

Git has become the default way to store and transport code in the DevOps generation. Over 93% of developers report that Git is their primary version control system. Almost anyone who has used version control is familiar with git add, git commit, and git push. For most users, that’s all they ever plan to do with Git, and they're comfortable with that. It just works for their needs.
However, from time to time, almost everyone encounters the need to do something a little more advanced, like git rebase or git cherry-pick or work in a detached head state. This is where many devs start to get a bit nervous.
[ Read next How to reset, revert, and return to previous states in Git ]
I'm here to tell you it is ok! Everyone who has or will ever use Git will likely go through those same pangs of panic.
Git is awesome, but it's also intimidating to learn, and it can feel downright confusing sometimes. Git is unlike almost anything else in computer science. You typically learn it piecemeal, specifically in the context of other coding work. Most developers I have met have never formally studied Git beyond perhaps a quick tutorial.
Git is open source, meaning you have the freedom to examine the code and see how it works. It's written mainly in C which, for many devs and people learning computer science, can make it hard to understand. At the same time, the documentation uses terms like massage parameters and commit-ish. It can feel a little baffling. You might feel like Git was written for an advanced Linux professional. That is because it originally was.
A brief Git history
Git started as a specific set of scripts for Linus Torvalds to use to manage patches.
Here's how he introduced what would become Git to the Linux kernel mailing list:
So I'm writing some scripts to try to track things a whole lot faster. Initial indications are that I should be able to do it almost as quickly as I can just apply the patch, but quite frankly, I'm at most half done, and if I hit a snag, maybe that's not true at all. Anyway, the reason I can do it quickly is that my scripts will _not_ be an SCM, they'll be a very specific "log Linus' state" kind of thing. That will make the linear patch merge a lot more time-efficient, and thus possible.
One of the first things I do when I get confused about how Git works is to imagine why and how Linus would apply it to managing patches. It has grown to handle a lot more than that and is indeed a full SCM, but remembering the first use case is helpful in understanding the "why" sometimes.
Git commit
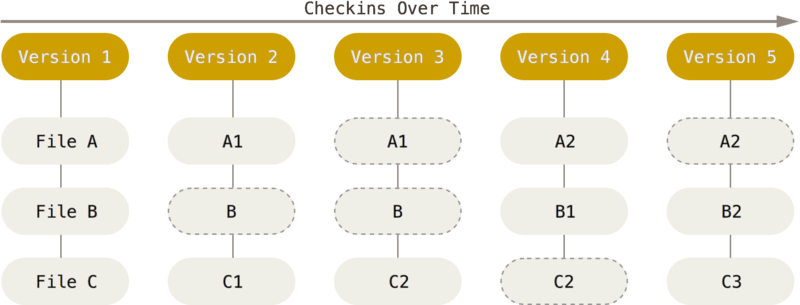
The core conceptual unit of work in Git is the commit. These are snapshots of the files being tracked within your project folder ( where the .git folder lives.)
(Git-scm.com, CC BY-NC-SA 3.0)
It's important to remember that Git stores compressed snapshots of the file system, not diffs. Any time you change a file, a whole new compressed version of that file is made and stored in that commit. It does this by creating a super compressed Binary Large Object (blob) out of the file, and then keeping track of it by generating a checksum made with the SHA hashing algorithm. The permanence of your Git history is one of the reasons it's vital never to store or hardcode sensitive data in your Git projects. Anyone who can clone the repo has full access to all the versions of the files.
