

Apache Mesos is a cluster manager that provides efficient resource isolation and sharing across distributed applications or frameworks. Mesos is a open source software originally developed at the University of California at Berkeley. It sits between the application layer and the operating system and makes it easier to deploy and manage applications in large-scale clustered environments more efficiently. It can run many applications on a dynamically shared pool of nodes. Prominent users of Mesos include Twitter, Airbnb, MediaCrossing, Xogito and Categorize.
Mesos leverages features of the modern kernel—"cgroups" in Linux, "zones" in Solaris—to provide isolation for CPU, memory, I/O, file system, rack locality, etc. The big idea is to make a large collection of heterogeneous resources. Mesos introduces a distributed two-level scheduling mechanism called resource offers. Mesos decides how many resources to offer each framework, while frameworks decide which resources to accept and which computations to run on them. It is a thin resource sharing layer that enables fine-grained sharing across diverse cluster computing frameworks, by giving frameworks a common interface for accessing cluster resources.The idea is to deploy multiple distributed systems to a shared pool of nodes in order to increase resource utilization. A lot of modern workloads and frameworks can run on Mesos, including Hadoop, Memecached, Ruby on Rails, Storm, JBoss Data Grid, MPI, Spark and Node.js, as well as various web servers, databases and application servers.
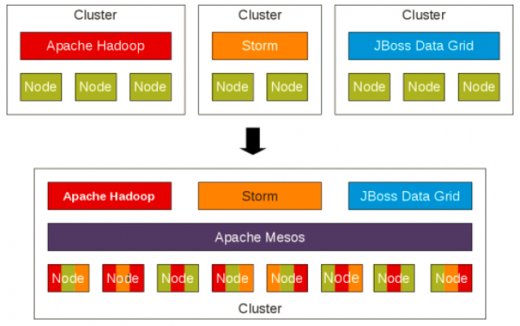
Node abstraction in Apache Mesos (source)
In a similar way that a PC operating system manages access to the resources on a desktop computer, Mesos ensures applications have access to the resources they need in a cluster. Instead of setting up numerous server clusters for different parts of an application, Mesos allows you to share a pool of servers that can all run different parts of your application without them interfering with each other and with the ability to dynamically allocate resources across the cluster as needed. That means, it could easily switch resources away from framework1 (for example, doing big-data analysis) and allocate them to framework2 (for example, a web server), if there is heavy network traffic. It also reduces a lot of the manual steps in deploying applications and can shift workloads around automatically to provide fault tolerance and keep utilization rates high.
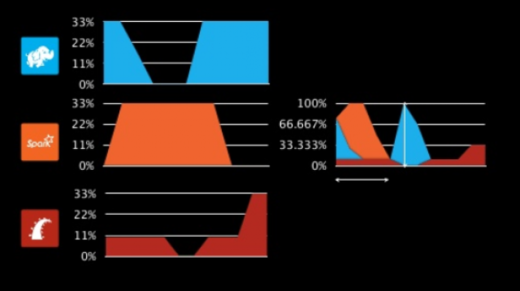
Resource sharing across the cluster increases throughput and utilization (source)
Mesos is essentially data center kernel—which means it's the software that actually isolates the running workloads from each other. It still needs additional tooling to let engineers get their workloads running on the system and to manage when those jobs actually run. Otherwise, some workloads might consume all the resources, or important workloads might get bumped by less-important workloads that happen to require more resources.Hence Mesos needs more than just a kernel—Chronos scheduler, a cron replacement for automatically starting and stopping services (and handling failures) that runs on top of Mesos. The other part of the Mesos is Marathon that provides API for starting, stopping and scaling services (and Chronos could be one of those services).
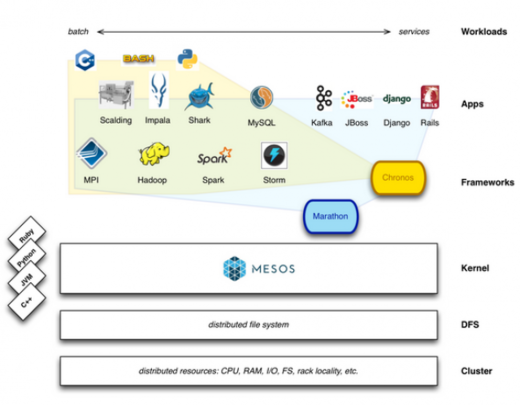
Workloads in Chronos and Marathon (source)
Architecture
Mesos consists of a master process that manages slave daemons running on each cluster node, and frameworks that run tasks on these slaves. The master implements fine-grained sharing across frameworks using resource offers. Each resource offer is a list of free resources on multiple slaves. The master decides how many resources to offer to each framework according to an organizational policy, such as fair sharing or priority. To support a diverse set of inter-framework allocation policies, Mesos lets organizations define their own policies via a pluggable allocation module.
