

In my previous article, I wrote about incident management (IM), an important component of site reliability engineering. In this article, I focus on change management (CM). Why is there a need to manage change? Why not simply just have a free-for-all where anyone can make a change at any time?
There are three tenets of effective CM. This gives you a forecast framework for your CM strategy:
- Rolling out changes progressively: There's a difference between progressive rollouts in which you deploy changes in stages, and doing it all at once. You get to find out that even though progressive change may look good on paper,there are pitfalls to avoid.
- Detecting problems with changes: Monitoring is extremely critical for your CM to work. I discuss and look at examples of how to setup effective monitoring to ensure that you can detect problems and make changes as quickly as possible.
- Rollback procedures: How can you effectively rollback when things go wrong?
Why manage change?
It's estimated that 75% of production outages are due to changes. Scheduled and approved changes that we all perform. This number is staggering and only requires you to get on top of CM to ensure that everything is in order before the change is attempted. The primary reason for these staggering numbers is that there are inherent problems with changes.
Infrastructure and platforms are rapidly evolving. Not so long ago, infrastructure was not as complex, and it was easy to manage. For example an organization could have a few servers, where they ran an application server, web-servers, and database servers. But lately the infrastructure and platform are as complex as ever.
It is impossible to analyze every interconnection and dependency after the fact caused by the numerous sub-systems involved. For instance an application owner may not even know a dependency of an external service until it actually breaks. Even if the application team is aware of the dependency, they may not know all of the intricacies and all the different ways the remote service will respond due to their change.
You cannot possibly test for unknown scenarios. This goes back to the complexity of the current infrastructure and platforms. It will be cost prohibitive in terms of the time you spend to test each and every scenario before you actually apply a change. Whenever you make a change in your existing production environment, whether it's a configuration change or a code change, the truth is that, you are at high risk of creating an outage. So how do we handle this problem? Let's take a peek at the three tenets of an effective CM system.
3 tenets of an effective change management system for SREs
Automation is the foundational aspect of effective CM. Automation flows across the entire process of CM. This involves a few things:
- Progressive rollouts: Instead of doing one big change, the progressive rollouts mechanism allows you to implement change in stages, thereby reducing the impact to the user-base if something goes wrong. This attribute is critical especially if your user-base is large, for instance – web-scale companies.
- Monitoring: You need to quickly and accurately detect any issue with changes. Your monitoring system should be able to reveal the current state of your application and service without any considerable lag in time.
- Safe rollback: The CM system should rollback quickly and safely when needed. Do not attempt any change in your environment without having a bulletproof rollback plan.
Role of automation
Many of you are aware of the concept of automation, however a lot of organizations lack automation. To increase the velocity of releases, which is an important part of running an Agile organization, manual operations must be eliminated. This can be accomplished by using Continuous Integration and Continuous Delivery but it is only effective when most of the operations are fully automated. This naturally eliminates human errors due to fatigue and carelessness. By virtue, auto-scaling which is an important function of cloud-based applications requires no manual intervention. This process needs to be completely automated.
Progressive rollouts for SREs: deploying changes progressively
Changes to configuration files and binaries have serious consequences, in other words when you make a change to an existing production system, you are at serious risk of impacting the end-user experience.
For this reason, when you deploy changes progressively instead of all at once you can reduce the impact when things go wrong. If we need to roll back, the effort is generally smaller when the changes are done in a progressive manner. The idea here is, that you would start your change with a smaller set of clients. If you find an issue with the change, you can rollback the change immediately because the size of the impact is small at that point.
There is an exception to the progressive rollout, you can rollout the change globally all at once if it is an emergency fix and it is warranted to do so.
Pitfalls to progressive rollouts
Rollout and rollback can get complex because you are dealing with multiple stages of a release. Lack of required traffic can undermine the effectiveness of a release. Especially if in the initial stages you are targeting a smaller set of clients in your rollout. The danger is that, you may prematurely sign off on a release based on a smaller set of clients. It also releases a pipline where you run one script with multiple stages
Releases can get much longer compared to one single (big) change. In a truly web-scale application that is scattered across the globe, a change can take several days to fully rollout, which can be a problem in some instances.