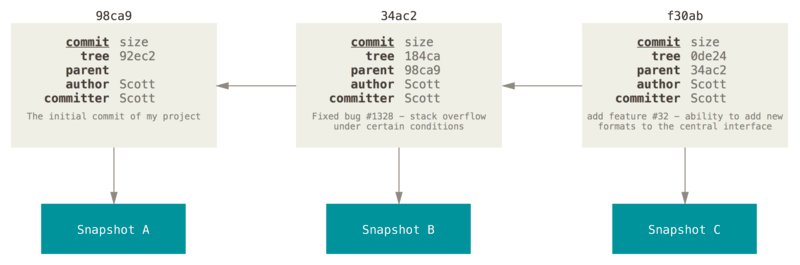
Git is really efficient. If a file does not change between commits, Git does not make a whole new compressed version for storage. Instead, it just refers back to the previous commit. All commits know what commit came directly before it, called its parents. You can easily see this chain of commits when you run git log.
(Git-scm.com, CC BY-NC-SA 3.0)
You have full control over these chains of commits and can do some pretty cool things with them. You can create, delete, merge and reorder them as you see fit. You can even effectively travel through time, explore and even write your commit histories. But it all relies on understanding how Git sees chains of commits, which are generally referred to as branches.
Git branches
Branching lets you work with multiple chains of commits inside a project. Working with multiple branches (especially when you work with rebase) is where many users start to sweat. A common mental model most people have about what branches even are adds to the confusion.
When thinking about branching, most people conjure up images of swim lanes, diverging, and intersecting dots. While those models can be helpful when understanding specific branching strategies and workflows, thinking of Git as a series of numbered dots on a graph can muddy the waters when trying to think about how Git does what it does.
An alternative mental model I find helpful is to think of branches existing in a big spreadsheet. The first column is the parent commit ID, the second is the new commit ID, and then there are columns for metadata, including all the pointers.
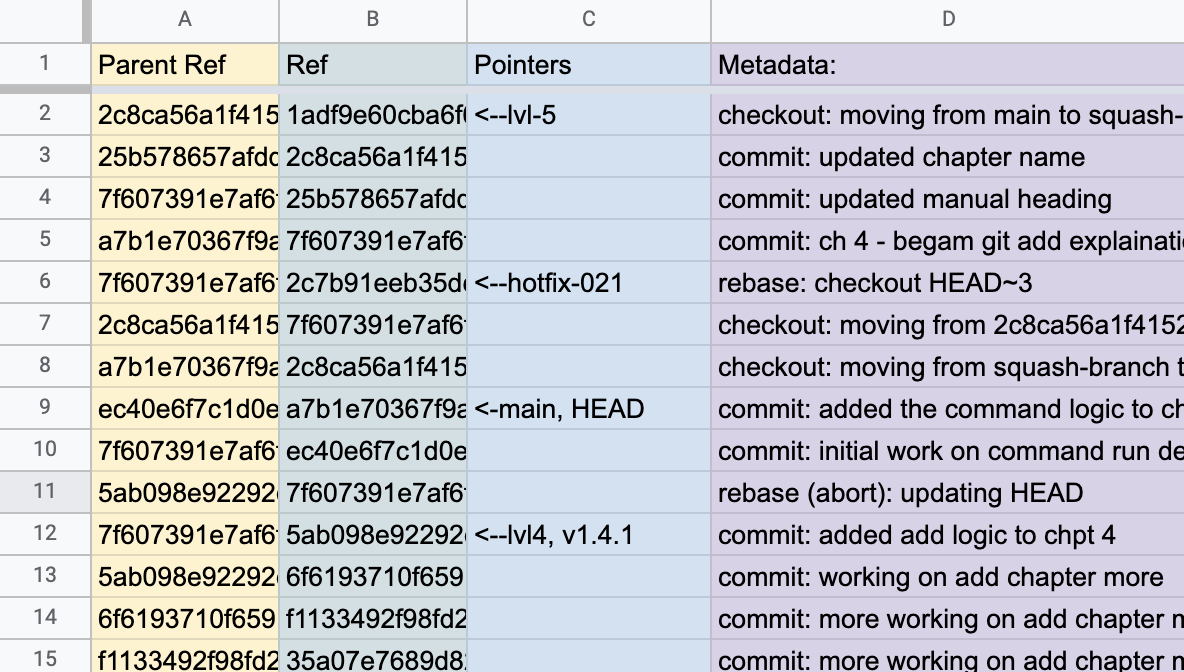
(Dwayne McDaniel, CC BY-SA 4.0)
Pointers keep track of where you are, and which branch is which. Pointers are convenient human-readable references to specific commits. Any reference that leads back to a specific commit is referred to as commit-ish.
