

How does OpenStack merge over 900 documentation changes in less than three months? We treat docs like code and continuously publish reviewed content from multiple git repositories.
CI stands for continuous integration. Usually CI implies that the code is continually tested, integrated with other code changes, and then merged. Continuous deployment (CD) means the code is continously deployed with each patch to the entire code base. In the case of documentation, it means the content is continuously tested, merged with each patch and deployed. For documentation, deploying means publishing. For example, deploying docs means the output files are copied to a web server for all to see.
CI/CD for documentation
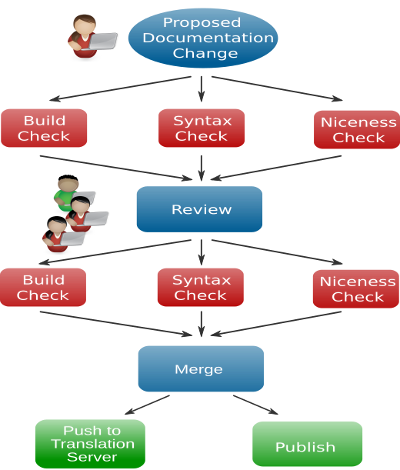
Changes to any OpenStack repository, including our documentation repositories, can only be done using the Gerrit code review system. Gerrit is an additional web-based review tool we have in place for code collaboration and reviews, run by the OpenStack infrastructure team. The basic workflow is that a documentation contributor checks out the documentation repositories, makes changes to the documents, tests them locally, commits them to git—our source control revision system—and then uploads them to OpenStack's Gerrit instance. Gerrit then sends a notification that there is a new change to Jenkins, which provides continuous integration services for software development. Once the notification from Gerrit comes through, Jenkins runs the various test suites that are configured for the repository. In reality, OpenStack runs eight Jenkins instances in parallel and uses a home-grown tool called Zuul to coordinate. You can see the status of any given build on the Zuul website.
As soon as the change is uploaded to Gerrit, reviewers can see the change and start commenting on it. The web user interface of Gerrit allows line-by-line reviews of the change. So, a reviewer can comment directly on any problems spotted in the source file. We also have implemented tests that build the documentation so a reviewer can see built documentation in HTML or PDF when applicable. Once a reviewer has commented on a change, she can also vote for the change. Voting here is not a democratic process but more an evaluation of whether the patch should go in. A reviewer can give a positive vote (yes, this should go in) or a negative one (this needs some more work)—or only comment and abstain from voting.
Everybody can review in OpenStack's Gerrit with these votes:
- 0: No score
- +1: Looks good to me, but someone else must approve
- -1: This patch needs further work before it can be merged
We also need comments on the patch, stating why it is wrong, questions asking for clarification, or stating why it is fine. These comments help the original author and other reviewers to update and evaluate the change.
A special group of senior reviewers, the so-called "core reviewers" can also give a +2 (or -2) vote and approve a change so that it can be published. These reviews are indicated with either:
- +2: Looks good to me (core reviewer)
- -2: Do not merge
Once two core reviewers have given a +2, a core reviewer—normally the second one that gave a +2 to the change—approves the change and then it merges and gets published. A change with negative review comments does not get approved so the docs won't be published until consensus is reached and the proper approvals come through.
The automatic testing by Jenkins also results in a vote during the review phase. Once a change is approved, Jenkins runs the tests again—on the changes merged with the then current, updated git repository—to ensure that no regressions come in. A change can only merge if Jenkins reviews the change positively.
All these automatic changes are run in HP and Rackspace public clouds. The OpenStack project currently uses up to 950 virtual machines for this. For every test job, a machine gets started, the repository with the tested change checked out in it, any dependencies for the test suite gets installed, and then the test suite gets executed. Yes, we are using the cloud for docs about the cloud.
The tests we run currently are listed in the section below.
What are the benefits when using CI/CD for docs?
OpenStack has multiple projects merging multiple changes every day, so the documentation system also needs to be able to keep up with that many changes. Continuous integration and deployment enables that, so it's not only a benefit but a requirement in our environment. Writers have the same workflow that developers use, and get the same recognition and rewards as developer contributors.
We have also found that it takes the burden of building documentation off of local writer's environments, although contributors still need to be able to build docs locally. By having a built draft ready for review, casual contributors and reviewers avoid the overhead of downloading the patch, replicating the build environment, and then building the docs. We can review both the source and output thanks to the automation in the system.
The speed of the builds increases because writers can work on multiple patches at once while the cloud-based CI/CD continues to run.
In OpenStack, the infrastructure team also uses many of these same techniques for for administration of servers.
Due to the test scripts, a writer starts always with a working state and the master branch always builds. If a document does not build locally or in another environment, the writer can be sure that it was his own fault and not an already broken tree.
The building and publishing of draft docs allows reviewers to quickly check how a change gets rendered when it is published. They do not need to download and build locally and thus can review more quickly.
We're also using the same workflow that is used by OpenStack developer and infrastructure team, this makes it easy for developers to contribute to documentation. With our recent move to RST as format, it is even easier since RST is the common markup language used in OpenStack.