Documentation is important. Especially when a stage takes a long time and it requires multiple teams to be involved to manage the change. Everything must be documented in detail in case a rollback or a roll forward is warranted.
Due to these pitfalls, it is advised that you take a deeper look into your organization change rollout strategy. While progressive rollout is efficient and recommended, if your application is small enough and does not require frequent changes, a change all at once is the way to go. By doing it all at once, you have a clean way to rollback if there is a need to do so.
High level overview of progressive rollout
Once the code is committed and merged, we start a "Canary release," where canaries are the test subjects. Keep in mind that they are not a replacement for complete automated testing. The name "canary" comes from the early days of mining, when a canary bird was used to detect whether a mine contained poisonous gas before humans entering.
After the test, a small set of clients are used to rollout our changes and see how things go. Once the "canaries" are signed off, go to the next stage, which is the "Early Adaptors release." This is a slightly bigger set of clients you use to do the rollout. Finally, if the "Early Adaptors" are signed off, move to the biggest pack of the bunch: "All users."
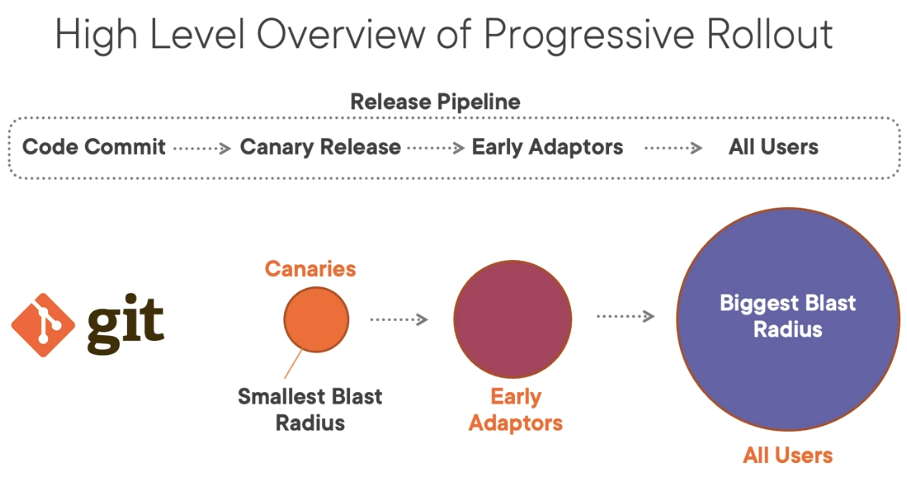
(Robert Kimani, CC BY-SA 4.0)
"Blast radius" refers to the size of the impact if something goes wrong. It is the smallest when we do the canary rollout and actually the biggest when we rollout to all users.
Options for progressive rollouts
A progressive rollout is either dependent on an application or an organization. For global applications, a geography-based method is an option. For instance you can choose to release to the Americas first, followed by Europe and regions of Asia. When your rollout is dependent on departments within an organization, you can use the classic progressive rollout model, used by many web-scale companies. For instance, you could start off with "Canaries", HR, Marketing, and then customers.
It's common to choose internal departments as the first clients for progressive rollouts, and then gradually move on to the external users.
You can also choose a size-based progressive rollout. Suppose you have one-thousand servers running your application. You could start off with 10% in the beginning, then pump up the rollout to 25%, 50%, 75%, and finally 100%. In this way, you can only affect a smaller set of servers as you advance through your progressive rollout.
There are periods where an application must run 2 different versions simultaneously. This is something you cannot avoid in progressive rollout situations.
Binary and configuration packages
There are three major components of a system: binary: (software), data (for instance, a database), and configuration (the parameters that govern the behavior of an application).
