

Observability is the ability to know and interpret the current state of a deployment, and a way to know when something is amiss. With cloud deployments of applications as microservices on Kubernetes and OpenShift growing, observability is getting a lot of attention. Many applications come with strict guarantees, such as service level agreements (SLA) for downtimes, latency, and throughput, so network-level observability is a highly imperative feature. Network-level observability is provided by several orchestrators, either natively or by using plugins and operators.
Recently, eBPF (extended Berkeley Packet Filter) emerged as a popular option to implement observability at the end-hosts kernel, due to performance and flexibility. This method enables custom programs to be hooked at certain points along the network data path (for instance, a socket, TC, and XDP). Several open source eBPF-based plugins and operators have been released, and each can be plugged into end-host nodes to provide network observability through your cloud orchestrator.
Existing Observability Tools
The core component of an observability module is how it non-invasively collects the necessary data. To that end, using instrumented code and measurements, we've studied how the design of the eBPF datapath affects performance of an observability module, and the workloads it's monitoring. The artifacts of our measurements are open source and available in our research Git repo. We're also able to provide some useful insights you can use when designing a scalable and high-performance eBPF monitoring data path.
Here are existing open source tools available to achieve observability in the context of both the network and the host:
Skydive
Skydive is a network topology and flow analyzer. It attaches probes to nodes to collect flow-level information. The probes are attached using PCAP, AF_Packet, Open vSwitch, and so on. Instead of capturing the entire packet, Skydive uses eBPF to capture the flow metrics. The eBPF implementation, attached to the socket hook-point, uses a hash map to store flow headers and metrics (packets, bytes, and direction.)
libebpfflow
Libebpfflow is a network visibility library using eBPF to provide network visibility. It hooks on to various points in a host stack, like kernel probes (inet_csk_accept, tcp_retransmit_skb) and tracepoints (net:netif_receive_skb, net:net_dev_queue) to analyze TCP/UDP traffic states, RTT, and more. In addition, it provides process, and the container mapping for the traffic it analyzes. Its eBPF implementation uses perf event buffer to notify TCP state change events to userspace. For UDP, it attaches to the tracepoint of the network device queue and uses a combination of LRU hash map and perf event buffer to store UDP flow metrics.
eBPF Exporter
Cloudflare's eBPF Exporter provides APIs for plugging in custom eBPF code to record custom metrics of interest. It requires the entire eBPF C code (along with the hook point) to be appended to a YAML file for deployment.
Pixie
Pixie uses bpftrace to trace syscalls. It uses TCP/UDP state messages to collect the necessary information, which is then sent to Pixie Edge Module (PEM). In the PEM, the data is parsed according to the detected protocol and stored for querying.
Inspektor
Inspektor is a collection of tools for Kubernetes cluster debugging. It aids the mapping of low-level kernel primitives with Kubernetes resources. It's added as a daemonset on each node of the cluster to collect traces using eBPF for events such as syscalls. These events are written to the perf ring buffer. Finally, the ring buffer is consumed retrospectively when a fault occurs (for example, upon a pod crash).
L3AF
L3AF provides a set of eBPF packages that can be packaged and chained together using tail-calls. It provides a network observability tool, which mirrors traffic based on the flow-id to the user-space agent. Additionally, it also provides an IPFIX flow exporter by storing flow records on a hash map in the eBPF datapath.
Host-INT
Host-INT extends in-band Network Telemetry support to support telemetry for host network stack. Fundamentally, INT embeds the switching delay incurred for each packet into an INT header in the packet. Host-INT does the same for the host network stack between two hosts. Host-INT has two data-path components: a source and sink based on eBPF. The source runs on a TC hook of the sender host's interface, and the sink runs on an XDP hook of the receiver host’s interface. At the source, it uses Hash maps to store flow statistics. Additionally, it adds in an INT header with an ingress/egress port, timestamps, and so on. At the sink, it uses a perf array to send statistics to a sink userspace program on each packet arrival, and sends the packet to the kernel.
Falco
Falco is a cloud-native runtime security project. It monitors system calls using eBPF probes and parses them at runtime. Falco has provisions to configure alerts on activities such as privileged access using privileged containers, read and write to kernel folders, user addition, password change etc. Falco comprises an userspace program as a CLI tool to specify the alerts and obtain the parsed syscall output and a falco driver built over libscap and libsinsp libraries. For syscalls probes falco uses eBPF ring buffers.
Cilium
Observability in Cilium is enabled using eBPF. Hubble is a platform with eBPF hooks running on each node on a cluster. It helps draw insights on services communicating with each other to build a service dependency graph. It also aids Layer 7 monitoring to analyze for e.g. the HTTP calls as well as Kafka topics, Layer 4 monitoring with TCP retransmission rate, and more.
Tetragon
Tetragon is an extensible framework for security and observability in Cilium. The underlying enabler for tetragon is eBPF with data stored using ring buffers but, along with monitoring eBPF is leveraged to enforce policy spanning various kernel components such as virtual file system (VFS), namespace, system call.
