

A big problem with supervised machine learning is the need for huge amounts of labeled data. It's a big problem especially if you don't have the labeled data—and even in a world awash with big data, most of us don't.
Although a few companies have access to enormous quantities of certain kinds of labeled data, for most organizations and many applications, creating sufficient quantities of the right kind of labeled data is cost prohibitive or impossible. Sometimes the domain is one in which there just isn't much data (for example, when diagnosing a rare disease or determining whether a signature matches a few known exemplars). Other times the volume of data needed multiplied by the cost of human labeling by Amazon Turkers or summer interns is just too high. Paying to label every frame of a movie-length video adds up fast, even at a penny a frame.
The big problem of big data requirements
The specific problem our group set out to solve was: Can we train a model to automate applying a simple color scheme to a black and white character without hand-drawing hundreds or thousands of examples as training data?
In this experiment (which we called DragonPaint), we confronted the problem of deep learning's enormous labeled-data requirements using:
- A rule-based strategy for extreme augmentation of small datasets
- A borrowed TensorFlow image-to-image translation model, Pix2Pix, to automate cartoon coloring with very limited training data
I had seen Pix2Pix, a machine learning image-to-image translation model described in a paper ("Image-to-Image Translation with Conditional Adversarial Networks," by Isola, et al.), that colorizes landscapes after training on AB pairs where A is the grayscale version of landscape B. My problem seemed similar. The only problem was training data.
I needed the training data to be very limited because I didn't want to draw and color a lifetime supply of cartoon characters just to train the model. The tens of thousands (or hundreds of thousands) of examples often required by deep-learning models were out of the question.
Based on Pix2Pix's examples, we would need at least 400 to 1,000 sketch/colored pairs. How many was I willing to draw? Maybe 30. I drew a few dozen cartoon flowers and dragons and asked whether I could somehow turn this into a training set.
The 80% solution: color by component

opensource.com
When faced with a shortage of training data, the first question to ask is whether there is a good non-machine-learning based approach to our problem. If there's not a complete solution, is there a partial solution, and would a partial solution do us any good? Do we even need machine learning to color flowers and dragons? Or can we specify geometric rules for coloring?

opensource.com
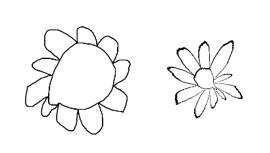
There is a non-machine-learning approach to solving my problem. I could tell a kid how I want my drawings colored: Make the flower's center orange and the petals yellow. Make the dragon's body orange and the spikes yellow.
At first, that doesn't seem helpful because our computer doesn't know what a center or a petal or a body or a spike is. But it turns out we can define the flower or dragon parts in terms of connected components and get a geometric solution for coloring about 80% of our drawings. Although 80% isn't enough, we can bootstrap from that partial-rule-based solution to 100% using strategic rule-breaking transformations, augmentations, and machine learning.
Connected components are what is colored when you use Windows Paint (or a similar application). For example, when coloring a binary black and white image, if you click on a white pixel, the white pixels that are be reached without crossing over black are colored the new color. In a "rule-conforming" cartoon dragon or flower sketch, the biggest white component is the background. The next biggest is the body (plus the arms and legs) or the flower's center. The rest are spikes or petals, except for the dragon's eye, which can be distinguished by its distance from the background.
Using strategic rule breaking and Pix2Pix to get to 100%
Some of my sketches aren't rule-conforming. A sloppily drawn line might leave a gap. A back limb will get colored like a spike. A small, centered daisy will switch a petal and the center's coloring rules.

opensource.com
For the 20% we couldn't color with the geometric rules, we needed something else. We turned to Pix2Pix, which requires a minimum training set of 400 to 1,000 sketch/colored pairs (i.e., the smallest training sets in the Pix2Pix paper) including rule-breaking pairs.
So, for each rule-breaking example, we finished the coloring by hand (e.g., back limbs) or took a few rule-abiding sketch/colored pairs and broke the rule. We erased a bit of a line in A or we transformed a fat, centered flower pair A and B with the same function (f) to create a new pair f(A) and f(B)—a small, centered flower. That got us to a training set.
Extreme augmentations with gaussian filters and homeomorphisms
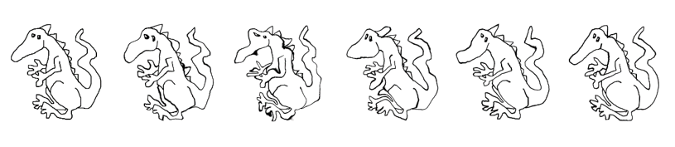
It's common in computer vision to augment an image training set with geometric transformations, such as rotation, translation, and zoom.
But what if we need to turn sunflowers into daisies or make a dragon's nose bulbous or pointy?
Or what if we just need an enormous increase in data volume without overfitting? Here we need a dataset 10 to 30 times larger than what we started with.
opensource.com
opensource.com
Certain homeomorphisms of the unit disk make good daisies (e.g., r -> r cubed) and Gaussian filters change a dragon's nose. Both were extremely useful for creating augmentations for our dataset and produced the augmentation volume we needed, but they also started to change the style of the drawings in ways that an affine transformation could not.
This inspired questions beyond how to automate a simple coloring scheme: What defines an artist's style, either to an outside viewer or the artist? When does an artist adopt as their own a drawing they could not have made without the algorithm? When does the subject matter become unrecognizable? What's the difference between a tool, an assistant, and a collaborator?
How far can we go?
How little can we draw for input and how much variation and complexity can we create while staying within a subject and style recognizable as the artist's? What would we need to do to make an infinite parade of giraffes or dragons or flowers? And if we had one, what could we do with it?
Those are questions we'll continue to explore in future work.
But for now, the rules, augmentations, and Pix2Pix model worked. We can color flowers really well, and the dragons aren't bad.

opensource.com

opensource.com
To learn more, attend Gretchen Greene's talk, DragonPaint – bootstrapping small data to color cartoons, at PyCon Cleveland 2018.




1 Comment