The special pointer used to name a branch always points to the newest commit on the chain. You can arbitrarily assign a pointer to any commit with git tag, which doesn't move. When you git checkout or git switch between branches, you're really telling Git that you want to change the point of reference of Git and move a very special pointer called HEAD in every .git folder.
The .git folder
One of the best ways to understand what is going on with Git is to dig into the .git folder. If you've never opened this file before, I highly encourage you to open it up and see what's there. If you're very nervous you might break something, clone an arbitrary open source project to play around with until you feel confident to look into your own project repos.
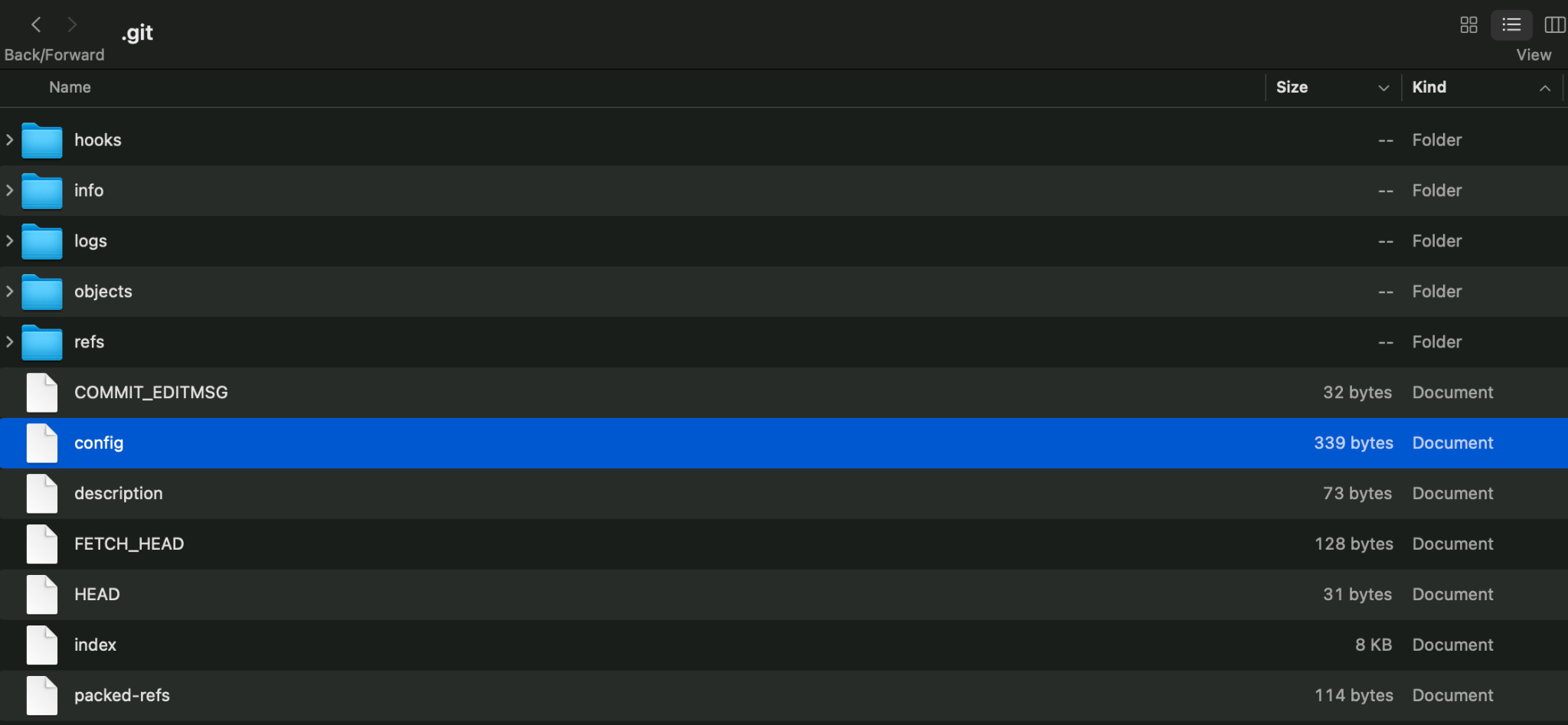
(Dwayne McDaniel, CC BY-SA 4.0)
One of the first things you notice is how small the files are.
