

Users have many options to customize and extend ShardingSphere's high availability (HA) solutions. Our team has completed two HA plans: A MySQL high availability solution based on MGR and an openGauss database high availability solution contributed by some community committers. The principles of the two solutions are the same.
Below is how and why ShardingSphere can achieve database high availability using MySQL as an example:
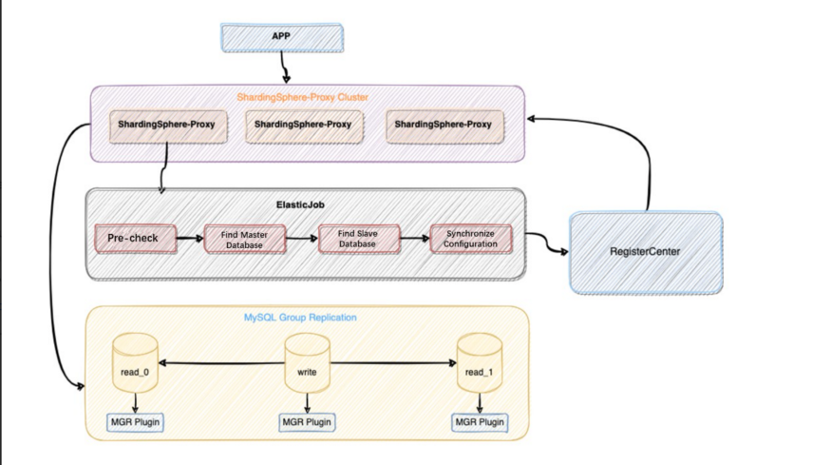
(Zhao Jinchao, CC BY-SA 4.0)
Prerequisite
ShardingSphere checks if the underlying MySQL cluster environment is ready by executing the following SQL statement. ShardingSphere cannot be started if any of the tests fail.
Check if MGR is installed:
SELECT * FROM information_schema.PLUGINS WHERE PLUGIN_NAME='group_replication'View the MGR group member number. The underlying MGR cluster should consist of at least three nodes:
SELECT count(*) FROM performance_schema.replication_group_membersCheck whether the MGR cluster's group name is consistent with that in the configuration. The group name is the marker of an MGR group, and each group of an MGR cluster only has one group name:
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_group_name' Check if the current MGR is set as the single primary mode. Currently, ShardingSphere does not support dual-write or multi-write scenarios. It only supports single-write mode:
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_single_primary_mode'Query all the node hosts, ports, and states in the MGR group cluster to check if the configured data source is correct:
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_membersDynamic primary database discovery
ShardingSphere finds the primary database URL according to the query master database SQL command provided by MySQL:
private String findPrimaryDataSourceURL(final Map<String, DataSource> dataSourceMap) {
String result = "";
String sql = "SELECT MEMBER_HOST, MEMBER_PORT FROM performance_schema.replication_group_members WHERE MEMBER_ID = "
+ "(SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME = 'group_replication_primary_member')";
for (DataSource each : dataSourceMap.values()) {
try (Connection connection = each.getConnection();
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql)) {
if (resultSet.next()) {
return String.format("%s:%s", resultSet.getString("MEMBER_HOST"), resultSet.getString("MEMBER_PORT"));
}
} catch (final SQLException ex) {
log.error("An exception occurred while find primary data source url", ex);
}
}
return result;
}Compare the primary database URLs found above one by one with the dataSources URLs configured. The matched data source is the primary database. It will be updated to the current ShardingSphere memory and be perpetuated to the registry center, through which it will be distributed to other compute nodes in the cluster.
(Zhao Jinchao, CC BY-SA 4.0)
Dynamic secondary database discovery
There are two types of secondary database states in ShardingSphere: enable and disable. The secondary database state will be synchronized to the ShardingSphere memory to ensure that read traffic can be routed correctly.
Get all the nodes in the MGR group:
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_membersDisable secondary databases:
private void determineDisabledDataSource(final String schemaName, final Map<String, DataSource> activeDataSourceMap,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (Entry<String, DataSource> entry : activeDataSourceMap.entrySet()) {
boolean disable = true;
String url = null;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
for (String each : memberDataSourceURLs) {
if (null != url && url.contains(each)) {
disable = false;
break;
}
}
} catch (final SQLException ex) {
log.error("An exception occurred while find data source urls", ex);
}
if (disable) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), true));
} else if (!url.isEmpty()) {
dataSourceURLs.put(entry.getKey(), url);
}
}
}Whether the secondary database is disabled is based on the data source configured and all the nodes in the MGR group.
ShardingSphere can check one by one whether the data source configured can obtain Connection properly and verify whether the data source URL contains nodes of the MGR group.
If Connection cannot be obtained or the verification fails, ShardingSphere will disable the data source by an event trigger and synchronize it to the registry center.
Enable secondary databases:
private void determineEnabledDataSource(final Map<String, DataSource> dataSourceMap, final String schemaName,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (String each : memberDataSourceURLs) {
boolean enable = true;
for (Entry<String, String> entry : dataSourceURLs.entrySet()) {
if (entry.getValue().contains(each)) {
enable = false;
break;
}
}
if (!enable) {
continue;
}
for (Entry<String, DataSource> entry : dataSourceMap.entrySet()) {
String url;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
if (null != url && url.contains(each)) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), false));
break;
}
} catch (final SQLException ex) {
log.error("An exception occurred while find enable data source urls", ex);
}
}
}
}After the crashed secondary database is recovered and added to the MGR group, the configuration will be checked to see whether the recovered data source is used. If yes, the event trigger will tell ShardingSphere that the data source needs to be enabled.
Heartbeat mechanism
The heartbeat mechanism is introduced to the HA module to ensure that the primary-secondary states are synchronized in real-time.
By integrating the ShardingSphere sub-project ElasticJob, the above processes are executed by the ElasticJob scheduler framework in the form of Job when the HA module is initialized, thus achieving the separation of function development and job scheduling.
Even if developers need to extend the HA function, they do not need to care about how jobs are developed and operated:
private void initHeartBeatJobs(final String schemaName, final Map<String, DataSource> dataSourceMap) {
Optional<ModeScheduleContext> modeScheduleContext = ModeScheduleContextFactory.getInstance().get();
if (modeScheduleContext.isPresent()) {
for (Entry<String, DatabaseDiscoveryDataSourceRule> entry : dataSourceRules.entrySet()) {
Map<String, DataSource> dataSources = dataSourceMap.entrySet().stream().filter(dataSource -> !entry.getValue().getDisabledDataSourceNames().contains(dataSource.getKey()))
.collect(Collectors.toMap(Entry::getKey, Entry::getValue));
CronJob job = new CronJob(entry.getValue().getDatabaseDiscoveryType().getType() + "-" + entry.getValue().getGroupName(),
each -> new HeartbeatJob(schemaName, dataSources, entry.getValue().getGroupName(), entry.getValue().getDatabaseDiscoveryType(), entry.getValue().getDisabledDataSourceNames())
.execute(null), entry.getValue().getHeartbeatProps().getProperty("keep-alive-cron"));
modeScheduleContext.get().startCronJob(job);
}
}
}Wrap up
So far, Apache ShardingSphere's HA feature has proven applicable for MySQL and openGauss HA solutions. Moving forward, it will integrate more MySQL HA products and support more database HA solutions.
As always, if you're interested, you're more than welcome to join us and contribute to the Apache ShardingSphere project.
Apache ShardingSphere Open Source Project Links:




Comments are closed.