

Many Linux enthusiasts are familiar with Linus Torvalds' famous admonition, "we don't break user space," but perhaps not everyone who recognizes the phrase is certain about what it means.
The "#1 rule" reminds developers about the stability of the applications' binary interface via which applications communicate with and configure the kernel. What follows is intended to familiarize readers with the concept of an ABI, describe why ABI stability matters, and discuss precisely what is included in Linux's stable ABI. The ongoing growth and evolution of Linux necessitate changes to the ABI, some of which have been controversial.
What is an ABI?
ABI stands for Applications Binary Interface. One way to understand the concept of an ABI is to consider what it is not. Applications Programming Interfaces (APIs) are more familiar to many developers. Generally, the headers and documentation of libraries are considered to be their API, as are standards documents like those for HTML5, for example. Programs that call into libraries or exchange string-formatted data must comply with the conventions described in the API or expect unwanted results.
ABIs are similar to APIs in that they govern the interpretation of commands and exchange of binary data. For C programs, the ABI generally comprises the return types and parameter lists of functions, the layout of structs, and the meaning, ordering, and range of enumerated types. The Linux kernel remains, as of 2022, almost entirely a C program, so it must adhere to these specifications.
"The kernel syscall interface" is described by Section 2 of the Linux man pages and includes the C versions of familiar functions like "mount" and "sync" that are callable from middleware applications. The binary layout of these functions is the first major part of Linux's ABI. In answer to the question, "What is in Linux's stable ABI?" many users and developers will respond with "the contents of sysfs (/sys) and procfs (/proc)." In fact, the official Linux ABI documentation concentrates mostly on these virtual filesystems.
The preceding text focuses on how the Linux ABI is exercised by programs but fails to capture the equally important human aspect. As the figure below illustrates, the functionality of the ABI requires a joint, ongoing effort by the kernel community, C compilers (such as GCC or clang), the developers who create the userspace C library (most commonly glibc) that implements system calls, and binary applications, which much be laid out in accordance with the Executable and Linking Format (ELF).
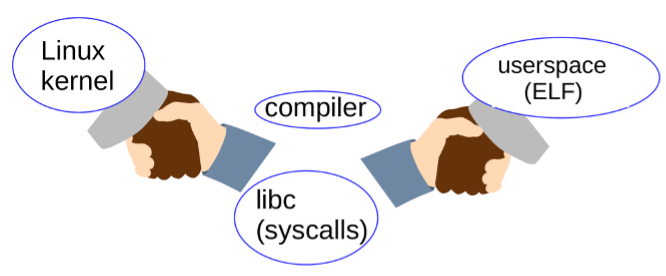
(Alison Chaiken, CC BY-SA 4.0)
Why do we care about the ABI?
The Linux ABI stability guarantee that comes from Torvalds himself enables Linux distros and individual users to update the kernel independently of the operating system.
If Linux did not have a stable ABI, then every time the kernel needed patching to address a security problem, a large part of the operating system, if not the entirety, would need to be reinstalled. Obviously, the stability of the binary interface is a major contributing factor to Linux's usability and wide adoption.
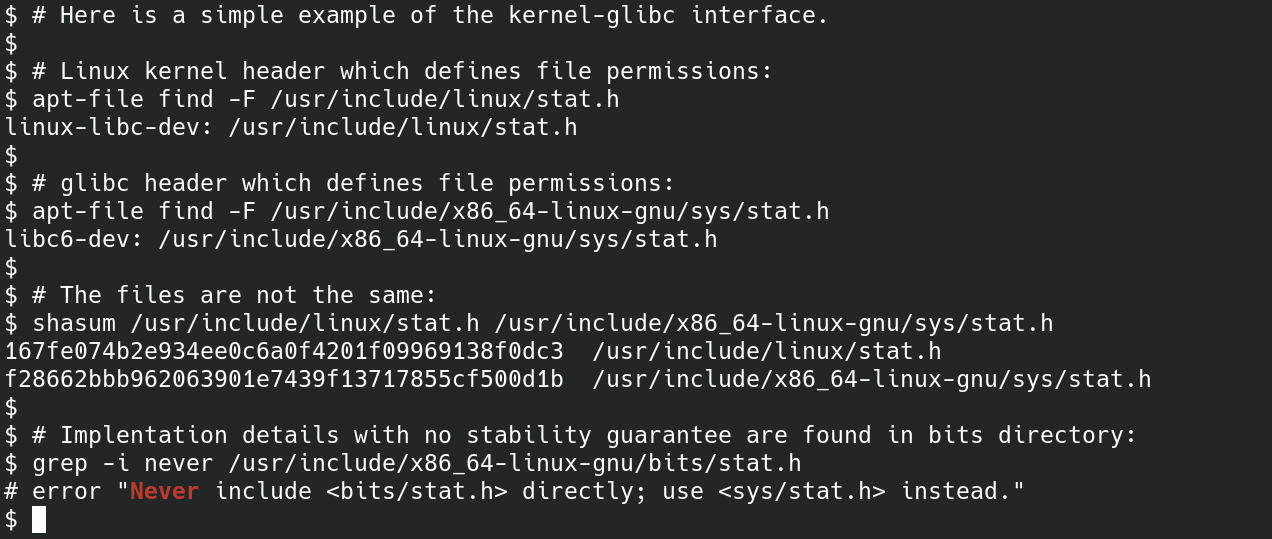
(Alison Chaiken, CC BY-SA 4.0)
As the second figure illustrates, both the kernel (in linux-libc-dev) and Glibc (in libc6-dev) provide bitmasks that define file permissions. Obviously the two sets of definitions must agree! The apt package manager identifies which software project provided each file. The potentially unstable part of Glibc's ABI is found in the bits/ directory.
