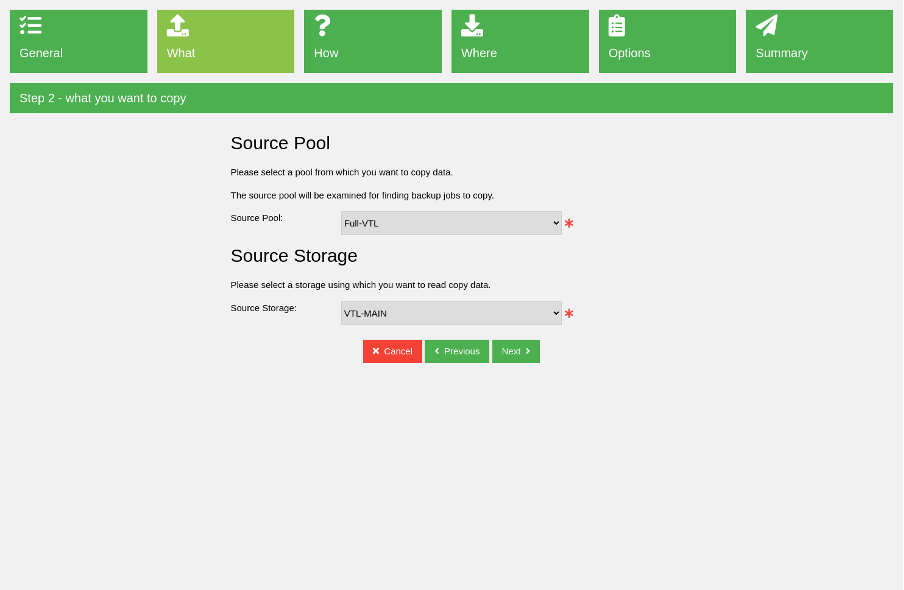
(Rob Morrison, CC BY-SA 4.0)
The third wizard step specifies how to copy jobs. In other words, you can define the selection criteria used for choosing the backups that will be copied. You can select backups by patterns like:
- Job name
- Client
- Volume
- Smallest volume in the pool
- Oldest volume in the pool
- SQL query
- Copy all uncopied jobs so far from the pool
In this example, I chose a selection by job name.
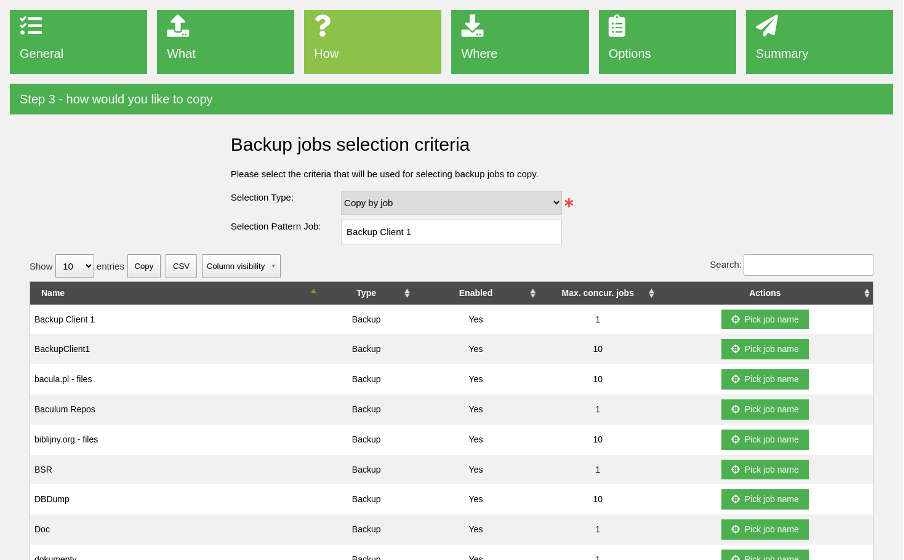
(Rob Morrison, CC BY-SA 4.0)
Select the destination storage and pool in the next step. This storage writes backups to the destination pool when you run the copy job.
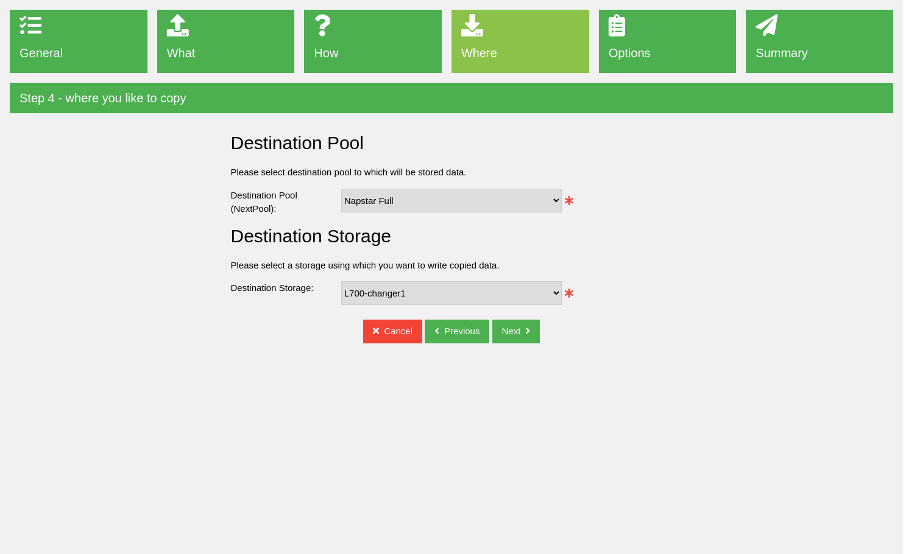
(Rob Morrison, CC BY-SA 4.0)
In the penultimate step are a couple of options, such as the maximum number of spawned jobs. You can also set a schedule to run the copy job periodically.
