

Varnish Cache is widely used to cache web content to maximize web performance and reduce origin-server load. At our core, we've been all about web caching to support performance, scalability, stability, and all the inherent benefits that come with these attributes—from better user experiences to bottom-line savings. But sometimes we still have to hammer home the importance of caching. And sometimes that means explaining how to use Varnish Cache and get out all the bells and whistles that make it a unique, "lifesaving" (at least for websites and applications), and cool technology.
The nitty-gritty "weirdness" of Varnish Cache
Varnish Cache is an HTTP server with an HTTP backend that can serve files. It has a threaded architecture, but no event loop. Because the write code can use blocking system calls, it's easier to use than Apache or NGINX, where you have to deal with an event loop.
Varnish Cache has a weird way of logging to shared memory, not disk. It's designed this way because logging 10,000 HTTP transactions per second to rotating hard drives is very expensive.
Varnish logs everything—approximately 200 lines per request—to memory. If no one is looking for that information, it gets overwritten. Varnish is the only application that does that.
Flexibility: Help yourself to some VCL
The big differentiator for Varnish Cache is its configuration language. Varnish Configuration Language (VCL) was created 10 years ago to support Varnish Cache 1.0. Unlike Apache or other programs, Varnish Cache does not have a traditional configuration. Instead, it has a set of policies written in this specific language. These policies are compiled into native (binary) code, and the native code is loaded and then run.
Varnish Cache architect Poul-Henning Kamp says VCL was built as a box with a set of tools that can be used as needed, not a fixed product that fits nicely in a box. Today, VCL has 100 modules available that are simple to use. In fact, our Varnish Summits always include a workshop that teaches people to write modules.
We hear time and again that VCL is one of the big reasons people love and even grow to be fiercely protective of Varnish Cache. Its flexibility opens the door to do virtually anything someone wants, throwing traditional program constraints out the window.
So what are the major tools in the VCL toolbox, and how can they be best put to use?
Purging
Varnish doesn't support content purging out of the box. You can't just download, install, and purge right away—some assembly is required. Instead of shipping this code with a default configuration, Varnish Cache requires that its users get some dirt under their fingernails. However, the configuration to set up purging is simple, and you can get exactly what you want from it.
sub vcl_recv {
if (req.method == "PURGE") {
return (purge); } }If you don't want anyone out on the Internet to purge content from your cache, we set up an ACL limit access to purging to this specific thing:
acl purge {
"localhost";
"192.168.55.0"/24;
}
sub vcl_recv {
if (req.method == "PURGE") {
if (!client.ip ~ purge) {
return(synth(405,"Not allowed."));
}
return (purge); } }Adding a "feature" to Varnish Cache: Throttling hot linking
The Varnish framework allows every user to implement the features they need for themselves. The first contributed feature is to use VCL to limit hot linking. Hot linking is stealing someone else's resources on the web, writing a brief post on it, then using their images to illustrate your point so that they end up paying the bandwidth bill.
Varnish allows servers to block this process when hot linking is unlawfully using their resources. For example, Varnish can cap the number of times per minute this can happen by leveraging a VMOD (Varnish module)—vsthrottle—to add throttling.
The user simply imports and loads the throttling module. The VCL snippet below shows a way to limit hot linking. In this example we apply three rules. The first rule checks whether the requested URL starts with "/assets/." The second and third rule protect your assets from hot linking. This is done by checking whether the referrer is other than what you expect, and whether other domains have requested your assets more than 10 times within 60 seconds. That's the throttle function. The URL is used as the key for throttling. The permit equals 10 times per 60 seconds. We are allowed to serve the URL under assets that don't have this as their refer, and if that hits we just throw error 403 with hot linking prohibited. Throttling can also expand to use memcache instead, so that the user gets the central accounting in its cluster.
import vsthrottle;
(..)
if (req.url ~
"^/assets/" &&
(req.http.referer !~
"^https://www.example.com/") &&
vsthrottle.is_denied(req.url, 10, 60s) {
return(error(403,"Hotlinking prohibited");
}Dealing with cookies
Varnish will not cache content requested with cookies. Nor will it deliver a cache hit if the request has a cookie associated with it. Instead, the VMOD is used to strip the cookie. Real men and women will use the regular expression to filter out the cookies. For the rest of us, Varnish offers a cookie module that looks like this:
import cookie;
sub vcl_recv {
cookie.parse ("cookie1: value1; cookie2: value2");
cookie.filter_except("cookie1");
// get_string() will now yield
// "cookie1: cookie2: value2;"; }Varnish doesn't like the set cookie header either. If it sees the backend is sending a set cookie header, it will not cache that object. The solution is to remove the set cookie header or to fix the backend.
- Set-Cookie headers deactivate cookies.
- Solution: Remove Set-Cookie or fix the backend.
Grace Mode: Keeping the thundering herd at bay
Grace Mode allows Varnish to serve outdated content if new content isn't available. It improves performance by asynchronously refreshing content from the backend.
When Varnish 1.0 was first introduced as the caching solution for the online branch of the Norwegian tabloid newspaper Verdens Gang, there were massive problems with threading pileups. The newspaper front page was delivered 3,000 times/second, but its content management system (CMS) was slow and took three seconds to regenerate the front page.
At some sites, if you follow the RFCs, the proxy cache will invalidate that front page or it will time out. Then a user comes along and a new version of the front page needs to be fetched. Varnish does this with cache coalescing. As new users come along, they are placed on a waiting list. (Other caches send users to the backend, which kills the backend.)