Aquasecurity Tracee
Tracee is an event tracing tool for debugging behavioral patterns built over eBPF. Tracee has multiple hook points at tc, kprobes ,etc to monitor and trace the network traffic. At tc hook, it uses a ring buffer (perf) to submit packet-level events to the user-space.
Revisiting the design of Flow metric agent
While motive and implementation differ across different tools, the central component common to all observability tools is the data structure used to collect the observability metrics. While different tools adopt different data structures to collect the metrics, there are no existing performance measurements carried out to see the impact of the data structure used to collect and store observability metrics. To bridge this gap, we implement template eBPF programs using different data structures to collect the same flow metrics from host traffic. We use the following data structures (called Maps) available in eBPF to collect and store metrics:
- Ring Buffer
- Hash
- Per-CPU Hash
- Array
- Per-CPU Array
Ring Buffer
Ring buffer
is a shared queue between the eBPF datapath and the userspace, where eBPF datapath is the producer and the userspace program is the consumer. It can be used to send per-packet "postcards" to userspace for aggregation of flow metrics. Although this approach could be simple and provide accurate results, it fails to scale because it sends postcards per packet, which keeps the userspace program in a busy loop.
Hash and Per-CPU Hash map
(Per-CPU) Hash map could be used in the eBPF datapath to aggregate per-flow metrics by hashing on the flow-id (for example, 5 tuple IP, port, protocol) and evicting the aggregate information to userspace upon flow completion/inactive. While this approach overcomes the drawbacks of a ring buffer by sending postcards only once per flow and not per packet, it has some disadvantages.
First, there is a possibility of multiple flows being hashed into the same entry, leading to inaccurate aggregation of the flow metrics. Secondly, the hash map necessarily has limited memory for the in-kernel eBPF datapath, so it could be exhausted. Thus userspace program has to implement eviction logic to constantly evict flows upon a timeout.
Array-based map
(Per-CPU) Array-based map can also be used to store per-packet postcards temporarily before eviction to user space, although not an obvious option. The use of arrays poses an advantage by storing per-packet information in the array until it's full and then flushing to userspace only when it's full. This way, it could improve the busy-loop cycle of the userspace compared to using ringbuffer per-packet. Additionally, it does not have the problem of hash collisions of hash map. However, it is complicated to implement because it would require multiple redundant arrays to store per-packet postcards when the main array is flushing out its contents to userspace.
Measurements
So far, we have studied the options that can be used to implement flow metric collection using several data structures. Now it's time to study the performance achieved using a reference implementation of flow metric postcards using each of the above data structures. To do that, we implemented representative eBPF programs which collect flow metrics. The code we used is available on our Git repo. Further, we conducted measurements by sending traffic using a custom-built UDP-based packet generator built on top of PcapPlusPlus.
This graphic describes the experiment setting:
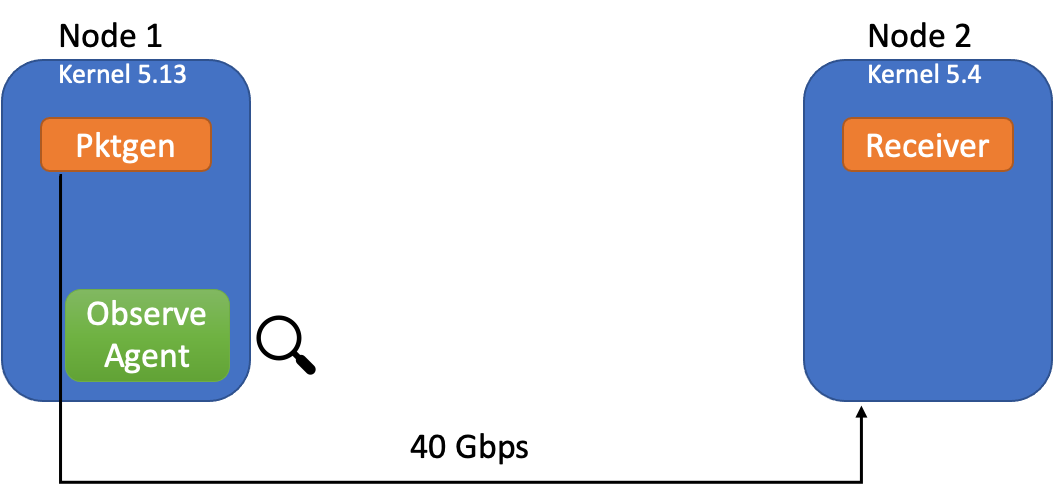
(Kannan/Naik/Lev-Ran, CC BY-SA 4.0)
The observe agent is the eBPF datapath performing flow metric collection, hooked at the tc hook-point of the sender. We use two bare-metal servers connected over a 40G link. Packet generation is done using 40 separate cores. To bring these measurements in perspective, libpcap-based Tcpdump which could be used to collect similar flow information.
Single Flow
We initially run the test with single-flow UDP frames. A single flow test can show us the amount of single flow traffic burst the observe agent can tolerate. As shown in the figure below, native performance without any observe agent is about 4.7 Mpps (Million Packets Per Second), and with tcpdump running, the throughput falls to about 2 Mpps. With eBPF, we observed that the performance varies from 1.6 Mpps to 4.7 Mpps based on the data structure used to store the flow metrics. Using a shared data structure such as HashMap, we observed the most significant drop in performance for a single-flow, because each packet writes to the same entry in the map regardless of the CPU it originated from.
