

In this tutorial, I'll explain how to use Pandas and Python to work with messy data. If you have never used Pandas before and know the basics of Python, this tutorial is for you.
Weather data is a good real-world example of a messy dataset. It comes with mixed content, irregular dropouts, and time zones, all of which are common pain points for data scientists. I'll will go through examples of how to deal with mixed content and irregular dropouts. To work with odd time zones, refer to Mario Corchero’s excellent post, How to work with dates and time with Python.
Let’s start from scratch and turn a messy file into a useful dataset. Entire source code is available on GitHub.
Reading a CSV file
You can open a CSV file in Pandas with the following:
- pandas.read_csv(): Opens a CSV file as a DataFrame, like a table.
- DataFrame.head(): Displays the first 5 entries.
DataFrame is like a table in Pandas; it has a set number of columns and indices. CSV files are great for DataFrames because they come in columns and rows of data.
import pandas as pd
# Open a comma-separated values (CSV) file as a DataFrame
weather_observations = \
pd.read_csv('observations/Canberra_observations.csv')
# Print the first 5 entries
weather_observations.head()

opensource.com
Looks like our data is actually tab-separated by \t. There are interesting items in there that look to be time.
pandas.read_csv() provides versatile keyword arguments for different situations. Here you have a column for Date and another for Time. You can introduce a few keyword arguments to add some intelligence:
- sep: The separator between columns
- parse_dates: Treat one or more columns like dates
- dayfirst: Use DD.MM.YYYY format, not month first
- infer_datetime_format: Tell Pandas to guess the date format
- na_values: Add values to treat as empty
Use these keyword arguments to pre-format the data and let Pandas do some heavy lifting.
# Supply pandas with some hints about the file to read
weather_observations = \
pd.read_csv('observations/Canberra_observations.csv',
sep='\t',
parse_dates={'Datetime': ['Date', 'Time']},
dayfirst=True,
infer_datetime_format=True,
na_values=['-']
)

Pandas nicely converts two columns, Date and Time, to a single column, Datetime, and renders it in a standard format.
There is a NaN value here, not to be confused with the “not a number” floating point. It’s just Pandas' way of saying it’s empty.
Sorting data in order
Let’s look at ways Pandas can address data order.
- DataFrame.sort_values(): Rearrange in order.
- DataFrame.drop_duplicates(): Delete duplicated items.
- DataFrame.set_index(): Specify a column to use as index.
Because the time seems to be going backward, let’s sort it:
# Sorting is ascending by default, or chronological order
sorted_dataframe = weather_observations.sort_values('Datetime')
sorted_dataframe.head()

Why are there two midnights? It turns out our dataset (raw data) contains midnight at both the end and the beginning of each day. You can discard one as a duplicate since the next day also comes with another midnight.
The logical order here is to discard the duplicates, sort the data, and then set the index:
# Sorting is ascending by default, or chronological order
sorted_dataframe = weather_observations.sort_values('Datetime')
# Remove duplicated items with the same date and time
no_duplicates = sorted_dataframe.drop_duplicates('Datetime', keep='last')
# Use `Datetime` as our DataFrame index
indexed_weather_observations = \
sorted_dataframe.set_index('Datetime')
indexed_weather_observations.head()

opensource.com
Now you have a DataFrame with time as its index, which will come in handy later. First, let’s transform wind directions.
Transforming column values
To prepare wind data for weather modelling, you can use the wind values in a numerical format. By convention, north wind (↓) is 0 degrees, going clockwise ⟳. East wind (←) is 90 degrees, and so on. You will leverage Pandas to transform:
- Series.apply(): Transforms each entry with a function.
To work out the exact value of each wind direction, I wrote a dictionary by hand since there are only 16 values. This is tidy and easy to understand.
# Translate wind direction to degrees
wind_directions = {
'N': 0. , 'NNE': 22.5, 'NE': 45. , 'ENE': 67.5 ,
'E': 90. , 'ESE': 112.5, 'SE': 135. , 'SSE': 157.5 ,
'S': 180. , 'SSW': 202.5, 'SW': 225. , 'WSW': 247.5 ,
'W': 270. , 'WNW': 292.5, 'NW': 315. , 'NNW': 337.5 }
You can access a DataFrame column, called a Series in Pandas, by an index accessor like you would with a Python dictionary. After the transformation, the Series is replaced by new values.
# Replace wind directions column with a new number column
# `get()` accesses values fomr the dictionary safely
indexed_weather_observations['Wind dir'] = \
indexed_weather_observations['Wind dir'].apply(wind_directions.get)
# Display some entries
indexed_weather_observations.head()

