

An impedance mismatch in software architecture happens when there's a set of conceptual and technical difficulties between two components. It's actually a term borrowed from electrical engineering, where the impedance of electrical input and output must match for the circuit to work.
In software development, an impedance mismatch exists between images stored in an image repository and its deployment descriptors stored in the SCM. How do you know whether the deployment descriptors stored in the SCM are actually meant for the image in question? The two repositories don't track the data they hold the same way, so matching an image (an immutable binary stored individually in an image repository) to its specific deployment descriptors (text files stored as a series of changes in Git) isn't straightforward.
NOTE: This article assumes at least a passing familiarity with the following concepts:
- Source Control Management (SCM) systems and branching
- Docker/OCI-compliant images and containers
- Container Orchestration Platforms (COP) such as Kubernetes
- Continuous Integration/Continuous Delivery (CI/CD)
- Software development lifecycle (SDLC) environments
Impedance mismatch: SCM and image repositories
To fully understand where this becomes a problem, consider a set of basic Software Development LifeCycle (SDLC) environments typically used in any given project; for example, dev, test, and prod (or release) environments.
The dev environment does not suffer from an impedance mismatch. Best practices, which today include using CI/CD, dictate that the latest commit to your development branch should reflect what's deployed in the development environment. So, given a typical, successful CI/CD development workflow:
- A commit is made to the development branch in the SCM
- The commit triggers an image build
- The new, distinct image is pushed to the image repository and tagged as being in dev
- The image is deployed to the dev environment in a Container Orchestration Platform (COP) with the latest deployment descriptors pulled from the SCM
In other words, the latest image is always matched to the latest deployment descriptors in the development environment. Rolling back to a previous build isn't an issue, either, because that implies rolling back the SCM, too.
Eventually, though, development progresses to the point where more formal testing needs to occur, so an image—which implicitly relates to a specific commit in the SCM—is promoted to a test environment. Again, assuming a successful build, this isn't much of a problem because the image promoted from development should reflect the latest in the development branch:
- The latest deployment to development is approved for promotion, and the promotion process is triggered
- The latest development image tagged as being in test
- The image is pulled and deployed to the test environment using the latest deployment descriptors pulled from the SCM
So far, so good, right? But what happens in either of the following scenarios?
Scenario A. The image is promoted to the next downstream environment, e.g., user acceptance testing (UAT) or even a production environment.
Scenario B. A breaking bug is discovered in the test environment, and the image needs to be rolled back to a known good image.
In either scenario, it's not as if development has stopped, which means one or more commits to the development branch may have occurred, which in turn means it's possible the latest deployment descriptors have changed, and the latest image isn't the same as what was previously deployed in test. Changes to the deployment descriptors may or may not apply to older versions of an image, but they certainly can't be trusted. If they have changed, they certainly aren't the same deployment descriptors you've been testing with up to now with the image you want to deploy.
And that's the crux of the problem: If the image being deployed isn't the latest from the image repository, how do you identify which deployment descriptors in the SCM apply specifically to the image being deployed? The short answer is, you can't. The two repositories have an impedance mismatch. The longer answer is that you can, but you have to work for it, which will be the subject of the rest of this article. Note that the following isn't necessarily the only solution to this problem, but it has been put into production and proven to work for dozens of projects that, in turn, have been built and deployed in production for more than a year now.
Binaries and deployment descriptors
A common artifact produced from building source code is a Docker or OCI-compliant image, and that image will typically be deployed to a Container Orchestration Platform (COP) such as Kubernetes. Deploying to a COP requires deployment descriptors defining how the image is to be deployed and run as a container, e.g., Kubernetes Deployments or CronJobs. It is because of the fundamental difference between what an image is and its deployment descriptors where the impedance mismatch manifests itself. For this discussion, think of images as immutable binaries stored in an image repository. Any change in the source code does not change the image but rather replaces it with a distinct, new image.
By contrast, deployment descriptors are text files and thus can be considered source code and mutable. If best practices are being followed, then the deployment descriptors are stored in SCM, and all changes are committed there first to be properly tracked.
