

Distributed databases are common for many reasons. They increase reliability, redundancy, and performance. Apache ShardingSphere is an open source framework that enables you to transform any database into a distributed database. Since the release of ShardingSphere 5.0.0, DistSQL (Distributed SQL) has provided dynamic management for the ShardingSphere ecosystem.
In this article, I demonstrate a data sharding scenario in which DistSQL's flexibility allows you to create a distributed database. At the same time, I show some syntax sugar to simplify operating procedures, allowing your potential users to choose their preferred syntax.
A series of DistSQL statements are run through practical cases to give you a complete set of practical DistSQL sharding management methods, which create and maintain distributed databases through dynamic management.
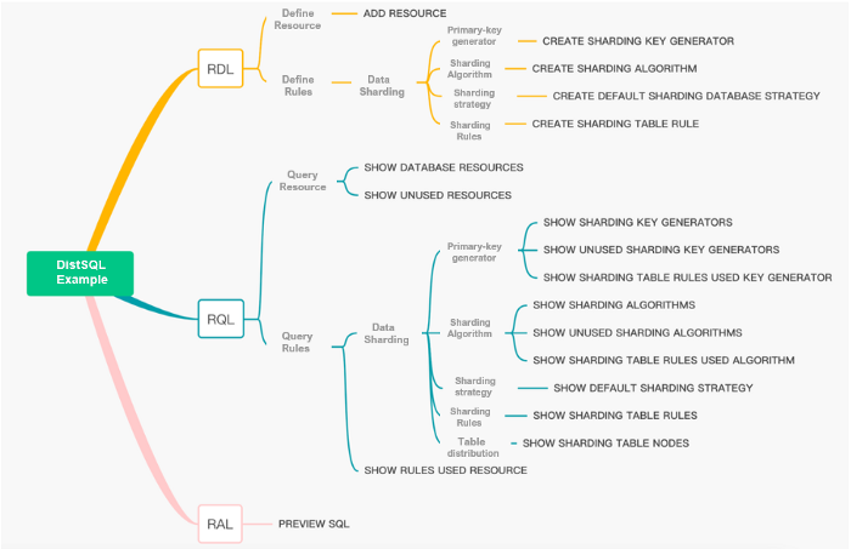
(Jiang Longtao, CC BY-SA 4.0)
What is sharding?
In database terminology, sharding is the process of partitioning a table into separate entities. While the table data is directly related, it often exists on different physical database nodes or, at the very least, within separate logical partitions.
Practical case example
To follow along with this example, you must have these components in place, either in your lab or in your mind as you read this article:
- Two sharding tables: t_order and t_order_item.
- For both tables, database shards are carried out with the user_id field, and table shards with the order_id field.
- The number of shards is two databases times three tables.
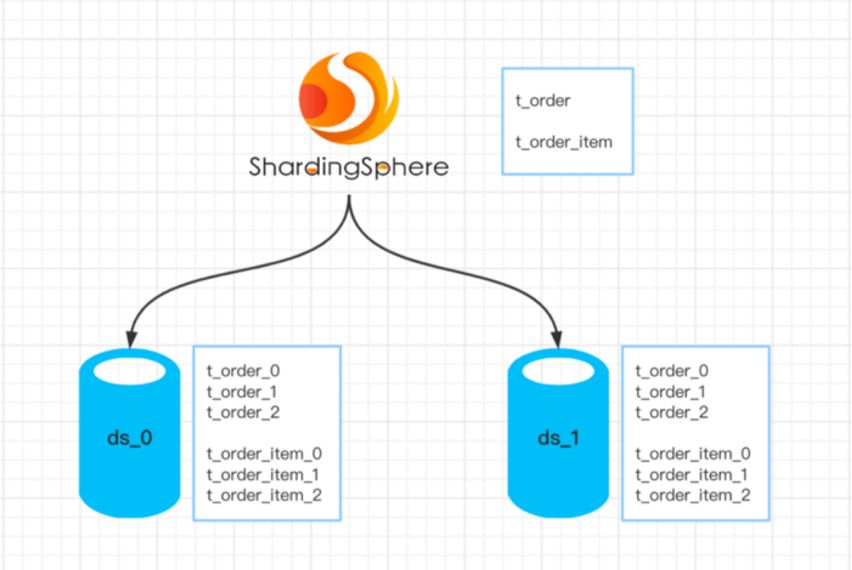
(Jiang Longtao, CC BY-SA 4.0)
Set up the environment
1. Prepare a database (MySQL, MariaDB, PostgreSQL, or openGauss) instance for access. Create two new databases: demo_ds_0 and demo_ds_1.
