

For very large collections of diverse, unstructured information, graph databases have emerged as a technology to help collect, manage, and search large sets of data. In this three-part series, we'll explore graph databases, using Neo4j, an open source graph database.
In this article, I'll show you the basics of graph databases, bringing you up to speed on the conceptual model. In the second, I'll show you how to spin up a Neo4j database and populate it with some data using the built-in browser tools. And, in the third and final article in the series, we'll explore a couple of programming libraries for using Neo4j in your development work.
Grasping the conceptual model for graph databases is useful, so we'll start there. A graph database has only two kinds of data stored in it: nodes and edges.
- Nodes are entities: things such as people, invoices, movies, books, or other concrete things. These are somewhat equivalent to a record or row in a relational database.
- Edges name relationships: the concepts, events, or things that connect nodes. In relational databases, these relationships are ordinarily stored in the database rows with a linking field. In graph databases, they are themselves useful, searchable objects in their own right.
Both nodes and edges can possess searchable properties. For instance, if your nodes represented people, they might own properties like name, gender, date of birth, height, and so forth. Edge properties might describe when a relationship between two people was established, the circumstances of meeting, or the nature of the relationship.
Here's a diagram to help you visualize this:
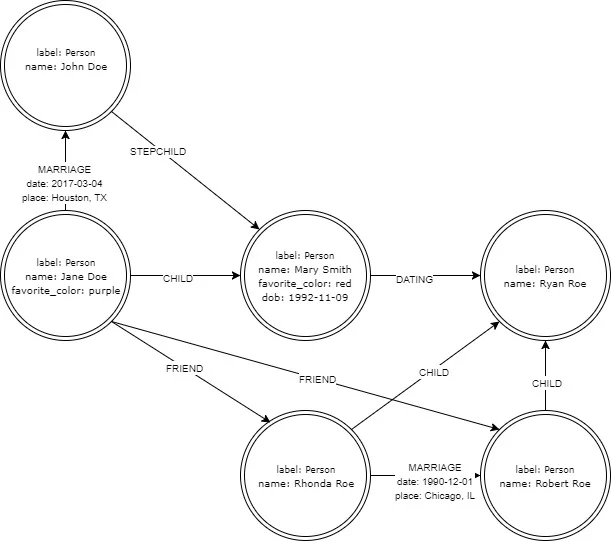
opensource.com
In this diagram, you learn that Jane Doe has a new husband, John; a daughter (from her prior relationship) Mary Smith; and friends Robert and Rhonda Roe. The Roes have a son, Ryan, who is dating Mary Smith.
See how it works? Each node represents a person, standing alone, in isolation from other nodes. Everything you need to find about that person can be stored in the node's properties. Edges describe the relationships between the people, with as much detail as you need for the application.
Relationships are one-way and cannot be undirected, but that's no problem. Since the database can traverse both directions with the same speed, and direction can be ignored, you only need to define this relationship once. If your application requires directional relationships, you're free to use them, but if bidirectionality is implied, it's not required.
Another thing to notice is that graph databases are, by nature, schema-less. This differs from a relational database, where each row has a set list of fields, and adding new fields is a major investment in development and upgrades.
Each node can possess a label; this label is all the "typing" you need for most applications and is the analog of the table name in a typical relational database. A label lets you differentiate between different node types. If you need to add a new label or property, change your application to start using it!
With graph databases, you can simply start using the new properties and labels, and nodes will acquire them as they are created or edited. There's no need to convert things; just start using them in your code. In the example here, you can see that we know Jane's and Mary's favorite colors and Mary's date of birth, but not anyone else's. The system doesn't need to know about that; users can add that information at will as nodes are accessed in the normal course of the application's usage.
As a developer, this is a useful thing. Instead of having to handle the database schema changes, you can just add the new label or property to forms that deal with the nodes and start using it. For nodes that don't have the property, nothing is displayed. You'd have to code the form with either type of database, but you drop a lot of the backend work that you'd need to do with a relational database.
Let's add some new information:
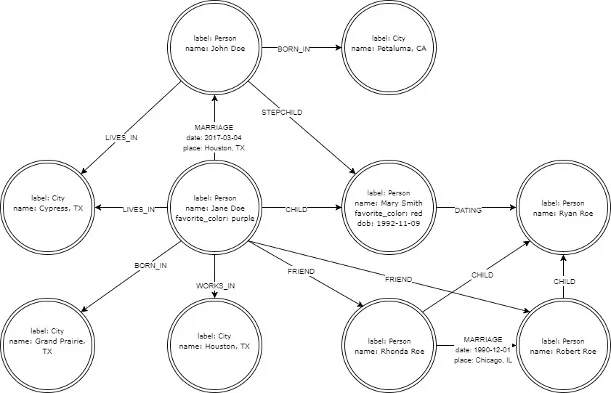
opensource.com
Here is a new type of node, representing a location, and some relevant relationships. Now we see that John Doe was born in Petaluma, Calif., while his wife, Jane, was born in Grand Prairie, Texas. They both now live in Cypress, Texas, because Jane works in nearby Houston. The lack of city relationships with Ryan Roe isn't any big deal to the database, we just don't know that information yet. The database could easily acquire new data and add it, creating new nodes and relationships as needed, as application users entered more data.
Understanding nodes and edges should be enough to get you started with graph databases. If you're like me, you're already thinking about how an application you work on might be restructured in a graph. In the next article in this series, I'll show you how to install Neo4j, insert data, and do some basic searching.





1 Comment