

This article was co-written with Lindsey Tulloch.
In a world rapidly moving to the cloud, investors, customers, and developers are watching the "cloud wars" with bated breath. As cloud giants rise and the backbone of a new kind of infrastructure is forged before our eyes, it is critical for those of us on the ground to stay agile to maintain our technical and economic edge.
Applications that are portable—able to run seamlessly across operating systems—make sense from both a development and adoption standpoint. Interpreted languages and runtime environments have enabled applications to be run anywhere.
This is expected when talking about operating systems, but how does this translate on a practical level to work across public, private, and hybrid clouds?
Say you have an application deployed in your on-premises private cloud application that you someday plan to move entirely to the public cloud. How do you ensure scalability of your app on public cloud infrastructure? Alternatively, you may have already deployed on a public cloud providers' infrastructure and decide that you no longer want to use that cloud provider due to its costs. How do you avoid vendor lock-in and ensure a smooth transition to a new provider? Whatever solution you choose, change is constant, and software application portability in the cloud is key to making any of these potential future decisions possible.
This is not yet a straightforward exercise. Every cloud provider has its own way of doing things, from supporting APIs to implementing compute, storage, and networking operations. So, how do you write cloud-agnostic application code so it is portable across different cloud infrastructures? One answer to overcoming these provider-specific hurdles involves Kubernetes.
Kubernetes is open source software for "automating deployment, scaling, and management of containerized applications." Kubernetes itself is an abstraction across all infrastructure and cloud providers that enables a simplified approach to orchestrating all of your resources. The feature of Kubernetes that allows for the orchestration of multiple Kubernetes clusters is aptly called multi-cluster. Still in an early pre-alpha phase, multi-cluster (formerly federation) aims to simplify the management of multiple Kubernetes clusters by synchronizing resources across member clusters. Multi-cluster promises high availability through balancing workloads across clusters and increases reliability in the event of a cluster failure. Additionally, it avoids vendor lock-in by giving you the ability to write your application once and deploy it on any single cloud provider or across many cloud providers.
In contrast with the original federation project, which provided a single monolithic control plane to manage multiple federated Kubernetes clusters, the current architecture takes a more compositional approach. Smaller projects like kubemci, cluster-registry, and federation-v2 prototyping efforts are tackling the fundamental elements of federation—management of ingresses, access to individual clusters, and workload distribution—to build a federation ecosystem from the ground up to give users more control over how applications are distributed and scaled across a multi-cluster network.
As engineers working out of the CTO Office at Red Hat, we wanted to test the promise of Kubernetes multi-cluster and explore application portability further. We set out to build a credible reference application to validate portability. This involved building separate Kubernetes clusters in Google Cloud, Amazon Web Services, and Microsoft Azure. Each Kubernetes cluster was created in a different region to test the prospect of high availability.
We arbitrarily selected a Kubernetes cluster hosted in Google Cloud to be the primary cluster and used apiserver-builder to deploy the aggregated federation API server and controller to it. To join the three clusters together, we used kubefnord, a multi-cluster management tool. This gave us three separate Kubernetes clusters spanning three different regions—all managed through the same primary Kubernetes cluster as shown in the diagram below.

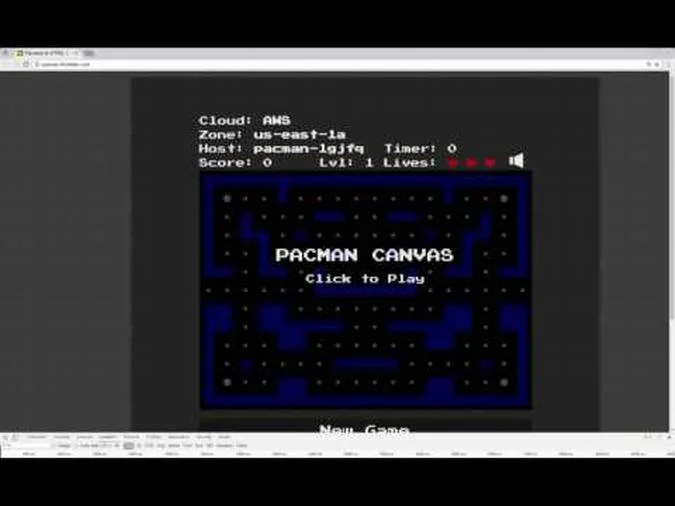
We built a stateful microservices reference web application based on an open source Pac-Man HTML5 game and modified it to use Node.js (chosen for its web server component, ease of debugging, containerization capabilities, and to facilitate as our backend API). We used MongoDB as the distributed database to persist the high-score data for the stateful piece. We made our Pac-Man app cloud-aware by displaying details showing the cloud provider name, region, and hostname where the instance was running. Lastly, we containerized Pac-Man and MongoDB using Red Hat Enterprise Linux as the container operating system.
To provide MongoDB with a persistent volume to store user data such as high scores, we used the default storage class in each of the clusters that enables the use of each of the cloud providers' block storage capability: Google Persistent Disk, Amazon Elastic Block Storage, and Azure Disk. We created a PersistentVolumeClaim (PVC) so the MongoDB deployment could simply request a storage volume by referencing the PVC, and Kubernetes would provide a dynamically provisioned volume. We subsequently deployed containerized MongoDB onto the federated Kubernetes clusters by building a distributed MongoDB set so that the high-score data would be replicated across to each of the Kubernetes clusters in the federation. We then mapped each of the load balancer IP addresses for the MongoDB services in each of the clusters to DNS entries for load balancing and high availability.
After containerizing Pac-Man, we deployed it, along with containerized MongoDB, to the three Kubernetes clusters. This involved mapping each of the load balancer IP addresses for the Pac-Man services in each of the clusters to DNS entries. The final result looked like this:

Now we've successfully scaled our application across the three largest public cloud providers! This example could have included an on-premises private cloud easily enough. But what if we wanted to scale down our application from a particular cloud provider?
To verify that use case, we deployed our app with the same steps outlined above, except this time only on Google Cloud Platform and Amazon Web Services. Once the application was deployed on both providers, we updated our placement preferences for the Kubernetes YAML resource to reflect that we wanted the Pac-Man application running only on Google Cloud Platform. After applying the change through the federation interface, the Pac-Man application deployment quickly updated to be running only on our Google Cloud Platform Kubernetes cluster. Our scale-down was a success!
opensource.com
As demonstrated by our brief walkthrough, Kubernetes federation-v2 enables software application portability. What's important is that Kubernetes provides a common platform that can be used across any cloud provider. When you add multi-cluster features to the mix, you can write your application code once and deploy it across any combination of cloud providers. So you can rest assured knowing that the application code you write today can be easily deployed across cloud providers as long as there is one common denominator: Kubernetes.
This article is based on "Exploring application portability across clouds using Kubernetes," a talk the authors will be giving at Red Hat Summit 2018, which will be held May 8-10 in San Francisco. Register by May 7 to save US$ 500 off of registration. Use discount code OPEN18 on the payment page to apply the discount.






Comments are closed.