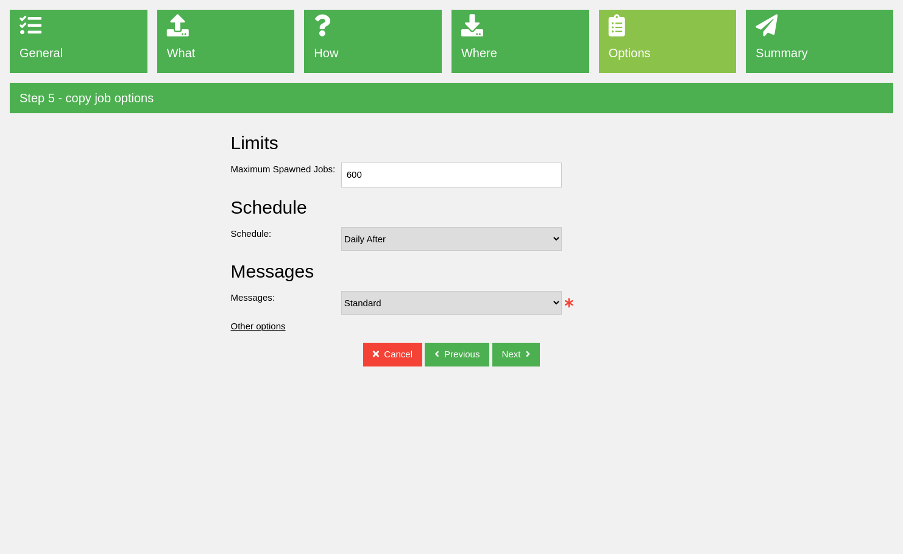
(Rob Morrison, CC BY-SA 4.0)
After saving the wizard, run the copy job in the same place where you started the backup job. You can see the live updated job log output.
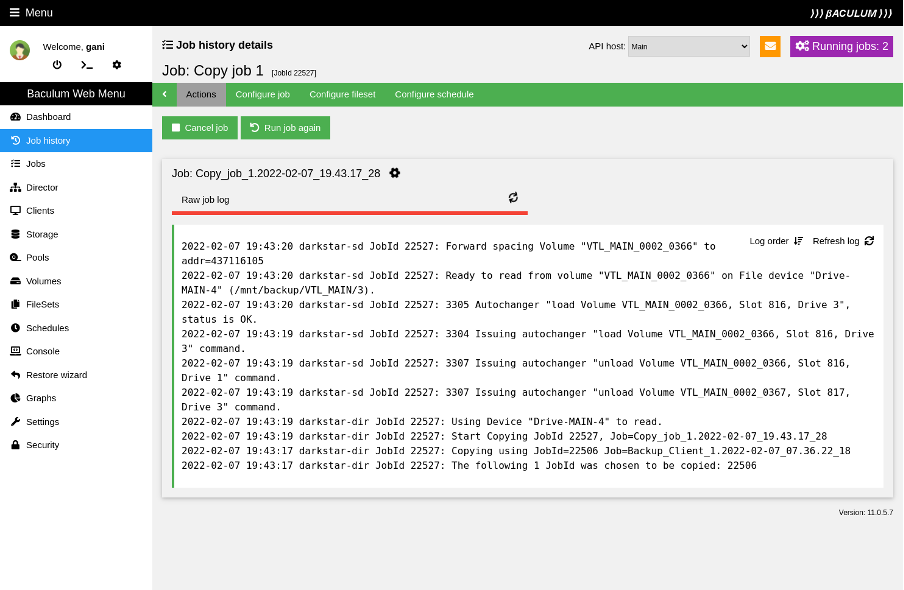
(Rob Morrison, CC BY-SA 4.0)
Wrap up
Done! You have performed a backup job, restored a job, and created a copy job.
There are two Baculum functions that I think many folks will find useful.
First, its simple interface enables the user to administer Bacula from any mobile device. This can be crucial for cases when you are outside the office and somebody from the organization sends a text message like: "Hey! I accidentally deleted an important report file and need it urgently. Are you able to restore it to my computer?" You could do this restore using a mobile phone and the same wizard steps described above.
The second important function is its multi-user interface with several authentication methods (local user, basic authentication, LDAP, etc.). It enables company employees to use Baculum to backup and restore their own resources without requiring access to any other utilities. You can customize the role-based access control interface for each group of users.
Of course, these options are just the tip of the iceberg regarding Bacula's capabilities with Baculum. Baculum really is about being configurable. I hope you can enjoy its benefits and the empowerment it brings you to make your data safer and your life easier!





Comments are closed.