If 3,000 more users are being added to the waiting list every second, after three seconds, 9,000 users are waiting for the backend to deliver the content. Initially, Varnish would take that piece of content, talk to its 9,000 threads, and try to push it out all at once. We called this scenario a thundering herd, and it instantly killed the server.
To solve this problem, Varnish decided to simply use the old front page instead of waiting for the server to regenerate the content. Unless you're serving up real-time financial information, no one cares if content is 20 seconds out of date.
The semantics of Grace have changed slightly over the years. In Varnish 4.0 (if enabled) it looks like this:
sub vcl_backend_response {
set beresp.grace = 2m;
}Grace is set on the backend response object. If set to two minutes, Varnish will keep an object two minutes past its TPL. If it is requested in that time, it will prefer to serve something that is in cache over something out of cache. It will use the object, then asynchronously refresh the object.
Opening the hood
Varnish Cache doesn't require users to read source code, but instead provides a default VCL where they can try to put as much of the semantics as they can. With a feature like Grace users can read the VCL and see what it does.
Insert code
sub vcl_hit {
if (obj.ttl >= 0s) {
// A pure unadulterated hit, deliver it
return (deliver);
}
if (obj.ttl + obj.grace > 0s) {
// Object is in grace, deliver it
// Automatically triggers a background fetch
return (deliver);
}
// fetch & deliver once we get the result
return (fetch);
}If the object VCL is more than zero seconds, it has a positive TTL. Return and deliver. Serve it.
If TTL and Grace is more than zero seconds, it is in Grace and Varnish will deliver it.
If TTL and Grace is less than zero seconds, we block and fetch it.
Modifying Grace semantics
Organizations that are scaling with financial instruments and reluctant to serve something that is out of date might want to modify Grace semantics. The first bit here is unchanged. The second part is rewritten if the backend is not healthy and TTL and Grace more than zero seconds do deliver.
sub vcl_hit { if (obj.ttl >= 0s) {
// A pure unadulterated hit, deliver it
return (deliver);
}
if (!std.healthy(req.backend_hint) &&
(obj.ttl + obj.grace > 0s)) {
return (deliver);
}
// fetch & deliver once we get the result
return (fetch);
}A couple of things you might wonder about:
- beresp is the backend request object.
- req is the request object. Use in vcl_recv.
- bereq is the backend request object. Use in vcl_backed_fetch.
- beresp is the backend response. Use in vcl_backend_response.
- resp is the response object. Use in vcl_deliver.
- obj is the original object in memory. Use in vcl_hit.
- man(7) vcl for details.
The state machine
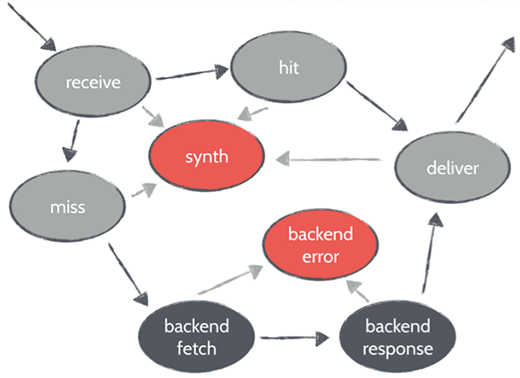
Every request goes through states. Custom code is run at each use to modify request objects. After user-specific code is run, Varnish will decide if it is a hit or a miss and then run VCL hit or VCL miss. If it's a hit, VCL delivers. A miss goes to backend fetch. 90% of user-specific changes happen here.
Quick guide to tuning on Linux
Tunables in Linux are very conservatively set. The two that we find most annoying are SOMAXCONN and TCP_MAX_SYN_Backlog.
When we listen to socket, Varnish will take a couple seconds to listen to the call. If those threads get busy, the kernel will start to queue up. That queue is not allowed to grow beyond SOMAXCONN. Varnish will ask for 1024 connection in the listen depth queue, but the kernel overrides that and you get 928. Because Varnish runs with root privileges it should be able to decide its own listen depth, but Linux knows best.
Users may want to increase that limit if they want to reduce the risk of rejecting connections when out of listen depth. They have to decide if it is better to fail and deliver an error page to the user.
TCP_MAX_SYN_Backlog defines how many outstanding connections can be within the three-way handshake before the kernel assumes that it is being attacked. The default is 128. However, if a flash mob forms on the Internet and goes to your site, you might have more than 128 new TCP connections per second.
Don't mess with tcp_tw_recycle. Take care when Googling these things. There are a lot of demons associated with them.
Work spaces in Linux
In Varnish, local memory is in each thread. Because rollback is expensive, we don't roll back every time we need a bit of memory. Instead, we pre-allocate memory to each thread if a user has a lot of VCL manipulating strings back and forth that will burn up all the workspace.
Varnish does not do connection tracking; the contract module is dead slow. The default is to run with five threads. It's relatively quick to spin up new threads, but if planning on doing 1,000 connections per second = 1,000 threads, then you have the parameter for pre-allocating threads.
To recap:
- Be aware of workspaces.
- Don't do connection tracking.
- Up the threads to one req/sec per thread.
The weird-cool balance of Varnish Cache
The powerful flexibility and benefits of Varnish Cache don't come prepackaged in a square box (which may strike some as weird), and in that way it might not be the right solution for everyone. Its flexibility, though, can be game-changing when looking for ways to customize and control web performance and scalability.




Comments are closed.