

In the first article in this series, we explored some core concepts of graph databases. This time, we'll install the Neo4j application and begin using the web client to insert and query data in the graph.
To download the Community Edition of Neo4J head for their website! You can download a package for Windows or OSX that will work just fine for testing, and there are links for installations on most Linux distros, and via Docker.
I'll be installing the software on Debian 9 (stretch). You can get full instructions here. If you're running Debian 8 (jessie) or older, you can install the current Neo4j package, but it will be a bit more difficult as Neo4j requires the Java 8 runtime, which is not packaged with jessie.
wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.org/repo stable/' | sudo tee /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
sudo apt-get install neo4j
On my system, I had to create /var/run/neo4j, for some reason, and then it started easily. I got a warning about maximum open files, but that turned out to be a non-issue since this is just a test. By default, Neo4j will listen for connections only on localhost. This is fine, if your Debian box is a desktop, but mine isn't. I edited /etc/neo4j/neo4j.conf and uncommented this line:
dbms.connectors.default_listen_address=0.0.0.0
After stopping and restarting Neo4j, I was able to connect by browsing to the server on port 7474. The default password for the Neo4j user is neo4j; you'll have to set a new password, then the startup screen will display:
opensource.com
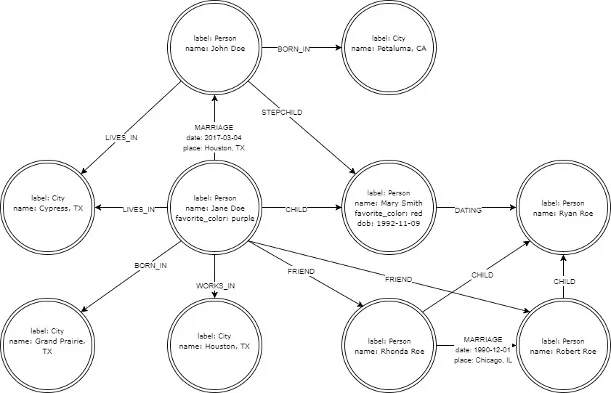
Let's use the graph from the last article, and create it in Neo4j. Here it is again:
opensource.com
Like MySQL and other database systems, Neo4j uses a query system for all operations. Cypher, the query language of Neo4j, has some syntactic quirks that take a little getting used to. Nodes are always encased in parentheses and relationships in square brackets. Since that's the only type of data there is, that's all you need.
First, let's create all the nodes. You can copy and paste these into the top box in the browser window, which is where queries are run.
CREATE (a:Person { name: 'Jane Doe', favorite_color: 'purple' })
CREATE (b:Person { name: 'John Doe' })
CREATE (c:Person { name: 'Mary Smith', favorite_color: 'red', dob: '1992-11-09' })
CREATE (d:Person { name: 'Robert Roe' })
CREATE (e:Person { name: 'Rhonda Roe' })
CREATE (f:Person { name: 'Ryan Roe' })
CREATE (t:City { name: 'Petaluma, CA' })
CREATE (u:City { name: 'Cypress, TX' })
CREATE (v:City { name: 'Grand Prairie, TX' })
CREATE (w:City { name: 'Houston, TX' })
Note that the letter before the label is a variable. These will show up elsewhere; they're not useful here, but you can't just blindly create without assignment, so we'll use them and then discard them.
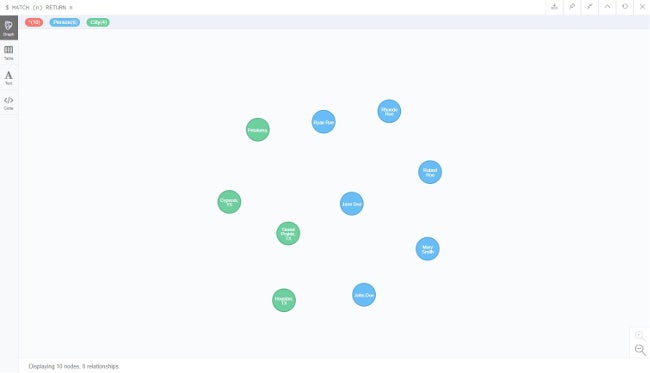
You should be told that 10 nodes were created and 13 properties set. Want to see them? Here's a query that matches and returns all nodes:
MATCH (n)
RETURN n
This will return a visual graph. (Within the app, you can use the "fullscreen" icon on the returned graph to see the whole thing.) You'll see something like this:
opensource.com
Adding a relationship is a little bit trickier; you must have the nodes you want to connect "in scope," meaning within the scope of the current query. The variables we used earlier have gone out of scope, so let's find John and Jane and marry them:
MATCH (a:Person),(b:Person)
WHERE a.name='Jane Doe' AND b.name='John Doe'
CREATE (a)-[r:MARRIAGE {date: '2017-03-04', place: 'Houston, TX'}]->(b)
This query will set two properties and create one relationship. Re-running the MATCH query shows that relationship. You can point your mouse arrow at any of the nodes or relationships to see the properties for that item.