Automation risks and pitfalls
Considering that writing is both an art and a craft, we do try to strike a balance between what should be automated and what still requires a master crafter. One early fear would be publishing too soon, or publishing incomplete documentation. We have found that as long as reviewers have guidelines such as "it's better than what we have now" or "I've tested this and know it to work" or "this doc fix matches the reported bug I've investigated" then the risk of publishing updates 50-100 times a day goes down.
We have had to build trust amongst reviewers and we still have great in-person discussions about reviews at our six-month Summits. We've written a review guide as well as tried to train reviewers about using best judgement when reviewing patches. We have also written a set of review guidelines. Not only is continuous integration part of our speed of publishing, but also having trusted reviewers use good judgement, while letting the robot test reviews give them confidence they don't have to worry that the docs won't build or that we'd break the entire docs site overnight.
We have some manuals that are release independent as well as manuals that document the current release. For the manuals documenting a specific release, like the installation guides, we update them for each new release and work in branches. The released document gets updated with critical changes, the document for the next release gets the majority of changes and gets published in a hidden place for easy review of the current draft. We publish these release specific guides publicly once the software release is out and then start working on updating for the next release.
Documentation tests
Jenkins allows execution of scripts and the documentation team has its own repository with test scripts, mostly written in Python. We develop those scripts using the same workflow we use for documentation. Once we have made major changes, a release of the test tools is done and that release is then used to test any documentation changes. In the documentation repositories, we use a Python convention of a test-requirments.txt file that indicates which release version of openstack-doc-tools works with a given set of doc source files.
To allow reviewers to concentrate on content and not have to nit-pick on form, the automatic tests handle most of the nit-picking for us. We don't require all the automatic tests to pass in order to publish the document, however. Some tests are marked as "voting," meaning that the doc will not merge unless it passes all these tests. Other tests are marked as "non-voting," meaning we allow the patch to land even if the test fails. The automatic tests are:
- Check the syntax of indvidual files. This helps to quick locate syntax errors. Syntax can be tested for DocBook XML, WADL XML, RST, and JSON formats, however we only test DocBook XML and RST. JSON is checked for proper formatting in a different test.
- Check that the documents build. A side benefit of this is that the resulting guides are uploaded to a draft server so that reviewers can easily review the newly generated books and see how a change looks in HTML and PDF.
- Check that the translated manuals build through the toolchain.
- Check that the files are "nice". This checks—depending on file type (XML, RST, or JSON)—for extraneous whitespace, overlong lines, some unwanted unicode characters, or proper formatting (JSON). Extra whitespace and too-long lines make it more difficult to review source files side-by-side. Our tool chain cannot output some unicode characters and JSON files should meet the formatting standard.
- Check that links to external websites work. This checks that all URLs in changed DocBook XML files are reachable. Since websites might be down, this change is marked as "non-voting".
- Check that no XML file gets deleted which is used by other manuals. This is important since we only build changed manuals and therefore we have to check that all manuals can still be build if one file gets removed.
We also do a few optimizations in the test scripts. For example, since building of DocBook XML files is expensive, a small dependency builder checks which files are changed and which guides include these files and then only those guides are build. Other tests, like syntax or URL checks also are only run on the changed files. There's no reason to check files again and again that have not changed and while testing a single file might be fast, testing nearly a thousand XML files is slow.
These optimizations are currently not done on RST files since RST files are much easier to parse and building of the guides is faster as well.
We do not run any grammar or spell checker since a voting check needs to always be accurate. We have had plenty of discussions about automating spell checks, but that really requires a human eye for judgement calls.
Additional uses of the CI infrastructure
We use it to talk to our translation server. The translation team uses the translation server—currently Transifex—to translate manuals. Whenever a change is merged, the CI infrastructure uploads the current text automatically to the translation server, so that translators can directly translate and always have the latest strings. Once a day, a so-called "periodic" job is run on the CI infrastructure to download all translated strings from the translation server to the documentation repositories and then a change is proposed with any new strings. This gives us a chance to run the translation import through the CI infrastructure together with manual review.
Additionally, we use the CI infrastructure to sync some shared files from one repository to a few others. These files are our shared glossary and the shared "support appendix" together with their translations. After a change is merged to the master repository of these files, it is checked whether the files in the other repositories need an update and if that is the case, then a change for that repository gets proposed. Again, this allows to run the test suite on the import and a final manual review.
Summary
Hopefully this article gives you ideas about how we use continuous integration and deployment with our OpenStack documentation processes. We have found the benefits far outweigh any risks in the approach. Our need to match with other teams means we adopted the continuous mentality to ship early and often. Take a look at your open source documentation with an eye towards automation and see what pops out at you.
This article was written collaboratively with Andreas Jaeger. Anne and Andreas are both members of the OpenStack Documentation team. Andreas is also involved with the OpenStack CI Infrastructure. He has consumed and contributed to various Open Source projects for over 20 years and works for SUSE.




1 Comment