

TensorFlow is an open source software library for numerical computation using data-flow graphs. It was originally developed by the Google Brain Team within Google's Machine Intelligence research organization for machine learning and deep neural networks research, but the system is general enough to be applicable in a wide variety of other domains as well. It reached version 1.0 in February 2017, and has continued rapid development, with 21,000+ commits thus far, many from outside contributors. This article introduces TensorFlow, its open source community and ecosystem, and highlights some interesting TensorFlow open sourced models.
TensorFlow is cross-platform. It runs on nearly everything: GPUs and CPUs—including mobile and embedded platforms—and even tensor processing units (TPUs), which are specialized hardware to do tensor math on. They aren't widely available yet, but we have recently launched an alpha program.
opensource.com
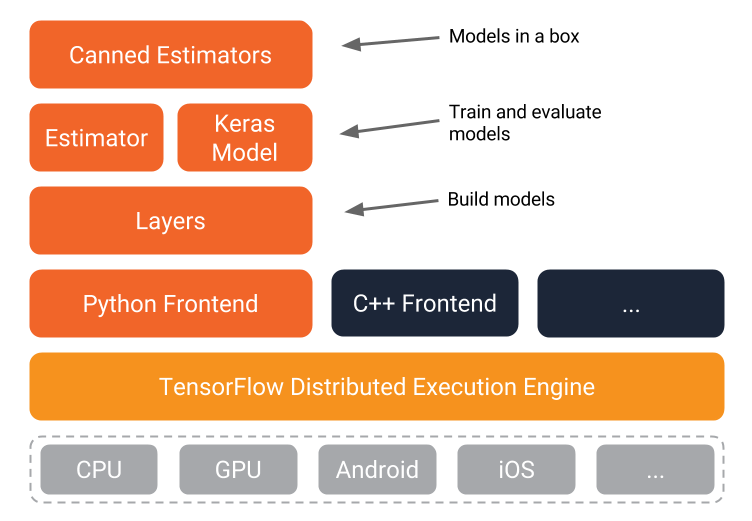
The TensorFlow distributed execution engine abstracts away the many supported devices and provides a high performance-core implemented in C++ for the TensorFlow platform.
On top of that sit the Python and C++ frontends (with more to come). The Layers API provides a simpler interface for commonly used layers in deep learning models. On top of that sit higher-level APIs, including Keras (more on the Keras.io site) and the Estimator API, which makes training and evaluating distributed models easier.
And finally, a number of commonly used models are ready to use out of the box, with more to come.
TensorFlow execution model
Graphs
Machine learning can get complex quickly, and deep learning models can become large. For many model graphs, you need distributed training to be able to iterate within a reasonable time frame. And, you'll typically want the models you develop to deploy to multiple platforms.
With the current version of TensorFlow, you write code to build a computation graph, then execute it. The graph is a data structure that fully describes the computation you want to perform. This has lots of advantages:
- It's portable, as the graph can be executed immediately or saved to use later, and it can run on multiple platforms: CPUs, GPUs, TPUs, mobile, embedded. Also, it can be deployed to production without having to depend on any of the code that built the graph, only the runtime necessary to execute it.
- It's transformable and optimizable, as the graph can be transformed to produce a more optimal version for a given platform. Also, memory or compute optimizations can be performed and trade-offs made between them. This is useful, for example, in supporting faster mobile inference after training on larger machines.
- Support for distributed execution
TensorFlow's high-level APIs, in conjunction with computation graphs, enable a rich and flexible development environment and powerful production capabilities in the same framework.
Eager execution
An upcoming addition to TensorFlow is eager execution, an imperative style for writing TensorFlow. When you enable eager execution, you will be executing TensorFlow kernels immediately, rather than constructing graphs that will be executed later.
Why is this important? Four major reasons:
- You can inspect and debug intermediate values in your graph easily.
- You can use Python control flow within TensorFlow APIs—loops, conditionals, functions, closures, etc.
- Eager execution should make debugging more straightforward.
- Eager's "define-by-run" semantics will make building and training dynamic graphs easy.
Once you are satisfied with your TensorFlow code running eagerly, you can convert it to a graph automatically. This will make it easier to save, port, and distribute your graphs.
This interface is in its early (pre-alpha) stages. Follow along on GitHub.
