

Distributed systems have unique requirements for the site reliability engineer (SRE). One of the best ways to maintain site reliability is to enforce a certain set of best practices. These act as guidelines for configuring infrastructure and policies.
What is a circuit breaker pattern?
A circuit breaker pattern saves your service from halting or crashing when another service is not responding.
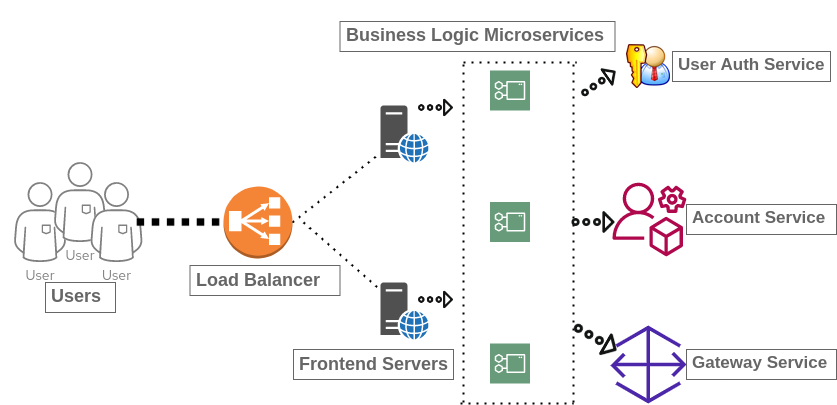
(Robert Kimani, CC BY-SA 40)
For instance, in the example image, the business logic microservices talk to the User Auth service, Account service, and Gateway service.
As you can see, the "engine" of this business application is the business logic microservice. There's a pitfall, though. Suppose the account service breaks. Maybe it runs out of memory, or maybe a back end database goes down. When this happens, the calling microservice starts to have back pressure until it eventually breaks. This results in poor performance of your web services, which causes other components to break. A circuit breaker pattern must be implemented to rescue your distributed systems from this issue.
Implementing a circuit breaker pattern
When a remote service fails, the ideal scenario is for it to fail fast. Instead of bringing down the entire application, run your application with reduced functionality when it loses contact with something it relies upon. For example, keep your application online, but sacrifice the availability of its account service. Making a design like a circuit breaker helps avoids cascading failure.
Here's the recipe for a circuit breaker design:
-
Track the number of failures encountered while calling a remote service.
-
Fail (open the circuit) when a pre-defined count or timeout is reached.
-
Wait for a pre-defined time again and retry connecting to the remote service.
-
Upon successful connection, close the circuit (meaning you can re-establish connectivity to the remote service.) If the service keeps failing, however, restart the counter.
Instead of hanging on to a poorly performing remote service, you fail fast so you can move on with other operations of your application.
Open source circuit breaker pattern
There are very specific components provided by open source to enable circuit breaker logic in your infrastructure. First, use a proxy layer, such as Istio. Istio is a technology independent solution and uses a "Blackbox" approach (meaning that it sits outside your application).
Alternately, you can use Hystrix, an open source library from Netflix that's widely and successfully used by many application teams. Hystrix gets built into your code. It's generally accepted that Hystrix can provide more functionality and features than Istio, but it must be "hard coded" into your application. Whether that matters to your application depends on how you manage your code base and what features you actually require.
Implementing effective load balancing
Load balancing is the process of distributing a set of tasks over a set of resources (computing units), with the aim of making their overall processing as efficient as possible. Load balancing can optimize response time, and avoid unevenly overloading some computer nodes while other computer nodes are left idle.
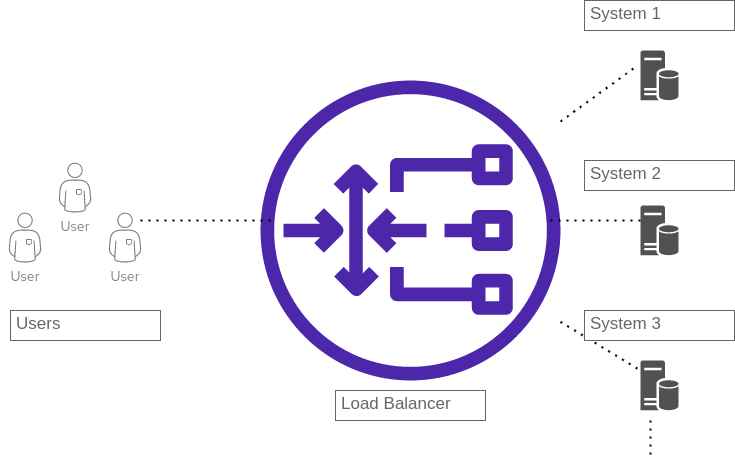
(Robert Kimani, CC BY-SA 40)
Users on the left side talk to a virtual IP (vIP) on a load balancer. The load balancer distributes tasks across a pool of systems. Users are not aware of the back-end system, and only interact with the system through the load balancer.
