

The use of Docker as an application container management system has become standard practice for developers and systems engineers in the space of just two years. Some like to say that haven’t seen such a technological advance since OpenSSH. Docker is now a major player and is widely used in cloud systems architectures. But more than just that: Docker knows how to win developers over.
Let's take a look at an overview of what we’ve done with Docker, as well as an assessment of the future and of the competition that is appearing on the horizon.
So what is Docker again?
Docker is a microcontainer management tool that uses libcontainer. Developed in Go by Solomon Hykes, Docker became open source in 2013 and was quickly adopted by key accounts. The tool’s flexibility was a game changer.
Before its arrival, creating an application container required a mastery of relatively advanced concepts. LXC had already started to grab the lion’s share, giving “pure virtualization” solutions a run for their money. OpenVZ and Xen also played some role. But those systems were mostly designed for server solutions, and demanded considerable configuration work.
Let’s be clear: Docker is not a replacement for LXC, OpenVZ or Xen. And it’s not a virtualization solution the way that KVM, VirtualBox and VMWare are. Docker has another vision, another method of operation, and does not serve the exact same purposes.
Like OpenVZ, Xen and LXC, Docker uses the principle of rootfs, which is nothing more than a root file system. It uses a tree structure as the root for a remote system (like chroot would do) and offers a network layer and a set-up system. But it also has its share of differences.
First, its images and containers are layered using union mount filesystem (as aufs, devicemapper, ...). On the one hand, this saves disk space, but it also makes it possible to quickly build a container without copying an entire root.
The other difference is that Docker avoids the initialization phase of the guest system. In other words, the container’s root is only used as an environment for the targeted application.
Lastly, Docker comes standard with the ability to manage an image versioning registry. By default, a public registry is used. That registry offers a multitude of off-the-shelf images (either official images or images submitted by users in the community), as well as a private space that can be made available for a fee. In theory, Docker is quite similar to Git and its Hub could be compared to a service like GitHub. It also uses common concepts like commits, tags and a remote registry server.
The community has been active around the project, proposing tools for autostarts (fig, now Docker Compose) or for simplifying cloud integration and administration processes (CoreOS), monitoring tools (cAdvisor), and the list goes on.
Today, Docker is flooding the IT world. OpenStack, Amazon, Google, CoreOS, and more: they’re all looking into this technology, if they haven’t already integrated it with their infrastructure.
But competition is coming!
Convenient for systems
Docker’s primary appeal is undoubtedly its ease of creating containers to manage microservices. A container is, first and foremost, a way to completely isolate an application. Thanks to its libcontainer library, Docker uses that memory and process isolation through the management of cgroups.
Docker won’t open a port on the host machine unless specifically asked to do so. If two containers need to communicate via the IP layer, they can be linked together so that those two instances can communicate using names instead of IP addresses (that may change each time containers restart).
Cloud scaling
Docker has become very popular in the cloud for the low level of resources that it uses, its volume management and its union mount filesystem, which reduces the disk space needed. In studying how Docker works, you realize that it is very simple to create a scalable and/or high availability system.
The “docker” command is in fact a simple REST client that communicates with the daemon. By default, the service (daemon) creates a unix socket (/var/run/docker.sock) that supplies that API. The “docker” commands merely use the API.
The API can be used to listen to events like when a container is created, started or stopped. When you work with the information provided by this API, you can determine which container is running which service, on which port, etc.
If you don’t want to or are unable to use the structures required by CoreOS, OpenStack, etc., you may be able to create your own architecture and tools, relatively easily. The API is fairly simple to access and highly effective.
Here is an example of architecture used in one of our projects.
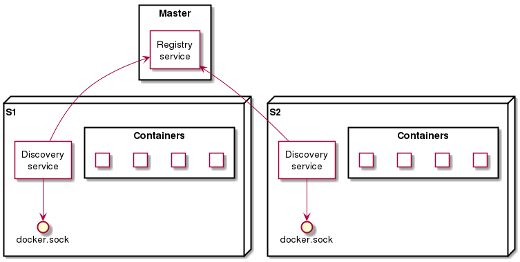
In this arrangement:
-
Each physical slave server has a discovery service that listens to the Docker socket.
-
When a container starts or stops, the service sends the information to the master server.
The master server can then take appropriate action, such as by modifying the nginx server's configuration, or deleting/removing an upstream server.
Another option is to change Docker’s configuration so that the API is accessible in TCP mode (making it network accessible). In this specific case, a small client connects to all the slave servers and listens to all their events. Otherwise, the principle is the same as above: each event will allow an upstream server to be added or deleted in nginx (for example).
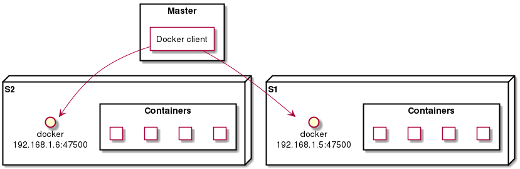
The difference here is that the master must handle all the connections to all the slaves. The previous method is less costly, because the slaves are the ones connecting to the master.
In both cases, the primary server is notified each time a container starts or stops and can modify the primary nginx server, restart containers or prevent an incident.
It’s also certainly possible to set up two master servers for failover management. The solution is adaptable and easy to maintain.