TensorFlow and the open source software community
TensorFlow was open sourced in large part to allow the community to improve it with contributions. The TensorFlow team has set up processes to manage pull requests, review and route issues filed, and answer Stack Overflow and mailing list questions.
So far, we've had more than 890 external contributors add to the code, with everything from small documentation fixes to large additions like OS X GPU support or the OpenCL implementation. (The broader TensorFlow GitHub organization has had nearly 1,000 unique non-Googler contributors.)
Tensorflow has more than 76,000 stars on GitHub, and the number of other repos that use it is growing every month—as of this writing, there are more than 20,000.
Many of these are community-created tutorials, models, translations, and projects. They can be a great source of examples if you're getting started on a machine learning task.
Stack Overflow is monitored by the TensorFlow team, and it's a good way to get questions answered (with 8,000+ answered so far).
The external version of TensorFlow internally is no different than internal, beyond some minor differences. These include the interface to Google's internal infrastructure (it would be no help to anyone), some paths, and parts that aren't ready yet. The core of TensorFlow, however, is identical. Pull requests to internal will appear externally within around a day and a half and vice-versa.
In the TensorFlow GitHub org, you can find not only TensorFlow itself, but a useful ecosystem of other repos, including models, serving, TensorBoard, Project Magenta, and many more. (A few of these are described below). You can also find TensorFlow APIs in multiple languages (Python, C++, Java, and Go); and the community has developed other bindings, including C#, Haskell, Julia, Ruby, Rust, and Scala.
Performance and benchmarking
TensorFlow has high standards around measurement and transparency. The team has developed a set of detailed benchmarks and has been very careful to include all necessary details to reproduce. We've not yet run comparative benchmarks, but would welcome for others to publish comprehensive and reproducible benchmarks.
There's a section of the TensorFlow site with information specifically for performance-minded developers. Optimization can often be model-specific, but there are some general guidelines that can often make a big difference.
TensorFlow's open source models
The TensorFlow team has open sourced a large number of models. You can find them in the tensorflow/models repo. For many of these, the released code includes not only the model graph, but also trained model weights. This means that you can try such models out of the box, and you can tune many of them further using a process called transfer learning.
Here are just a few of the recently released models (there are many more):
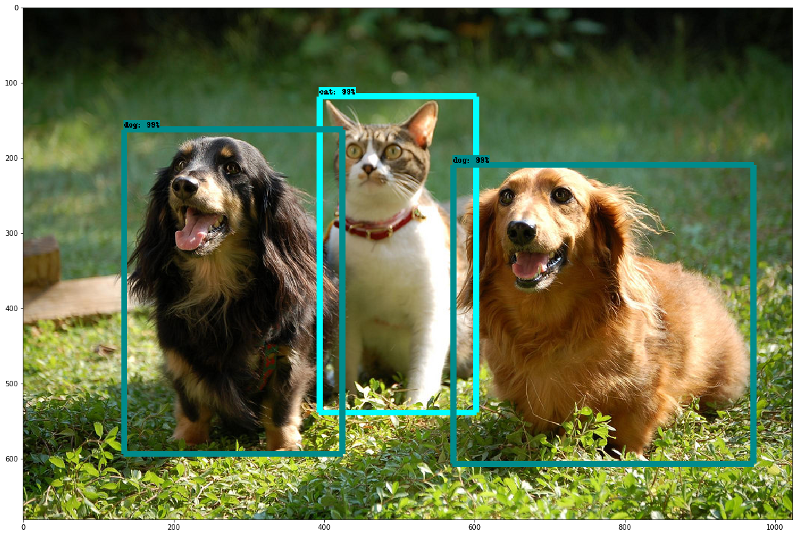
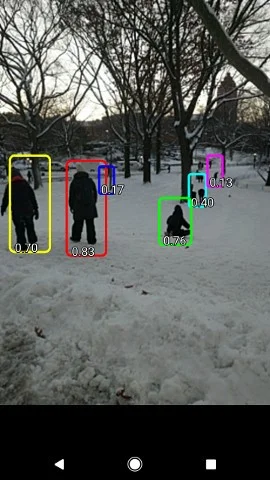
- The Object Detection API: It's still a core machine learning challenge to create accurate machine learning models capable of localizing and identifying multiple objects in a single image. The recently open sourced TensorFlow Object Detection API has produced state-of-the-art results (and placed first in the COCO detection challenge).
opensource.com
- tf-seq2seq: Google previously announced Google Neural Machine Translation (GNMT), a sequence-to-sequence (seq2seq) model that is now used in Google Translate production systems. tf-seq2seq is an open source seq2seq framework in TensorFlow that makes it easy to experiment with seq2seq models and achieve state-of-the-art results.