2. Deploy Apache ShardingSphere-Proxy 5.1.2 and Apache ZooKeeper. ZooKeeper acts as a governance center and stores ShardingSphere metadata information.
3. Configure server.yaml in the Proxy conf directory as follows:
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181 #ZooKeeper address
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: falserules:
- !AUTHORITY
users:
- root@%:root4. Start ShardingSphere-Proxy and connect it to Proxy using a client, for example:
$ mysql -h 127.0.0.1 -P 3307 -u root -p5. Create a distributed database:
CREATE DATABASE sharding_db;USE sharding_db;Add storage resources
Next, add storage resources corresponding to the database:
ADD RESOURCE ds_0 (
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_0,
USER=root,
PASSWORD=123456
), ds_1(
HOST=127.0.0.1,
PORT=3306,
DB=demo_ds_1,
USER=root,
PASSWORD=123456
);View the storage resources:
mysql> SHOW DATABASE RESOURCES\G;
******** 1. row ***************************
name: ds_1
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_1
-- Omit partial attributes
******** 2. row ***************************
name: ds_0
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_0
-- Omit partial attributesAdding the optional \G switch to the query statement makes the output format easy to read.
Create sharding rules
ShardingSphere's sharding rules support regular sharding and automatic sharding. Both sharding methods have the same effect. The difference is that the configuration of automatic sharding is more concise, while regular sharding is more flexible and independent.
Refer to the following links for more details on automatic sharding:
- Intro to DistSQL-An Open Source and More Powerful SQL
- AutoTable: Your Butler-Like Sharding Configuration Tool
Next, it's time to adopt regular sharding and use the INLINE expression algorithm to implement the sharding scenarios described in the requirements.
Primary key generator
The primary key generator creates a secure and unique primary key for a data table in a distributed scenario. For details, refer to the document Distributed Primary Key.
1. Create a primary key generator:
CREATE SHARDING KEY GENERATOR snowflake_key_generator (
TYPE(NAME=SNOWFLAKE)
);2. Query the primary key generator:
mysql> SHOW SHARDING KEY GENERATORS;
+-------------------------+-----------+-------+
| name | type | props |
+-------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
+-------------------------+-----------+-------+
1 row in set (0.01 sec)Sharding algorithm
1. Create a database sharding algorithm used by t_order and t_order_item in common:
-- Modulo 2 based on user_id in database sharding
CREATE SHARDING ALGORITHM database_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}"))
);2. Create different table shards algorithms for t_order and t_order_item:
-- Modulo 3 based on order_id in table sharding
CREATE SHARDING ALGORITHM t_order_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_${order_id % 3}"))
);
CREATE SHARDING ALGORITHM t_order_item_inline (
TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_item_${order_id % 3}"))
);3. Query the sharding algorithm:
mysql> SHOW SHARDING ALGORITHMS;
+---------------------+--------+---------------------------------------------------+
| name | type | props |
+---------------------+--------+---------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
+---------------------+--------+---------------------------------------------------+
3 rows in set (0.00 sec)Create a default sharding strategy
The sharding strategy consists of a sharding key and sharding algorithm, which in this case is databaseStrategy and tableStrategy. Because t_order and t_order_item have the same database sharding field and sharding algorithm, create a default strategy to be used by all shard tables with no sharding strategy configured.