opensource.com
Each one of the valid wind directions is now a number. It doesn’t matter if the value is a string or another kind of number; you can use Series.apply() to transform it.
Setting index frequency
Digging deeper, you find more flaws in the dataset:
# One section where the data has weird timestamps ...
indexed_weather_observations[1800:1805]

opensource.com
00:33:00? 01:11:00? These are odd timestamps. There is a function to ensure a consistent frequency:
DataFrame.asfreq(): Forces a specific frequency on the index, discarding and filling the rest.
# Force the index to be every 30 minutes
regular_observations = \
indexed_weather_observations.asfreq('30min')
# Same section at different indices since setting
# its frequency :)
regular_observations[1633:1638]

opensource.com
Pandas discards any indices that don’t match the frequency and adds an empty row if one doesn’t exist. Now you have a consistent index frequency. Let’s plot it to see how it looks with matplotlib, a popular plotting library:
import matplotlib.pyplot as plt
# Make the graphs a bit prettier
pd.set_option('display.mpl_style', 'default')
plt.rcParams['figure.figsize'] = (18, 5)
# Plot the first 500 entries with selected columns
regular_observations[['Wind spd', 'Wind gust', 'Tmp', 'Feels like']][:500].plot()

opensource.com
Looking closer, there seem to be gaps around Jan 6th, 7th, and more. You need to fill these with something meaningful.
Interpolate and fill empty rows
To fill gaps, you can linearly interpolate the values, or draw a line from the two end points of the gap and fill each timestamp accordingly.
- Series.interpolate(): Fill in empty values based on index.
Here you also use the inplace keyword argument to tell Pandas to perform the operation and replace itself.
# Interpolate data to fill empty values
for column in regular_observations.columns:
regular_observations[column].interpolate('time', inplace=True, limit_direction='both')
# Display some interpolated entries
regular_observations[1633:1638]
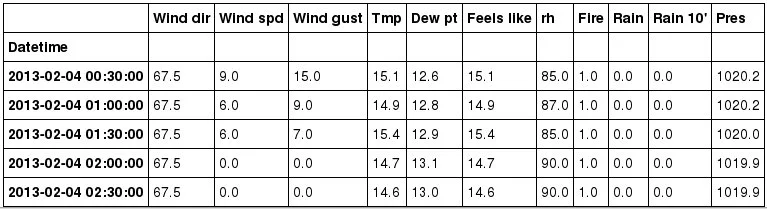
opensource.com
NaN values have been replaced. Let’s plot it again:
# Plot it again - gap free!
regular_observations[['Wind spd', 'Wind gust', 'Tmp', 'Feels like']][:500].plot()

opensource.com
Congratulations! The data is now ready to be used for weather processing. You can download the example code on GitHub and play with it.
Conclusion
I've shown how to clean up messy data with Python and Pandas in several ways, such as:
- reading a CSV file with proper structures,
- sorting your dataset,
- transforming columns by applying a function
- regulating data frequency
- interpolating and filling missing data
- plotting your dataset
Pandas offers many more powerful functions, which you can find in the documentation, and its excellent 10-minute introduction. You might find a few gems in there. If you have questions or thoughts, feel free to reach me on Twitter at @Xavier_Ho.
Happy data cleaning!
More resources
- SciPy Interpolate: More than just linear interpolation to fill your datasets.
- XArray and Pandas: Working with datasets bigger than your system memory? Start here.
- Visualising Data with Python: Talk video by Clare Sloggett at PyCon AU 2017.





3 Comments