- ParseySaurus is a set of pretrained models that reflect an upgrade to SyntaxNet. The new models use a character-based input representation and are much better at predicting the meaning of new words based both on their spelling and how they are used in context. They are much more accurate than their predecessors, particularly for languages where there can be dozens of forms for each word and many of these forms might never be observed during training, even in a very large corpus.
opensource.com
- Multistyle Pastiche Generator from the Magenta Project: "Style transfer" is what's happening under the hood with those fun apps that apply the style of a painting to one of your photos. This Magenta model extends image style transfer by creating a single network that can perform more than one stylization of an image, optionally at the same time. (Try playing with the sliders for the dog images in this blog post.)

opensource.com
Transfer learning
Many of the TensorFlow models include trained weights and examples that show how you can use them for transfer learning, e.g. to learn your own classifications. You typically do this by deriving information about your input data from the penultimate layer of a trained model—which encodes useful abstractions—then use that as input to train your own much smaller neural net to predict your own classes. Because of the power of the learned abstractions, the additional training typically does not require large data sets.
For example, you can use transfer learning with the Inception image classification model to train an image classifier that uses your specialized image data.
For examples of using transfer learning for medical diagnosis by training a neural net to detect specialized classes of images, see the following articles:
- Deep learning for detection of diabetic eye disease
- Deep learning algorithm does as well as dermatologists in identifying skin cancer
- Assisting pathologists in detecting cancer with deep learning
And, you can do the same to learn your own (potentially goofy) image classifications too.
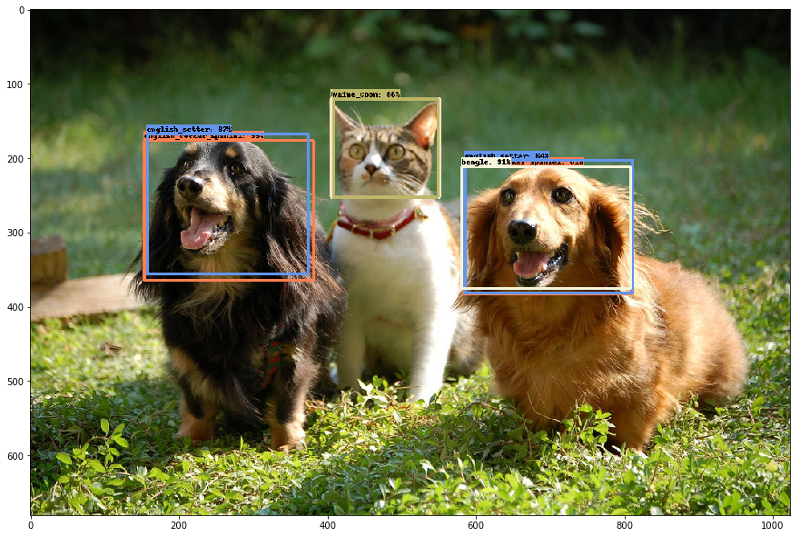
The Object Detection API code is designed to support transfer learning as well. In the tensorflow/models repo, there is an example of how you can use transfer learning to bootstrap this trained model to build a pet detector, using a (somewhat limited) data set of dog and cat breed examples. And, in case you like raccoons more than dogs and cats, see this tutorial too.
opensource.com
Using TensorFlow on mobile devices
Mobile is a great use case for TensorFlow—mobile makes sense when there is a poor or missing network connection or where sending continuous data to a server would be too expensive. But, once you've trained your model and you're ready to start using it, you don't want the on-device model footprint to be too big.
TensorFlow is working to help developers make lean mobile apps, both by continuing to reduce the code footprint and by supporting quantization.
(And although it's early days, see also Accelerated Linear Algebra [XLA], a domain-specific compiler for linear algebra that optimizes TensorFlow computations.)