Load balancing helps to ensure high availability (HA) and good performance. High availability means that failures within the pool of servers can be tolerated, such that your services remain available a high percentage of the time. By adding more servers to your pool, effective performance is increased by horizontally spreading the load (this is called horizontal scaling.)
3 ways to do load balancing
- DNS Load Balancing: This is the most straight forward and is free. You do not have to purchase any specialized hardware because it's the basic functionality of DNS protocol, you'd simply return multiple A-records An A-record maps a hostname to an IP address. When the DNS server returns multiple IP addresses for a single hostname, the client will choose one IP address at random, in other words the load balancing is automatically done for you from the client.
-
Dedicated Hardware-Based Load Balancer: This is what is typically used within a data center, it's feature-rich and highly performant.
-
When you have a Software Load Balancer, you do not need to have a dedicated hardware for this type of load balancing, you can simply install the load balancer software on commodity hardware and use it for your load balancing use cases.
Nginx and HAProxy are mostly used as software load balancers and can be very useful in development environments where you can quickly spin up their functionality.
DNS load balancing
A DNS server may return multiple IP addresses when a client looks up a hostname. This is because in a large-scale deployment, a network target isn't just running on one server or even just on one cluster. Generally, the client software chooses an IP address at random from the addresses returned. It's not easy to control which IP a client chooses.
Unless you have custom software built to determine the health of a server, pure DNS load balancing doesn't know whether a server is up or down, so a client could be sent to a server that is down.
Clients also cache DNS entries by design, and it's not always easy to clear them. Many vendors offer the ability to choose which datacenter a client gets routed to based on geographic location. Ultimately, an important way to influence how clients reach your services is through load balancing.
Dedicated load balancers
Load balancing can happen at Layer3 (Network), Layer4 (Transport), or Layer7 (Application) of the OSI (Open Systems Interconnection) model.
- An L3 load balancer operates on the source and destination IP addresses.
- An L4 load balancer works with IP and port numbers (using the TCP protocol).
- An L7 load balancer operates at the final layer, the application layer, by making use of the entire payload. It makes use of the entire application data, including the HTTP URL, cookies, headers, and so on. It's able to provide rich functionality for routing. For instance, you can send a request to a particular service based on the type of data that's coming in. For example, when a video file is requested, an L7 load balancer can send that request to a streaming appliance.
There are 5 common load balancing methods in use today:
- Round Robin: This is the simplest and most common. The targets in a load balancing pool are rotated in a loop.
- Weighted Round Robin: Like a round robin, but with manually-assigned importance for the back-end targets.
- Least Loaded or Least Connections: Requests are routed based on the load of the targets reported by the target back-end.
- Least Loaded with Slow Start or Least Response Time: Targets are chosen based on its load, and requests are gradually increased over time to prevent flooding the least loaded back-end.
- Utilization Limit: Based on queries per second (QPS), or events per second (EPS), reported by the back-end.
There are software-based load balancers. This can be software running on commodity hardware.You can pick up any Linux box and install HAProxy or Nginx on it. Software load balancers tend to evolve quickly, as software often does, and is relatively inexpensive.
You can also use hardware-based, purpose-built load balancer appliances. These can be expensive, but they may offer unique features for specialized markets.
Transitioning to Canary-based Deployment
In my previous article, I explained how Canary-based deployments help the SRE ensure smooth upgrades and transitions. The exact method you use for a Canary-based rollout depends on your requirements and environment.
Generally, you release changes on one server first, just to see how the deployed package fares. What you are looking for at this point is to ensure that there are no catastrophic failures, for example, a server doesn't come up or the server crashes after it comes up.
Once that one server deployment is successful, you want to proceed to install it in up to 1% of the servers. Again this 1% is a generic guideline but it really depends on the number of servers you have and your environment. You can then proceed to release for early adaptors if it's applicable in your environment.
Finally, once canary testing is complete, you'd want to release for all users at that point.
Keep in mind that a failed canary is a serious issue. Analyze and implement robust testing processes so that issues like this can be caught during testing phase and not during canary testing.
Reliability matters
Reliability is key, so utilize a circuit breaker pattern to fail fast in a distributed system. You can use Hystrix libraries or Istio.
Design load balancing with a mix of DNS and dedicated load balancers, especially if your application is web-scale. DNS load balancing may not be fully reliable, primarily because the DNS servers may not know which back-end servers are healthy or even up and running.
Finally, you must use canary releases, but remember that a canary is a not a replacement for testing.





Comments are closed.