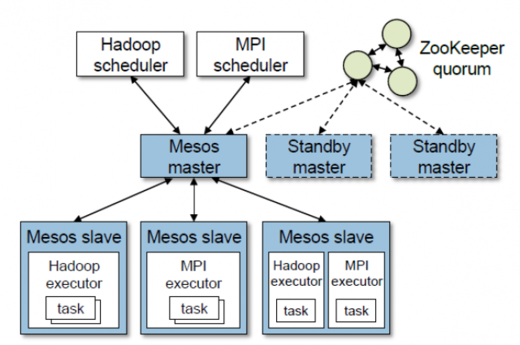
Mesos architecture with two running frameworks (source)
Each framework running on Mesos consists of two components: a scheduler that registers with the master to be offered resources, and an executor process that is launched on slave nodes to run the framework's tasks. While the master determines how many resources to offer to each framework, the frameworks' schedulers select which of the offered resources to use. When a framework accepts offered resources, it passes Mesos a description of the tasks it wants to launch on them.
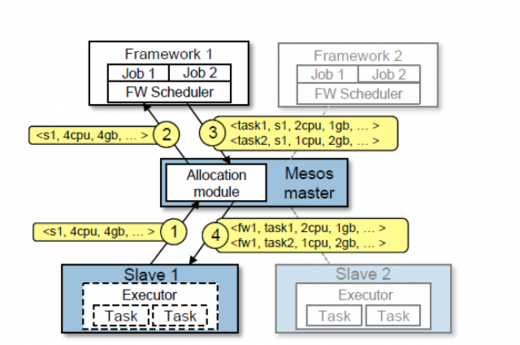
Framework scheduling in Mesos (source)
The figure above shows an example of how a framework gets scheduled to run tasks. In step one, slave 1 reports to the master that it has 4 CPUs and 4 GB of memory free. The master then invokes the allocation module, which tells it that framework 1 should be offered all available resources. In step two, the master sends a resource offer describing these resources to framework 1. In step three, the framework's scheduler replies to the master with information about two tasks to run on the slave, using 2 CPUs; 1 GB RAM for the first task, and 1 CPUs; 2 GB RAM for the second task. Finally, in step four, the master sends the tasks to the slave, which allocates appropriate resources to the framework's executor, which in turn launches the two tasks (depicted with dotted borders). Because 1 CPU and 1 GB of RAM are still free, the allocation module may now offer them to framework 2. In addition, this resource offer process repeats when tasks finish and new resources become free.
While the thin interface provided by Mesos allows it to scale and allows the frameworks to evolve independently. A framework will reject the offers that do not satisfy its constraints and accept the ones that do. In particular, we have found that a simple policy called delay scheduling, in which frameworks wait for a limited time to acquire nodes storing the input data, yields nearly optimal data locality.
Mesos features
- Fault-tolerant replicated master using ZooKeeper
- Scalability to thousands of nodes
- Isolation between tasks with Linux containers
- Multi-resource scheduling (memory and CPU aware)
- Java, Python and C++ APIs for developing new parallel applications
- Web UI for viewing cluster state
There are a number of software projects built on top of Apache Mesos:
Long Running Services
- Aurora is a service scheduler that runs on top of Mesos, enabling you to run long-running services that take advantage of Mesos' scalability, fault-tolerance, and resource isolation.
- Marathon is a private PaaS built on Mesos. It automatically handles hardware or software failures and ensures that an app is "always on."
- Singularity is a scheduler (HTTP API and web interface) for running Mesos tasks: long running processes, one-off tasks, and scheduled jobs.
- SSSP is a simple web application that provides a white-label "Megaupload" for storing and sharing files in S3.
Big Data Processing
- Cray Chapel is a productive parallel programming language. The Chapel Mesos scheduler lets you run Chapel programs on Mesos.
- Dpark is a Python clone of Spark, a MapReduce-like framework written in Python, running on Mesos.
- Exelixi is a distributed framework for running genetic algorithms at scale.
- Hadoop : Running Hadoop on Mesos distributes MapReduce jobs efficiently across an entire cluster.
- Hama is a distributed computing framework based on Bulk Synchronous Parallel computing techniques for massive scientific computations e.g., matrix, graph and network algorithms.
- MPI is a message-passing system designed to function on a wide variety of parallel computers.
- Spark is a fast and general-purpose cluster computing system which makes parallel jobs easy to write.
- Storm is a distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing.
Batch Scheduling
- Chronos is a distributed job scheduler that supports complex job topologies. It can be used as a more fault-tolerant replacement for cron.
- Jenkins is a continuous integration server. The mesos-jenkins plugin allows it to dynamically launch workers on a Mesos cluster depending on the workload.
- JobServer is a distributed job scheduler and processor which allows developers to build custom batch processing Tasklets using point and click web UI.
- Torque is a distributed resource manager providing control over batch jobs and distributed compute nodes.
Data Storage
- Cassandra is a highly available distributed database. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
- ElasticSearch is a distributed search engine. Mesos makes it easy to run and scale.
- Hypertable is a high performance, scalable, distributed storage and processing system for structured and unstructured data.
Conclusion
Trends such as cloud computing and big data are moving organizations away from consolidation and into situations where they might have multiple distributed systems dedicated to specific tasks. With the help of Docker executor for Mesos, Mesos can run and manage Docker containers in conjunction with Chronos and Marathon frameworks. Docker containers provide a consistent, compact and flexible means of packaging application builds. Delivering applications with Docker on Mesos promises a truly elastic, efficient and consistent platform for delivering a range of applications on premises or in the cloud.
Originally posted on Sachin Puttur's Big Data blog. Revisions made under Creative Commons.




1 Comment