Ringbuffer performs slightly better than a single HashMap for a single flow burst. Using a Per-CPU Hash Map, we observed a good increase in throughput performance, because packets arriving from multiple CPUs no longer contend for the same map entry. However, the performance is still half the native performance without any observe agent. (Note that this performance is without handling hash collisions and evictions.)
With (per-cpu) arrays, we see a significant increase in the throughput of a single flow. We can attribute this to the fact there is literally no contention between packets since each packet takes up a different entry in the array incrementally. However, the major drawback in our implementation is we do not handle the array flushing upon full, while it performs writes in a circular fashion. Hence, it stores the last few packet records observed at any point in time. Nevertheless, it provides us the spectrum of performance gains we can achieve by appropriately applying the data structure in the eBPF datapath.
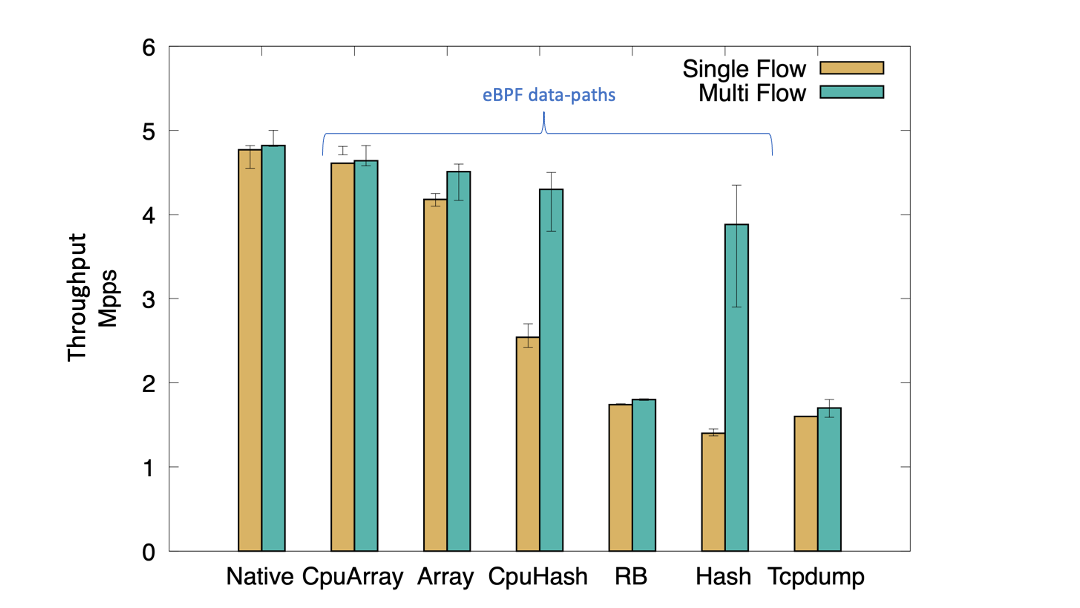
(Kannan/Naik/Lev-Ran, CC BY-SA 4.0)
Multi-Flow
We now test the performance of the eBPF observe agents with multiple flows. We generated 40 different UDP flows (1 flow per core) by instrumenting the packet generator. Interestingly, with multiple flows, we observed a stark difference in performance of per-CPU hash and hash map as compared to single flows. This could be attributed to the reduction in contention for a single hash entry. However, we do not see any performance improvement with ringbuffer since regardless of the flows, the contention channel i.e. ringbuffer is fixed. Array performs marginally better with multiple flows.
Lessons learned
From our studies, we've derrived these conclusions:
- Ringbuffer-based per-packet postcards are not scalable, and they affect performance.
- Hash Maps limit the "burstiness" of a flow, in terms of packets processed per second. Per-CPU hashmaps perform marginally better.
- To handle short bursts of packets within a flow, using an array map to store per-packet postcards would be a good option given array can store a few packet 10s or 100s of packet records. This would ensure that the observe agent could tolerate short bursts without degrading performance.
In our research, we analyzed monitoring of packet-level and flow-level information between multiple hosts in the cloud. We started with the premise that the core feature of observability is how the data is collected in a non-invasive manner. With this outlook, we surveyed existing tools, and tested different methodologies of collecting observability data in the form of flow metrics from packets observed in the eBPF datapath. We studied how the performance of flows were affected by the data structure used to collect flow metrics.
Ideally, to minimize the performance drop of the host traffic due to the overhead of observability agent, our analysis points to a mixed usage of per-cpu array and per-cpu hash data structures. Both of the data-structures could be used together to handle short bursts in flows, using an array and aggregation using a per-CPU hash map. We're currently working on the design of an observability agent (https://github.com/netobserv/netobserv-ebpf-agent), and plan to release a future article with the design details and performance analysis compared to existing tools.
[ Download the eBook: Manage your Linux environment for success ]







5 Comments