1. Create a default database sharding strategy:
CREATE DEFAULT SHARDING DATABASE STRATEGY (
TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM=database_inline
);2. Query default strategy:
mysql> SHOW DEFAULT SHARDING STRATEGY\G;
*************************** 1. row ***************************
name: TABLE
type: NONE
sharding_column:
sharding_algorithm_name:
sharding_algorithm_type:
sharding_algorithm_props:
*************************** 2. row ***************************
name: DATABASE
type: STANDARD
sharding_column: user_id
sharding_algorithm_name: database_inline
sharding_algorithm_type: inline
sharding_algorithm_props: {algorithm-expression=ds_${user_id % 2}}
2 rows in set (0.00 sec)You have not configured the default table sharding strategy, so the default strategy of TABLE is NONE.
Set sharding rules
The primary key generator and sharding algorithm are both ready. Now you can create sharding rules. The method I demonstrate below is a little complicated and involves multiple steps. In the next section, I'll show you how to create sharding rules in just one step, but for now, witness how it's typically done.
First, define t_order:
CREATE SHARDING TABLE RULE t_order (
DATANODES("ds_${0..1}.t_order_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_id,KEY_GENERATOR=snowflake_key_generator)
);Here is an explanation of the values found above:
- DATANODES specifies the data nodes of shard tables.
- TABLE_STRATEGY specifies the table strategy, among which SHARDING_ALGORITHM uses created sharding algorithm t_order_inline.
- KEY_GENERATE_STRATEGY specifies the primary key generation strategy of the table. Skip this configuration if primary key generation is not required.
Next, define t_order_item:
CREATE SHARDING TABLE RULE t_order_item (
DATANODES("ds_${0..1}.t_order_item_${0..2}"),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM=t_order_item_inline),
KEY_GENERATE_STRATEGY(COLUMN=order_item_id,KEY_GENERATOR=snowflake_key_generator)
);Query the sharding rules to verify what you've created:
mysql> SHOW SHARDING TABLE RULES\G;
************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:
*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:
2 rows in set (0.00 sec)This looks right so far. You have now configured the sharding rules for t_order and t_order_item.
You can skip the steps for creating the primary key generator, sharding algorithm, and default strategy, and complete the sharding rules in one step. Here's how to make it easier.
Sharding rule syntax
For instance, if you want to add a shard table called t_order_detail, you can create sharding rules as follows:
CREATE SHARDING TABLE RULE t_order_detail (
DATANODES("ds_${0..1}.t_order_detail_${0..1}"),
DATABASE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=user_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}")))),
TABLE_STRATEGY(TYPE=STANDARD,SHARDING_COLUMN=order_id,SHARDING_ALGORITHM(TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="t_order_detail_${order_id % 3}")))),
KEY_GENERATE_STRATEGY(COLUMN=detail_id,TYPE(NAME=snowflake))
);This statement specifies a database sharding strategy, table strategy, and primary key generation strategy, but it doesn't use existing algorithms. The DistSQL engine automatically uses the input expression to create an algorithm for the sharding rules of t_order_detail.
Now there's a primary key generator:
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+
| name | type | props |
+--------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
| t_order_detail_snowflake | snowflake | {} |
+--------------------------+-----------+-------+
2 rows in set (0.00 sec)Display the sharding algorithm:
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+
| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
| t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
+--------------------------------+--------+-----------------------------------------------------+
5 rows in set (0.00 sec)And finally, the sharding rules:
mysql> SHOW SHARDING TABLE RULES\G;
*************************** 1. row ***************************
table: t_order
actual_data_nodes: ds_${0..1}.t_order_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_${order_id % 3}
key_generate_column: order_id
key_generator_type: snowflake
key_generator_props:
*************************** 2. row ***************************
table: t_order_item
actual_data_nodes: ds_${0..1}.t_order_item_${0..2}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_item_${order_id % 3}
key_generate_column: order_item_id
key_generator_type: snowflake
key_generator_props:
*************************** 3. row ***************************
table: t_order_detail
actual_data_nodes: ds_${0..1}.t_order_detail_${0..1}
actual_data_sources:
database_strategy_type: STANDARD
database_sharding_column: user_id
database_sharding_algorithm_type: inline
database_sharding_algorithm_props: algorithm-expression=ds_${user_id % 2}
table_strategy_type: STANDARD
table_sharding_column: order_id
table_sharding_algorithm_type: inline
table_sharding_algorithm_props: algorithm-expression=t_order_detail_${order_id % 3}
key_generate_column: detail_id
key_generator_type: snowflake
key_generator_props:
3 rows in set (0.01 sec)In the CREATE SHARDING TABLE RULE statement, DATABASE_STRATEGY, TABLE_STRATEGY, and KEY_GENERATE_STRATEGY can reuse existing algorithms.