Convenient for developers
True, Docker is really suited for systems administrators. But it can also be seriously useful to production, i.e. for developers. One solution that we used for a customer was a combination of Dockerfiles and docker-compose files (for retrieval of the fig project by Docker).
The idea is to define what a developer’s workstation needs to run the project, and then to create Dockerfiles (if needed) that will build images in line with the constraints, as well as a docker-compose.yml file linking the containers.
Then, when using a version control server (Git, Mercurial, SVN, etc.), you simply set up the project directory to include those files and the project’s source code and to specify the volumes to be fed to the containers. Next, the team retrieves the project, and the only command needed to start the services is “docker-compose up”.
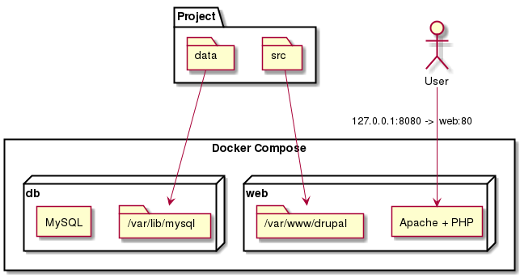
Let’s take the example of a Drupal project. Two containers can be used:
-
a MySQL container;
-
a container with Apache + the PHP module.
Drupal’s source codes are placed in “/src” and sent to the Apache container. This is the principle of volume: a local directory or file on the host can be attached to one or more containers in a specific directory. You then do the same for the MySQL storage directory so as not to lose the records saved to the database.
The Dockerfile could for example be:
FROM debian:7
MAINTAINER admin-dt@smile.fr
# Install software
RUN apt-get update && apt-get install apache2 php5 php5-mysql libapache2-mod-php5
# Start Apache
CMD /usr/sbin/apache2ctl -D FOREGROUND
And the docker-compose.yml file:
web:
dockerfile: .
volumes:
- "./src:/var/www/drupal
ports:
- "8080:80"
links:
- "db"
db:
image: mysql
volumes:
- "./data:/var/lib/mysql"
The “web” service is linked to “db” (see the “links” directive in the example above), so it is possible to read environment variables that supply MySQL addresses and ports (presented in its Dockerfile).
Here, for example, the following variables are accessible in the “web” container:
DB_PORT_3306_TCP_ADDR=172.17.1.24DB_PORT_3306_TCP_PORT=3306- etc.
Resolved container names can also be used, and “web” and “db” are considered to be machine names in the two containers.
In other words, the address “mysql://db” is resolved. You then just need to modify the Drupal configuration file to access the database, and your work is done. The project will have the following structure:
- ”data/” to store MySQL data;
- ”src/” containing Drupal’s source code;
- ”Dockerfile” to create the Apache/PHP image;
- ”docker-compose.yml” which describes how to launch the containers.
To keep our example simple, we didn’t mention that the Apache configuration files are also volumes that are shared with the containers. The end result is that the web server’s configuration is modifiable.
You will also have noticed that the port bind has also been handled. Because developers don’t necessarily have the rights to use port 80, we map the local port 8080 to the Apache container’s port 80. The developer just needs to visit 127.0.0.1:8080 to see the Drupal instance in action.
To understand this connection, take a look at the diagram below.
Competition
It might almost seem like Docker is alone in its world, bathing in its sea of praise. But remember that Docker uses libcontainer and cgroups, meaning that, to be able to use those kernel capacities, the service has to run as a root. And this could potentially be exploited.
This is actually CoreOS and other’s criticism of Docker, despite its evident attraction to this technology, which allowed CoreOS to create one of the best-known cloud systems today. Docker requires root rights in order to interface with cgroups. But a service that runs as a root could potentially create a hole in the system.
Docker’s development team gave a courteous response. It’s clear that future upgrades will take that issue into account and that any suggestions for correcting these flaws (which have not caused any particular problems so far) will be examined with interest. But don’t panic: the likelihood of this flaw being exploited is relatively low. To date, the only fault that has been exploited dates back to a 2014 version (1.0), and it has since been plugged.
In short, CoreOS decided to create its own container system (that can use Docker images) named Rkt (pronounced “rock-it”). But there is nothing to stop you from continuing to use Docker with the CoreOS solution. Rkt had only just been announced when LinuxContainers (the umbrella project behind LXC) publicized the development of LXD in cooperation with Canonical.
As you can see, everything is in place for container management to move as close as possible to the kernel and, as a result, for performance levels to soar.
The more time passes, the more containers are becoming a necessity.
But what about Windows and OS X? For OS X, there has been no announcement and there is no existing product. The use of boot2docker (a virtual machine created to run Docker) is therefore not optional. Windows also requires boot2docker for now, although a recent announcement suggested the possibility of seeing containers running on Microsoft’s OS. To be continued...
Conclusion
Docker is clearly a technology suited to both development and systems administration. Its contributions toward simplification and performance, as well as its adaptability, make it possible to easily set up services in a way that was previously inaccessible. Regardless of your infrastructure’s size, Docker has options for you.
But its strengths can also be put to use for production. Development is becoming standardized, and the line between developers and systems is becoming ever finer. It remains to be seen how much evolution the next versions will present, and what the competition will offer.
For now, Docker is still king in this domain.




Comments are closed.