One of the TensorFlow projects, MobileNet, is developing a set of computer vision models that are particularly designed to address the speed/accuracy trade-offs that need to be considered on mobile devices or in embedded applications. The MobileNet models can be found in the TensorFlow models repo as well.
One of the newer Android demos, TF Detect, uses a MobileNet model trained using the Tensorflow Object Detection API.
opensource.com
And of course we'd be remiss in not mentioning "How HBO's 'Silicon Valley' built 'Not Hotdog' with mobile TensorFlow, Keras, and React Native."
The TensorFlow ecosystem
The TensorFlow ecosystem includes many tools and libraries to help you work more effectively. Here are a few.
TensorBoard
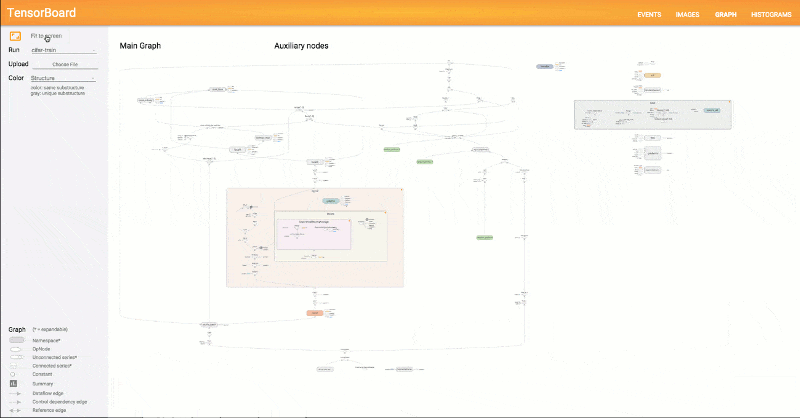
TensorBoard is a suite of web applications for inspecting, visualizing, and understanding your TensorFlow runs and graphs. You can use TensorBoard to view your TensorFlow model graphs and zoom in on the details of graph subsections.
You can plot metrics like loss and accuracy during a training run; show histogram visualizations of how a tensor is changing over time; show additional data, like images; collect runtime metadata for a run, such as total memory usage and tensor shapes for nodes; and more.
opensource.com
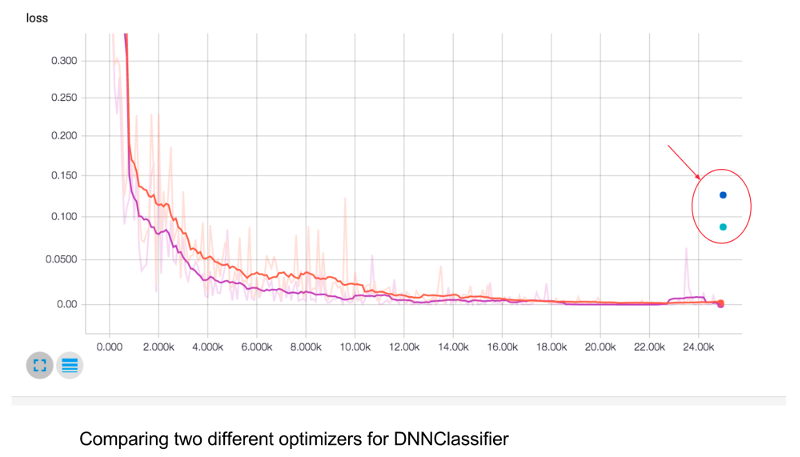
TensorBoard works by reading TensorFlow files that contain summary information about the training process. You can generate these files when running TensorFlow jobs.
You can use TensorBoard to compare training runs, collect runtime stats, and generate histograms.
opensource.com
A particularly mesmerizing feature of TensorBoard is its embeddings visualizer. Embeddings are ubiquitous in machine learning, and in the context of TensorFlow, it's often natural to view tensors as points in space, so almost any TensorFlow model will give rise to various embeddings.