Alternatively, they can be defined quickly through syntax. The difference is that additional algorithm objects are created.
Configuration and verification
Once you have created the configuration verification rules, you can verify them in the following ways.
1. Check node distribution:
DistSQL provides SHOW SHARDING TABLE NODES for checking node distribution, and users can quickly learn the distribution of shard tables:
mysql> SHOW SHARDING TABLE NODES;
+----------------+------------------------------------------------------------------------------------------------------------------------------+
| name | nodes |
+----------------+------------------------------------------------------------------------------------------------------------------------------+
| t_order | ds_0.t_order_0, ds_0.t_order_1, ds_0.t_order_2, ds_1.t_order_0, ds_1.t_order_1, ds_1.t_order_2 |
| t_order_item | ds_0.t_order_item_0, ds_0.t_order_item_1, ds_0.t_order_item_2, ds_1.t_order_item_0, ds_1.t_order_item_1, ds_1.t_order_item_2 |
| t_order_detail | ds_0.t_order_detail_0, ds_0.t_order_detail_1, ds_1.t_order_detail_0, ds_1.t_order_detail_1 |
+----------------+------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.01 sec)
mysql> SHOW SHARDING TABLE NODES t_order_item;
+--------------+------------------------------------------------------------------------------------------------------------------------------+
| name | nodes |
+--------------+------------------------------------------------------------------------------------------------------------------------------+
| t_order_item | ds_0.t_order_item_0, ds_0.t_order_item_1, ds_0.t_order_item_2, ds_1.t_order_item_0, ds_1.t_order_item_1, ds_1.t_order_item_2 |
+--------------+------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)You can see that the node distribution of the shard table is consistent with what is described in the requirement.
SQL preview
Previewing SQL is also an easy way to verify configurations. Its syntax is PREVIEW SQL. First, make a query with no shard key, with all routes:
mysql> PREVIEW SELECT * FROM t_order;
+------------------+---------------------------------------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+---------------------------------------------------------------------------------------------+
| ds_0 | SELECT * FROM t_order_0 UNION ALL SELECT * FROM t_order_1 UNION ALL SELECT * FROM t_order_2 |
| ds_1 | SELECT * FROM t_order_0 UNION ALL SELECT * FROM t_order_1 UNION ALL SELECT * FROM t_order_2 |
+------------------+---------------------------------------------------------------------------------------------+
2 rows in set (0.13 sec)
mysql> PREVIEW SELECT * FROM t_order_item;
+------------------+------------------------------------------------------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+------------------------------------------------------------------------------------------------------------+
| ds_0 | SELECT * FROM t_order_item_0 UNION ALL SELECT * FROM t_order_item_1 UNION ALL SELECT * FROM t_order_item_2 |
| ds_1 | SELECT * FROM t_order_item_0 UNION ALL SELECT * FROM t_order_item_1 UNION ALL SELECT * FROM t_order_item_2 |
+------------------+------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)Now specify user_id in a query with a single database route:
mysql> PREVIEW SELECT * FROM t_order WHERE user_id = 1;
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+
| ds_1 | SELECT * FROM t_order_0 WHERE user_id = 1 UNION ALL SELECT * FROM t_order_1 WHERE user_id = 1 UNION ALL SELECT * FROM t_order_2 WHERE user_id = 1 |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.14 sec)
mysql> PREVIEW SELECT * FROM t_order_item WHERE user_id = 2;
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ds_0 | SELECT * FROM t_order_item_0 WHERE user_id = 2 UNION ALL SELECT * FROM t_order_item_1 WHERE user_id = 2 UNION ALL SELECT * FROM t_order_item_2 WHERE user_id = 2 |
+------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Specify user_id and order_id with a single table route:
mysql> PREVIEW SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
+------------------+------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+------------------------------------------------------------+