For the most part, the Linux ABI stability guarantee works just fine. In keeping with Conway's Law, vexing technical issues that arise in the course of development most frequently occur due to misunderstandings or disagreements between different software development communities that contribute to Linux. The interface between communities is easy to envision via Linux package-manager metadata, as shown in the image above.
Y2038: An example of an ABI break
The Linux ABI is best understood by considering the example of the ongoing, slow-motion "Y2038" ABI break. In January 2038, 32-bit time counters will roll over to all zeroes, just like the odometer of an older vehicle. January 2038 sounds far away, but assuredly many IoT devices sold in 2022 will still be operational. Mundane products like smart electrical meters and smart parking systems installed this year may or may not have 32-bit processor architectures and may or may not support software updates.
The Linux kernel has already moved to a 64-bit time_t opaque data type internally to represent later timepoints. The implication is that system calls like time() have already changed their function signature on 64-bit systems. The arduousness of these efforts is on ready display in kernel headers like time_types.h, which includes new and "_old" versions of data structures.

(marneejill, CC BY-SA 2.0)
The Glibc project also supports 64-bit time, so yay, we're done, right? Unfortunately, no, as a discussion on the Debian mailing list makes clear. Distros are faced with the unenviable choice of either providing two versions of all binary packages for 32-bit systems or two versions of installation media. In the latter case, users of 32-bit time will have to recompile their applications and reinstall. As always, proprietary applications will be a real headache.
What precisely is in the Linux stable ABI anyway?
Understanding the stable ABI is a bit subtle. Consider that, while most of sysfs is stable ABI, the debug interfaces are guaranteed to be unstable since they expose kernel internals to userspace. In general, Linus Torvalds has pronounced that by "don't break userspace," he means to protect ordinary users who "just want it to work" rather than system programmers and kernel engineers, who should be able to read the kernel documentation and source code to figure out what has changed between releases. The distinction is illustrated in the figure below.
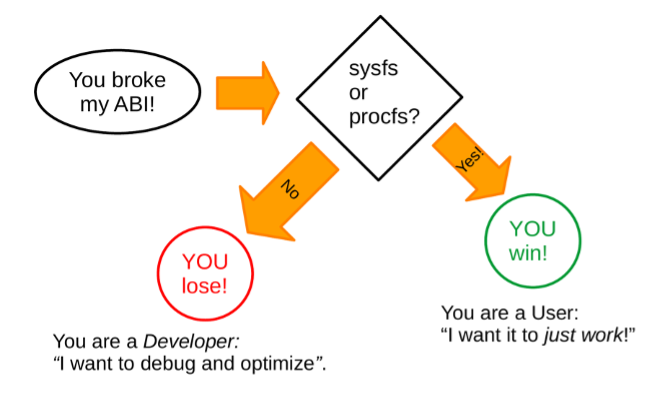
(Alison Chaiken, CC BY-SA 4.0)
Ordinary users are unlikely to interact with unstable parts of the Linux ABI, but system programmers may do so inadvertently. All of sysfs (/sys) and procfs (/proc) are guaranteed stable except for /sys/kernel/debug.
But what about other binary interfaces that are userspace-visible, including miscellaneous ABI bits like device files in /dev, the kernel log file (readable with the dmesg command), filesystem metadata, or "bootargs" provided on the kernel "command line" that are visible in a bootloader like GRUB or u-boot? Naturally, "it depends."