Datalab
Jupyter notebooks are an easy way to interactively explore your data, define TensorFlow models, and kick off training runs. If you're using Google Cloud Platform tools and products as part of your workflow—maybe using Google Cloud Storage or BigQuery for your datasets, or Apache Beam for data preprocessing—then Google Cloud Datalab provides a Jupyter-based environment with all of these tools (and others like NumPy, pandas, scikit-learn, and Matplotlib), along with TensorFlow, preinstalled and bundled together. Datalab is open source, so if you want to further modify its notebook environment, it's easy to do.
Facets
Machine learning's power comes from its ability to learn patterns from large amounts of data, so understanding your data can be critical to building a powerful machine learning system.
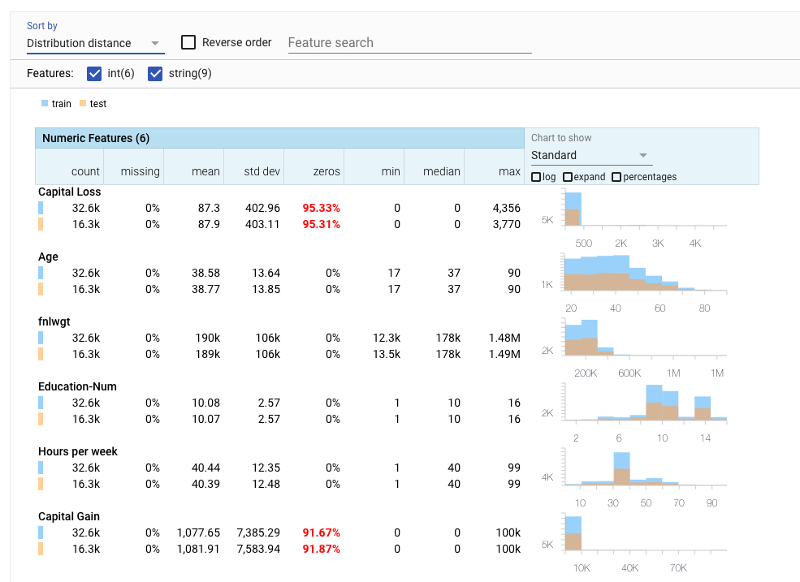
Facets is a recently released open source data visualization tool that helps you understand your machine learning datasets and get a sense of the shape and characteristics of each feature and see at a glance how the features interact with each other. For example, you can view your training and test datasets (as is done here with some Census data), compare the characteristics of each feature, and sort the features by "distribution distance."
opensource.com
Cloud Datalab includes Facets integration. This GitHub link has a small example of loading a NHTSA Traffic Fatality BigQuery public dataset and viewing it with Facets.
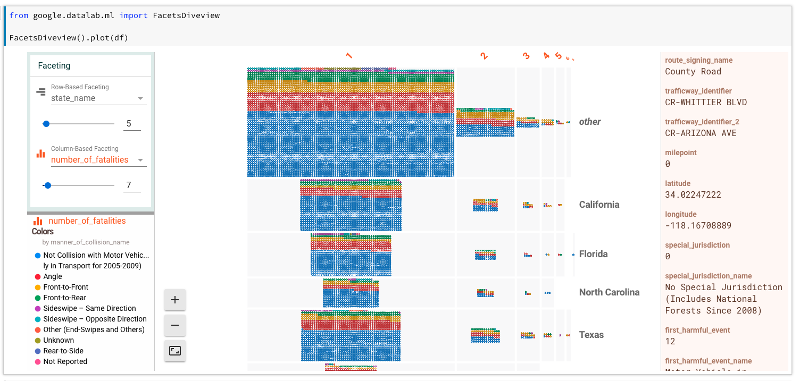
opensource.com
In Facets' Dive view we can quickly see which states have the most traffic fatalities and that the distribution of collusion type appears to change as the number of fatalities per accident increases.
And more…
Another useful diagnostic tool is the TensorFlow debugger, tfdbg, which lets you view the internal structure and states of running TensorFlow graphs during training and inference.
Once you've trained a model that you're happy with, the next step is to figure out how you'll serve it in order to scalably support predictions on the model. TensorFlow Serving is a high-performance serving system for machine-learned models, designed for production environments. It has recently moved to version 1.0.
There are many other tools and libraries that we don't have room to cover here, but see the TensorFlow GitHub org repos to learn about them.
The TensorFlow site has many getting started guides, examples, and tutorials. (A fun new tutorial is this audio recognition example.)





2 Comments