| ds_1 | SELECT * FROM t_order_1 WHERE user_id = 1 AND order_id = 1 |
+------------------+------------------------------------------------------------+
1 row in set (0.04 sec)
mysql> PREVIEW SELECT * FROM t_order_item WHERE user_id = 2 AND order_id = 5;
+------------------+-----------------------------------------------------------------+
| data_source_name | actual_sql |
+------------------+-----------------------------------------------------------------+
| ds_0 | SELECT * FROM t_order_item_2 WHERE user_id = 2 AND order_id = 5 |
+------------------+-----------------------------------------------------------------+
1 row in set (0.01 sec)Single-table routes scan the fewest shard tables and offer the highest efficiency.
Query unused resources
During system maintenance, algorithms or storage resources that are no longer in use may need to be released, or resources that need to be released may have been referenced and cannot be deleted. DistSQL's SHOW UNUSED RESOURCES command can solve these problems:
mysql> ADD RESOURCE ds_2 (
-> HOST=127.0.0.1,
-> PORT=3306,
-> DB=demo_ds_2,
-> USER=root,
-> PASSWORD=123456
-> );
Query OK, 0 rows affected (0.07 sec)
mysql> SHOW UNUSED RESOURCES\G;
*************************** 1. row ***************************
name: ds_2
type: MySQL
host: 127.0.0.1
port: 3306
db: demo_ds_2
connection_timeout_milliseconds: 30000
idle_timeout_milliseconds: 60000
max_lifetime_milliseconds: 2100000
max_pool_size: 50
min_pool_size: 1
read_only: false
other_attributes: {"dataSourceProperties":{"cacheServerConfiguration":"true","elideSetAutoCommits":"true","useServerPrepStmts":"true","cachePrepStmts":"true","useSSL":"false","rewriteBatchedStatements":"true","cacheResultSetMetadata":"false","useLocalSessionState":"true","maintainTimeStats":"false","prepStmtCacheSize":"200000","tinyInt1isBit":"false","prepStmtCacheSqlLimit":"2048","serverTimezone":"UTC","netTimeoutForStreamingResults":"0","zeroDateTimeBehavior":"round"},"healthCheckProperties":{},"initializationFailTimeout":1,"validationTimeout":5000,"leakDetectionThreshold":0,"poolName":"HikariPool-8","registerMbeans":false,"allowPoolSuspension":false,"autoCommit":true,"isolateInternalQueries":false}
1 row in set (0.03 sec)Query unused primary key generator
DistSQL can also display unused sharding key generators with the SHOW UNUSED SHARDING KEY GENERATORS:
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+
| name | type | props |
+--------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
| t_order_detail_snowflake | snowflake | {} |
+--------------------------+-----------+-------+
2 rows in set (0.00 sec)
mysql> SHOW UNUSED SHARDING KEY GENERATORS;
Empty set (0.01 sec)
mysql> CREATE SHARDING KEY GENERATOR useless (
-> TYPE(NAME=SNOWFLAKE)
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> SHOW UNUSED SHARDING KEY GENERATORS;
+---------+-----------+-------+
| name | type | props |
+---------+-----------+-------+
| useless | snowflake | |
+---------+-----------+-------+
1 row in set (0.01 sec)Query unused sharding algorithm
DistSQL can reveal unused sharding algorithms with (you guessed it) the SHOW UNUSED SHARDING ALGORITHMS command:
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+
| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
| t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
+--------------------------------+--------+-----------------------------------------------------+
5 rows in set (0.00 sec)
mysql> CREATE SHARDING ALGORITHM useless (
-> TYPE(NAME=INLINE,PROPERTIES("algorithm-expression"="ds_${user_id % 2}"))
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> SHOW UNUSED SHARDING ALGORITHMS;
+---------+--------+----------------------------------------+
| name | type | props |
+---------+--------+----------------------------------------+
| useless | inline | algorithm-expression=ds_${user_id % 2} |
+---------+--------+----------------------------------------+
1 row in set (0.00 sec)Query rules that use the target storage resources
You can also see used resources within rules with SHOW RULES USED RESOURCE. All rules that use a resource can be queried, not limited to the sharding rule.
