

Historians and detectives share many similarities: their investigations are laborious and focused on small details. Bits of information are often murky, contradictory, and complex. Peoples' names might be spelled differently across different sources, especially if more than one language is involved. There's also a time component—they need to know where every possible culprit was at every certain point in time. In the end, they might find out that it was not one gardener who killed the old lady, but two.
Traditionally, historians (and detectives) have kept such information in their heads and on note cards, crumpled pieces of paper, glossed entries of copied books, and the like. Historical researchers are starting to acknowledge that computers might be around long enough to prove they are not a short-lived phenomenon (to them, short-term means 100 years or less), and the emergence of digital humanities as a separate field of research proves this.

Conceptual example of a historical semantic network. By Maximilian Kalus. CC BY-NC-ND.
Segrada is a piece of open source software that allows historians (and detectives) to keep track of their data. Unlike wikis or archival databases, its focus lies on information and interrelations within it. Pieces of information might represent persons, places, things, or concepts. These "nodes" can be bidirectionally connected with each other to semantically represent friendship, blood relation, whereabouts, authorship, and so on. Hence the term "semantic graph database," since information can be displayed as a graph of semantically connected nodes.
The above image suggests how such a historical semantic network might look like. There are several different types of nodes representing locations and persons. Nodes are connected by graphs that can be easily grasped by a human reader. The graphs are bi-directional, meaning they can be interpreted in both directions. The figure also depicts dates, some of which are partial (just years, for example). Segrada supports partial and fuzzy dates, as well as tags and geographic references. What the figure does not show is the textual description of nodes and relation, or source references that save the origin of the information. These features are supported by the databases. Moreover, files can be uploaded into the database and full-text indexed if needed. This makes it possible to not only search the database contents, but referenced texts as well.
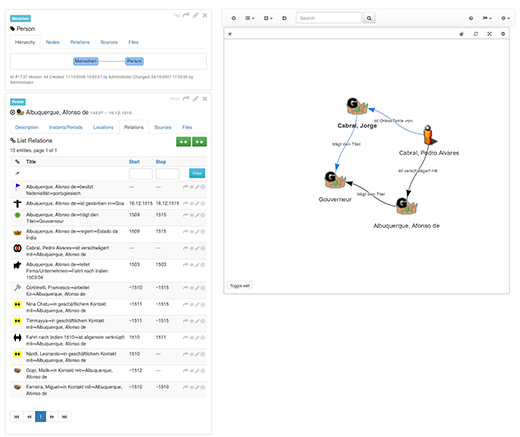
The original purpose of Segrada was to support historians in gradually piecing together historical data in order to eventually build networks of people. A predecessor of the current database was developed as part of a PhD thesis covering German and Italian investor networks in the Portuguese trade with Asia during the 16th century. In the course of the study, around 1,400 nodes were created and connected by almost 6,800 relations.
While this might seem small by database standards, it shows what a single historian can tediously piece together from various sources over four years: Over 1,000 people were recorded, and many new details could be uncovered within a vast network exchanging Indian pepper, Asian spices, Tyrolean and Hungarian copper, Pomeranian grain, and bills of exchange (mostly in Lyon) operated by Portuguese, German, Italian, and Spanish merchants. The above image shows a typical screen shot depicting a part of the network of the Portuguese explorer and viceroy Afonso de Albuquerque as created in the course of the research.
Segrada is available to anyone, not just historians and detectives. It might also be used by genealogists, knowledge workers structuring arbitrary information, or people trying to figure out the relationships and places in Game of Thrones. The software is web-based, but can be run from the desktop. Other than Java, there are no additional requirements on the operating system. This makes it easy for normal users to utilize the software in a convenient way, although it can also be run on one or more servers to grant access to a team of people collaborating on a single project.
It should be noted that Segrada is a fairly new project and still in beta. You don't have to be a detective to join—coding, support, documentation, testing, and feedback are all highly welcome. The project's source code can be found on GitHub and binary downloads are available on the official project website.





1 Comment