Let's add the rest of the relationships. Rather than doing a bunch of MATCH statements, I'm going to do it once and CREATE multiple relationships from them.
MATCH (a:Person),(b:Person),(c:Person),(d:Person),(e:Person),(f:Person),(t:City),(u:City),(v:City),(w:City)
WHERE a.name='Jane Doe' AND b.name='John Doe' AND c.name='Mary Smith' AND d.name='Robert Roe'
AND e.name='Rhonda Roe' AND f.name='Ryan Roe' AND t.name='Petaluma, CA' AND u.name='Cypress, TX'
AND v.name='Grand Prairie, TX' AND w.name='Houston, TX'
CREATE (d)-[m2:MARRIAGE {date: '1990-12-01', place: 'Chicago, IL'}]->(e)
CREATE (a)-[n:CHILD]->(c)
CREATE (d)-[n2:CHILD]->(f)
CREATE (e)-[n3:CHILD]->(f)
CREATE (b)-[n4:STEPCHILD]->(c)
CREATE (a)-[o:BORN_IN]->(v)
CREATE (b)-[o2:BORN_IN]->(t)
CREATE (c)-[p:DATING]->(f)
CREATE (a)-[q:LIVES_IN]->(u)
CREATE (b)-[q1:LIVES_IN]->(u)
CREATE (a)-[r:WORKS_IN]->(w)
CREATE (a)-[s:FRIEND]->(d)
CREATE (a)-[s2:FRIEND]->(e)
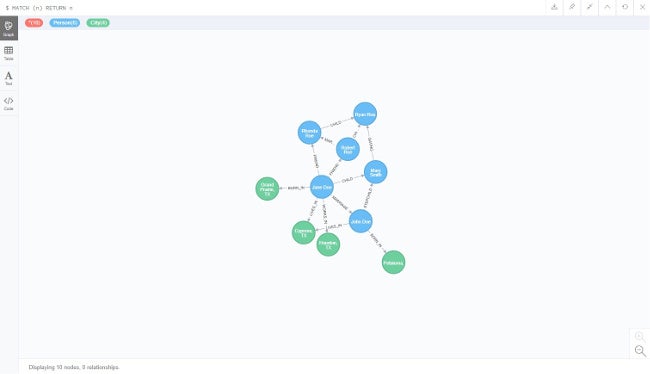
Re-query with the MATCH statement, and you should have a graph like this:
opensource.com
If you want, you can drag the nodes around and end up with the same graph as my drawing from before.
In this example, the only MATCH we've done is to MATCH everything. Here's a query that will return the two married couples and show the relationship between them:
MATCH (a)-[b:MARRIAGE]->(c)
RETURN a,b,c
With a more elaborate graph, you could do much more detailed searching. For instance, if you had a graph of Movie and Person nodes, and the relationships were roles like ACTED IN, DIRECTED, WROTE SCREENPLAY, and so forth, you could do queries like this:
MATCH (p:Person { name: 'Mel Gibson' })--(m:Movie)
RETURN m.title
...and get back a list of films connected to Mel Gibson in any way. But if you only wanted movies where he was an actor, this query would be more useful:
MATCH (p:Person { name: 'Mel Gibson' })-[r:ACTED_IN]->(m:movie)
RETURN m.title,r.role
Fancier Cypher queries are possible, of course, and we're just scratching the surface here. The full documentation for the Cypher language is available at the Neo4j website, and it has lots of examples to work with.
In the next article in this series, we'll write a little Perl script to create this same graph to show how to use graph databases in an application.





Comments are closed.