Solving the impedance mismatch
The first part of the proposed solution is to ensure that a method exists of matching the image in the image repository to the source commit in the SCM, which holds the deployment descriptors. The most straightforward solution is to tag the image with its source commit hash. This will keep different versions of the image separate, easily identifiable, and provide enough information to find the correct deployment descriptors so that the image can be properly deployed in the COP.
Reviewing the scenarios above again:
Scenario A. Promoting an image from one downstream environment to the next: When the image is promoted from test to UAT, the image's tag tells us from which source commit in the SCM to pull the deployment descriptors.
Scenario B. When an image needs to be rolled back in a downstream environment: Whichever image we choose to roll back to will also tell us from which source commit in the SCM to pull the correct deployment descriptors.
In each case, it doesn't matter how many development branch commits and builds have taken place since a particular image has been deployed in test since every image that's been promoted can find the exact deployment descriptors it was originally deployed with.
This isn't a complete solution to the impedance mismatch, however. Consider two additional scenarios:
Scenario C. In a load testing environment, different deployment descriptors are tried at various times to see how a particular build performs.
Scenario D. An image is promoted to a downstream environment, and there's an error in the deployment descriptors for that environment.
In each of these scenarios, changes need to be made to the deployment descriptors, but right now all we have is a source commit hash. Remember that best practices require all source code changes to be committed back to SCM first. The commit at that hash is immutable by itself, so a better solution than just tracking the initial source commit hash is clearly needed.
The solution here is a new branch created at the original source commit hash. This will be dubbed a Deployment Branch. Every time an image is promoted to a downstream test or release environment, you should create a new Deployment Branch from the head of the previous SDLC environment's Deployment Branch.
This will allow the same image to be deployed differently and repeatedly within each SDLC environment and also pick up any changes discovered or applied for that image in each subsequent environment.
NOTE: How changes applied in one environment's deployment descriptors are applied to the next, whether by tools that enable sharing values such as Helm Charts or by manually cutting and pasting across directories, is beyond the scope of this article.
So, when an image is promoted from one SDLC environment to the next:
- A Deployment Branch is created
- If the image is being promoted from the dev environment, the branch is created from the source commit hash that built the image
- Otherwise, the Deployment Branch is created from the head of the current Deployment Branch
- The image is deployed into the next SDLC environment using the deployment descriptors from the newly created Deployment Branch for that environment
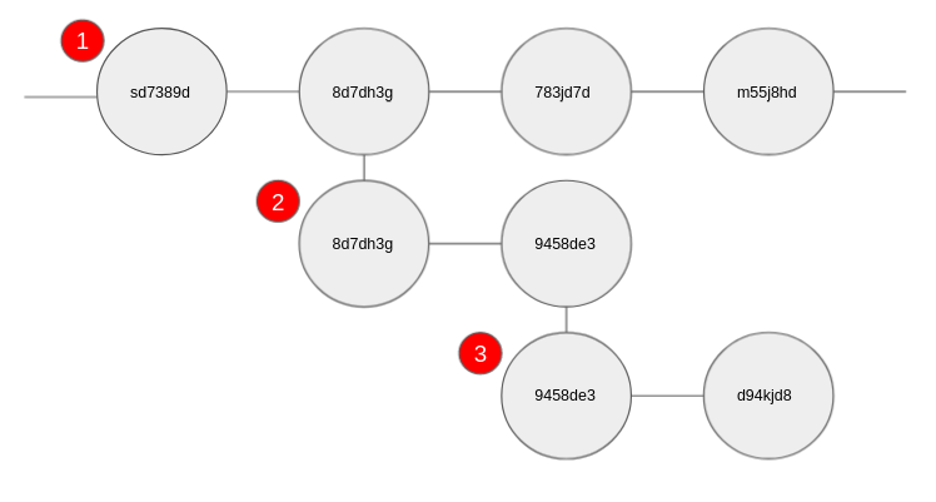
Figure 1: Deployment branches
- Development branch
- First downstream environment's Deployment Branch with a single commit
- Second downstream environment's Deployment Branch with a single commit
Revisiting Scenarios C and D from above with Deployment Branches as a solution:
Scenario C. Change the deployment descriptors for an image deployed to a downstream SDLC environment
Scenario D. Fix an error in the deployment descriptors for a particular SDLC environment
In each scenario, the workflow is as follows:
- Commit the changes to the deployment descriptors to the Deployment Branch for the SLDC environment and image
- Redeploy the image into the SLDC environment using the deployment descriptors at the head of the Deployment Branch
Thus, Deployment Branches fully resolve the impedance mismatch between image repositories storing a single, immutable image representing a unique build and SCM repositories storing mutable deployment descriptors for one more downstream SDLC environments.