It's considered best practice to keep binary and configuration files separate from one another. You want to use version controlled configuration. Your configurations must be "hermetic." At any given time, when the configuration is derived by the application, it's the same regardless of when and where the configurations are derived. This is achieved by treating configuration as code.
Monitoring for SREs
Monitoring is a foundation capability of an SRE organization. You need to know if something is wrong with your application that affects the end-user experience. In addition, your monitoring should help you identify the root cause.
The primary functions of monitoring are:
- Provides visibility into service health.
- Allows you to create alerts based on a custom threshold.
- Analyzes trends and plan capacity.
- Provides detailed insight into various subsystems that make up your application or service.
- Provides Code-level metrics to understand behavior.
- Makes use of visualization and reports.
Data Sources for Monitoring
You can monitor several aspects of your environment. These include:
- Raw logs: Generally unstructured generated from your application or a server or network devices.
- Structured event logs: Easy to consume information. For example Windows Event Viewer logs.
- Metrics: A numeric measurement of a component.
- Distributed tracing: Trace events are generally either created automatically by frameworks, such as open telemetry, or manually using your own code.
- Event introspection: Helps to examine properties at runtime at a detailed level.
When choosing a monitoring tool for your SRE organization, you must consider what's most important.
Speed
How fast can you retrieve and send data into the monitoring system?
- How fresh the data should be? The fresher the data, the better. You don't want to be looking at data that's 2 hours old. You want the data to be as real-time as possible.
- Ingesting data and alerting of real-time data can be expensive. You may have to invest in a platform like Splunk or InfluxDB or ElasticSearch to fully implement this.
- Consider your service level objective (SLO) – to determine how fast the monitoring system should be. For instance, if your SLO is 2 hours, you do not have to invest in systems that process machine data in real-time.
- Querying vast amounts of data can be inefficient. You may have to invest in enterprise platforms if you need very fast retrieval of data.
Resolution check
What is the granularity of the monitoring data?
- Do you really need to record data every second? The recommended way is to use aggregation wherever possible.
- Use sampling if it makes sense for your data.
- Metrics are suited for high-resolution monitoring instead of raw log files.
Alerting
What alert capabilities can the monitoring tool provide?
Ensure the monitoring system can be integrated with other event processing tools or third party tools. For instance, can your monitoring system page someone in case of emergency? Can your monitoring system integrate with a ticketing system?
You should also classify the alerts with different severity levels. You may want to choose a severity level of three for a slow application versus a severity level of one for an application that is not available. Make sure the alerts can be easily suppressed to avoid alert flooding. Email or page flooding can be very distracting to the On-Call experience. There must be an efficient way to suppress the alerts.
[ Read next: 7 top Site Reliability Engineer (SRE) job interview questions ]
User interface check
How versatile is it?
- Does your monitoring tool provide feature-rich visualization tools?
- Can it show time series data as well as custom charts effectively?
- Can it be easily shared? This is important because you may want to share what you found not only with other team members but you may have to share certain information with leadership.
- Can it be managed using code? You don't want to be a full-time monitoring administrator. You need to be able to manage your monitoring system through code.
Metrics
Metrics may not be efficient in identifying the root cause of a problem. It can tell what's going on in the system, but it can't tell you why it's happening. They are suitable for low-cardinality data, when you do not have millions of unique values in your data.
- Numerical measurement of a property.
- A counter accompanied by attributes.
- Efficient to ingest.
- Efficient to query.
- It may not be efficient in identifying the root cause. Metrics can tell what's going on in the system but it won't be able to tell you why that's happening.
- Suitable for low-cardinality data – When you do not have millions of unique values in your data.
Logs
Raw text data is usually arbitrary text filled with debug data. Parsing is generally required to get at the data. Data retrieval and recall is slower than using metrics. Raw text data is useful to determine the root causes of many problems and there are no strict requirements in terms of the cardinaltiy of data.
- Arbitrary text, usually filled with debug data.