Mounting old filesystems
Next to observing a Linux system hang during the boot sequence, having a filesystem fail to mount is the greatest disappointment. If the filesystem resides on an SSD belonging to a paying customer, the matter is grave indeed. Surely a Linux filesystem that mounts with an old kernel version will still mount when the kernel is upgraded, right? Actually, "it depends."
In 2020 an aggrieved Linux developer complained on the kernel's mailing list:
The kernel already accepted this as a valid mountable filesystem format, without a single error or warning of any kind, and has done so stably for years. . . . I was generally under the impression that mounting existing root filesystems fell under the scope of the kernel<->userspace or kernel<->existing-system boundary, as defined by what the kernel accepts and existing userspace has used successfully, and that upgrading the kernel should work with existing userspace and systems.
But there was a catch: The filesystems that failed to mount were created with a proprietary tool that relied on a flag that was defined but not used by the kernel. The flag did not appear in Linux's API header files or procfs/sysfs but was instead an implementation detail. Therefore, interpreting the flag in userspace code meant relying on "undefined behavior," a phrase that will make software developers almost universally shudder. When the kernel community improved its internal testing and started making new consistency checks, the "man 2 mount" system call suddenly began rejecting filesystems with the proprietary format. Since the format creator was decidedly a software developer, he got little sympathy from kernel filesystem maintainers.

(Kernel developers working in-tree are protected from ABI changes. Alison Chaiken, CC BY-SA 4.0)
Threading the kernel dmesg log
Is the format of files in /dev guaranteed stable or not? The command dmesg reads from the file /dev/kmsg. In 2018, a developer made output to dmesg threaded, enabling the kernel "to print a series of printk() messages to consoles without being disturbed by concurrent printk() from interrupts and/or other threads." Sounds excellent! Threading was made possible by adding a thread ID to each line of the /dev/kmsg output. Readers following closely will realize that the addition changed the ABI of /dev/kmsg, meaning that applications that parse that file needed to change too. Since many distros didn't compile their kernels with the new feature enabled, most users of /bin/dmesg won't have noticed, but the change broke the GDB debugger's ability to read the kernel log.
Assuredly, astute readers will think users of GDB are out of luck because debuggers are developer tools. Actually, no, since the code that needed to be updated to support the new /dev/kmsg format was "in-tree," meaning part of the kernel's own Git source repository. The failure of programs within a single repo to work together is just an out-and-out bug for any sane project, and a patch that made GDB work with threaded /dev/kmsg was merged.
What about BPF programs?
BPF is a powerful tool to monitor and even configure the running kernel dynamically. BPF's original purpose was to support on-the-fly network configuration by allowing sysadmins to modify packet filters from the command line instantly. Alexei Starovoitov and others greatly extended BPF, giving it the power to trace arbitrary kernel functions. Tracing is clearly the domain of developers rather than ordinary users, so it is certainly not subject to any ABI guarantee (although the bpf() system call has the same stability promise as any other). On the other hand, BPF programs that create new functionality present the possibility of "replacing kernel modules as the de-facto means of extending the kernel." Kernel modules make devices, filesystems, crypto, networks, and the like work, and therefore clearly are a facility on which the "just want it to work" user relies. The problem arises that BFP programs have not traditionally been "in-tree" as most open-source kernel modules are. A proposal in spring 2022 to provide support to the vast array of human interface devices (HIDs) like mice and keyboards via tiny BPF programs rather than patches to device drivers brought the issue into sharp focus.
A rather heated discussion followed, but the issue was apparently settled by Torvalds' comments at Open Source Summit:
He specified if you break 'real user space tools, that normal (non-kernel developers) users use,' then you need to fix it, regardless of whether it is using eBPF or not.
A consensus appears to be forming that developers who expect their BPF programs to withstand kernel updates will need to submit them to an as-yet unspecified place in the kernel source repository. Stay tuned to find out what policy the kernel community adopts regarding BPF and ABI stability.
Conclusion
The kernel ABI stability guarantee applies to procfs, sysfs, and the system call interface, with important exceptions. When "in-tree" code or userspace applications are "broken" by kernel changes, the offending patches are typically quickly reverted. When proprietary code relies on kernel implementation details that are incidentally accessible from userspace, it is not protected and garners little sympathy when it breaks. When, as with Y2038, there is no way to avoid an ABI break, the transition is made as thoughtfully and methodically as possible. Newer features like BPF programs present as-yet-unanswered questions about where exactly the ABI-stability border lies.
Acknowledgments
Thanks to Akkana Peck, Sarah R. Newman, and Luke S. Crawford for their helpful comments on early versions of this material.





Comments are closed.