mysql> DROP RESOURCE ds_0;
ERROR 1101 (C1101): Resource [ds_0] is still used by [ShardingRule].
mysql> SHOW RULES USED RESOURCE ds_0;
+----------+----------------+
| type | name |
+----------+----------------+
| sharding | t_order |
| sharding | t_order_item |
| sharding | t_order_detail |
+----------+----------------+
3 rows in set (0.00 sec)Query sharding rules that use the target primary key generator
You can find sharding rules using a key generator with SHOW SHARDING TABLE RULES USED KEY GENERATOR:
mysql> SHOW SHARDING KEY GENERATORS;
+--------------------------+-----------+-------+
| name | type | props |
+--------------------------+-----------+-------+
| snowflake_key_generator | snowflake | {} |
| t_order_detail_snowflake | snowflake | {} |
| useless | snowflake | {} |
+--------------------------+-----------+-------+
3 rows in set (0.00 sec)
mysql> DROP SHARDING KEY GENERATOR snowflake_key_generator;
ERROR 1121 (C1121): Sharding key generator `[snowflake_key_generator]` in database `sharding_db` are still in used.
mysql> SHOW SHARDING TABLE RULES USED KEY GENERATOR snowflake_key_generator;
+-------+--------------+
| type | name |
+-------+--------------+
| table | t_order |
| table | t_order_item |
+-------+--------------+
2 rows in set (0.00 sec)Query sharding rules that use the target algorithm
Show sharding rules using a target algorithm with SHOW SHARDING TABLE RULES USED ALGORITHM:
mysql> SHOW SHARDING ALGORITHMS;
+--------------------------------+--------+-----------------------------------------------------+
| name | type | props |
+--------------------------------+--------+-----------------------------------------------------+
| database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_inline | inline | algorithm-expression=t_order_${order_id % 3} |
| t_order_item_inline | inline | algorithm-expression=t_order_item_${order_id % 3} |
| t_order_detail_database_inline | inline | algorithm-expression=ds_${user_id % 2} |
| t_order_detail_table_inline | inline | algorithm-expression=t_order_detail_${order_id % 3} |
| useless | inline | algorithm-expression=ds_${user_id % 2} |
+--------------------------------+--------+-----------------------------------------------------+
6 rows in set (0.00 sec)
mysql> DROP SHARDING ALGORITHM t_order_detail_table_inline;
ERROR 1116 (C1116): Sharding algorithms `[t_order_detail_table_inline]` in database `sharding_db` are still in used.
mysql> SHOW SHARDING TABLE RULES USED ALGORITHM t_order_detail_table_inline;
+-------+----------------+
| type | name |
+-------+----------------+
| table | t_order_detail |
+-------+----------------+
1 row in set (0.00 sec)Make sharding better
DistSQL provides a flexible syntax to help simplify operations. In addition to the INLINE algorithm, DistSQL supports standard sharding, compound sharding, HINT sharding, and custom sharding algorithms.
If you have any questions or suggestions about Apache ShardingSphere, please feel free to post them on ShardingSphereGitHub.





Comments are closed.