- Generally parsing is required.
- Generally slower than metrics, both to ingest and to retrieve.
- Most of the times you will need raw logs to determine the root cause.
- No strict requirements in-terms of cardinality of data.
You should use metrics because they can be assimilated, indexed and retrieved at a fast pace compared to logs. Analyzing with metrics and logs are fast, so you can give an alert fast. In contrast, logs are actually required for root cause analysis (RCA).
4 signals to monitor
There's a lot you can monitor, and at some point you have to decide what's important.
- Latency: What are the end-users experiencing when it comes to responsiveness from your application.
- Errors: This can be both Hard errors such as an HTTP:500 internal server error or Soft errors, which could refer to a functionality error. It could also mean a slow response time of a particular component within your application.
- Traffic: Refers to the total number of requests coming in.
- Saturation: Generally occurs in a component or a resource when it cannot handle the load anymore.
Monitoring resources
Data has to be derived from somewhere. Here are common resources used in building a monitoring system:
- CPU: In some cases CPU utilization can indicate an underlying problem.
- Memory: Application and System memory. Application memory could be the Java heap size in a Java application.
- Disk I/O: Many applications are heavy I/O dependent, so it's important to monitor disk performance.
- Disk volume: Monitors the sizes of all your file-systems.
- Network bandwidth: It's critical to monitor the network bandwidth utilized by your application. This can provide insight into eliminating performance bottlenecks.
3 best practices for monitoring for SREs
Above all else, remember the three best practices for an effective monitoring system in your SRE organization:
- Configuration as code: Makes it easy to deploy monitoring to new environments.
- Unified dashboards: Converge to a unified pattern that enables reuse of the dashboards.
- Consistency: Whatever monitoring tool you use, the components that you create within the monitoring tool should follow a consistent naming convention.
Rolling back changes
To minimize user impact when change did not go as expected, you should buy time to fix bugs. With fine-grained rollback, you are able to rollback only a portion of your change that was impacted, thus minimizing overall user impact.
If things don't go well during your "canary" release, you may want to roll back your changes. When combined with progressive rollouts, it's possible to completely eliminate user impact when you have a solid rollback mechanism in place.
Rollback fast and rollback often. Your rollback process will become bulletproof over time!
Mechanics of rollback
Automation is key. You need to have scripts and processes in place before you attempt a rollback. One of the ways application developers rollback a change is to simply toggle flags as part of the configuration. A new feature in your application can be turned on and off based on simply switching a flag.
The entire rollback could be a configuration file release. In general, a rollback of the entire release is more preferred than a partial rollback. Use a package management system with version numbers and labels that are clearly documented.
A rollback is still a change, technically speaking. You have already made a change and you are reverting it back. Most cases entail a scenario that was not tested before so you have to be cautious when it comes to rollbacks.
Roll forward
With roll forward, instead of rolling back your changes, you release a quick fix "Hot Fix," an upgraded software that includes the fixes. Rolling forward may not always be possible. You might have to run the system in degraded status until an upgrade is available so the "roll forward is fully complete." In some cases, rolling forward may be safer than a rollback, especially when the change involves multiple sub-systems.
Change is good
Automation is key. Your builds, tests, and releases should all be automated.
Use "canaries" for catching issues early, but remember that "canaries" are not a replacement for automated testing.
Monitoring should be designed to meet your service level objectives. Choose your monitoring tools carefully. You may have to deploy more than one monitoring system.
Finally, there are three tenets of an effective CM system:
- Progressive rollout: Strive to do your changes in a progressive manner.
- Monitoring: A foundational capability for your SRE teams.
- Safe and fast rollbacks: Do this with processes and automation in place which increase confidence in your SRE organization functionality.
In the next article, the third part of this series, I will cover some important technical topics when it comes to SRE best practices. These topics will include the Circuit Breaker Pattern, self healing systems, distributed consensus, effective load balancing, autoscaling, and effective health check.







Comments are closed.