Things are measured in terms of bytes or kilobytes, at the largest. Git is extremely efficient!
HEAD
Here in the .git folder, you find the special file HEAD. It's a very small file, only a handful of bytes in size. If you open it up, you see it’s only one line long.
git > HEAD
ref:refs/heads/mainOne of the phrases you will often encounter when reading about Git is "everything is local." From Git's perspective, wherever HEAD is pointing is "here." HEAD is the point of reference for how Git interacts with other branches, other refs, and other copies of itself.
In this example, the ref: is pointing at another pointer, a branch name pointer. Following that path, you can find a file that looks much like the spreadsheet from earlier. Git just takes the latest commit ID from the file and knows that is the commit HEAD is referring to.
If HEAD refers to a specific commit with no other pointer attached, then HEAD is referred to as "detached." Working in a detached HEAD state is completely safe, but limits what you can do, like make new commits from there. To get out of a detached HEAD state, just checkout another pointer, like the branch name, for example, git checkout main.
Config
Another critical file for helping Git keep track of things is the .git/config file. This is just one of the places Git leads and stores configuration. You're likely already familiar with the --global level of Git config, stored in your home directory in your .gitconfig file. There are actually five places Git loads config, each overriding the previous configuration. The order Git loads config is:
-
--systemThis loads config specific to your operating system -
--globalAffects you as a user,user.nameanduser.emailstored here -
--localThis sets repo specific info, like remotes and hooksPath -
--worktreeThe worktree is what is compressed into an individual commit -
--blobindividual compressed files can have their own settings
You can see all config for a repo by running git config --list --show-origin
You can leverage your local config to use multiple Git personas. Override the user.name and user.email in .gitconfig. Leveraging the local config is particularly useful when dividing your time between work projects, personal repos, and any open source contributions.
Git hooks
Git has a built-in powerful automation platform called Git hooks. Git hooks allows you to execute scripts that will run when certain events happen in Git. You can write scripts in any scripting language you prefer that is available to your environment. There are 17 hooks available.
If you look in any repo's .git/hooks folder, you see a collection of .sample files. These are pre-written samples meant to get you started. Some of them contain some odd-looking code. Odd, perhaps, until you remember that these mainly were added to serve the original use case for Linux kernel work and were written by people living in a sea of Perl and Bash scripts. You can make the scripts do anything you want.
Here's an example of a hook I use for personal repos:
#!/sur/bin/env bash
curl https://icanhazdadjoke.com
echo “”In this example, every time I run git commit but before the commit message is committed to my Git history, Git executes the script. (Thanks to Edward Thomson's git-dad for the inspiration.)
Of course, you can do practical things, too, like checking for hardcoded secrets before making a commit. To read more about Git Hooks and to find many, many example scripts, check out Matthew Hudson's fantastic GitHooks.com site.
Advanced Git
Now you have a better understanding of how Git sees the world and works behind the scenes, and you've seen how you can make it do your bidding with scripts. In my next article, I'll address some advanced tools and commands in Git.





1 Comment