Practical considerations
While this seems like a workable solution, it also opens up several new practical questions for developers and operations resources alike, such as:
A. Where should deployment descriptors be kept as source to best facilitate Deployment Branch management, i.e., in the same or a different SCM repository than the source that built the image?
Up until now, we've avoided speaking about which repository the deployment descriptors should reside. Without going into too much detail, we recommend putting the deployment descriptors for all SDLC environments into the same SCM repository as the image source. As Deployment Branches are created, the source for the images will follow and act as an easy-to-find reference for what is actually running in the container being deployed.
As mentioned above, images will be associated with the original source commit via their tag. Finding the reference for the source at a particular commit in a separate repository would add a level of difficulty to developers, even with tooling, which is unnecessary by keeping everything in a single repository.
B. Should the source code that built the image be modified on a Deployment Branch?
Short answer: NEVER.
Longer answer: No, because images should never be built from Deployment Branches. They're built from development branches. Changing the source that defines an image in a Deployment Branch will destroy the record of what built the image being deployed and doesn't actually modify the functionality of the image. This could also become an issue when comparing two Deployment Branches from different versions. It might give a false positive for differences in functionality between them (a small but additional benefit to using Deployment Branches).
C. Why an image tag? Couldn't image labels be used?
Tags are easily readable and searchable for images stored in a repository. Reading and searching for labels with a particular value over a group of images requires pulling the manifest for each image, which adds complexity and reduces performance. Also, tagging images for different versions is still necessary for historical record and finding different versions, so using the source commit hash is the easiest solution that guarantees uniqueness while also containing instantly useful information.
D. What is the most practical way to create Deployment Branches?
The first three rules of DevOps are automate, automate, automate.
Relying on resources to enforce best practices uniformly is hit and miss at best, so when implementing a CI/CD pipeline for image promotion, rollback, etc., incorporate automated Deployment Branching into the script.
E. Any suggestions for a naming convention for Deployment Branches?
<deployment-branch-identifier>-<env>-<src-commit-hash>
- deployment-branch-identifier: A unique string used by every Deployment Branch to identify it as a Deployment Branch; e.g. 'deployment' or 'deploy'
- env: The SDLC environment the Deployment Branch pertains to; e.g. 'qa', 'stg', or' prod' for the test, staging, and production environments, respectively
- src-commit-hash: The source code commit hash that holds the original code that built the image being deployed, which allows developers to easily find the original commit that created the image while ensuring the branch name is unique
For example, deployment-qa-asdf78s or deployment-stg-asdf78s for Deployment Branches promoted to the QA and STG environments, respectively.
F. How do you tell which version of the image is running in the environment?
Our suggestion is to label all your deployment resources with the latest Deployment Branch commit hash and the source commit hash. These two unique identifiers will allow developers and operations personnel to find everything that was deployed and from where. It also makes cleanup of resources trivial using those selectors on deployments of different versions, e.g., on rollback or roll forward operations.
G. When is it appropriate to merge changes from Deployment Branches back into the development branch?
It's completely up to the development team on what makes sense.
If you're making changes for load testing purposes just to see what will break your application, for example, then those changes may not be the best thing to merge back into the development branch. On the other hand, if you find and fix an error or tune a deployment in a downstream environment, merging the Deployment Branch changes back into the development branch makes sense.
H. Is there a working example of Deployment Branching to test with first?
el-CICD has been successfully using this strategy for a year and a half in production for more than a hundred projects across all SDLC downstream environments, including managing deployments to production. If you have access to an OKD, Red Hat OpenShift lab cluster, or Red Hat CodeReady Containers, you can download the latest el-CICD version and run through the tutorial to see how and when Deployment Branches are created and used.
Wrap up
Using the working example above would be a good exercise to help you better understand the issues surrounding impedance mismatches in development processes. Maintaining alignment between images and deployment descriptors is a critical part of successfully managing deployments.





Comments are closed.