

Lately, I've been looking at how Groovy streamlines Java. In this series, I'm developing several scripts to help in cleaning up my music collection. In my last article, I used the framework developed previously to create a list of unique file names and counts of occurrences of those file names in the music collection directory. I then used the Linux find command to get rid of files I didn't want.
In this article, I demonstrate a Groovy script to clean up the motley assembly of tag fields.
WARNING: This script alters music tags, so it is vital that you make a backup of the music collection you test your code on.
Back to the problem
If you haven't read the previous articles is this series, do that now before continuing so you understand the intended structure of the music directory, the framework I've created, and how to detect and use FLAC, MP3, and OGG files.
- How I analyze my music directory with Groovy
- My favorite open source library for analyzing music files
- How I use Groovy to analyze album art in my music directory
- Clean up unwanted files in your music directory using Groovy
Vorbis and ID3 tags
I don't have many MP3 music files. Generally, I prefer to use FLAC. But sometimes only MP3 versions are available, or a free MP3 download comes with a vinyl purchase. So in this script, I have to be able to handle both. One thing I've learned as I have become familiar with JAudiotagger is what ID3 tags (used by MP3) look like, and I discovered that some of those "unwanted" field tag IDs I uncovered in part 2 of this series are actually very useful.
Now it's time to use this framework to get a list of all the tag field IDs in a music collection, with their counts, to begin deciding what belongs and what doesn't:
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music library directory
7 def musicLibraryDirName = '/var/lib/mpd/music'
8 // Define the tag field id accumulation map
9 def tagFieldIdCounts = [:]
10 // Print the CSV file header
11 println "tagFieldId|count"
12 // Iterate over each directory in the music libary directory
13 // These are assumed to be artist directories
14 new File(musicLibraryDirName).eachDir { artistDir ->
15 // Iterate over each directory in the artist directory
16 // These are assumed to be album directories
17 artistDir.eachDir { albumDir ->
18 // Iterate over each file in the album directory
19 // These are assumed to be content or related
20 // (cover.jpg, PDFs with liner notes etc)
21 albumDir.eachFile { contentFile ->
22 // Analyze the file and print the analysis
23 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
24 def af = AudioFileIO.read(contentFile)
25 af.tag.fields.each { tagField ->
26 tagFieldIdCounts[tagField.id] = tagFieldIdCounts.containsKey(tagField.id) ? tagFieldIdCounts[tagField.id] + 1 : 1
27 }
28 }
29 }
30 }
31 }
32 tagFieldIdCounts.each { key, value ->
33 println "$key|$value"
34 }Lines 1-7 originally appeared in part 2 of this series.
Lines 8-9 define a map for accumulating tag field IDs and counts of occurrences.
Lines 10-21 also appeared in previous articles. They get down to the level of the individual content files.
Lines 23-28 ensures that the files being used are FLAC, MP3, or OGG. Line 23 uses a Groovy match operator ==~ with a slashy regular expression to filter out wanted files.
Line 24 uses org.jaudiotagger.audio.AudioFileIO.read() to get the tag body from the content file.
Lines 25-27 use org.jaudiotagger.tag.Tag.getFields() to get all the TagField instances in the tag body and the Groovy each() method to iterate over that list of instances.
Line 27 accumulates the count of each tagField.id into the tagFieldIdCounts map.
Finally, lines 32-24 iterate over the tagFieldIdCounts map printing out the keys (the tag field IDs found) and the values (the count of occurrences of each tag field ID).
I run this script as follows:
$ groovy TagAnalyzer5b.groovy > tagAnalysis5b.csvThen I load the results into a LibreOffice or OnlyOffice spreadsheet. In my case, this script takes quite a long time to run (several minutes) and the loaded data, sorted in descending order of the second column (count) looks like this:
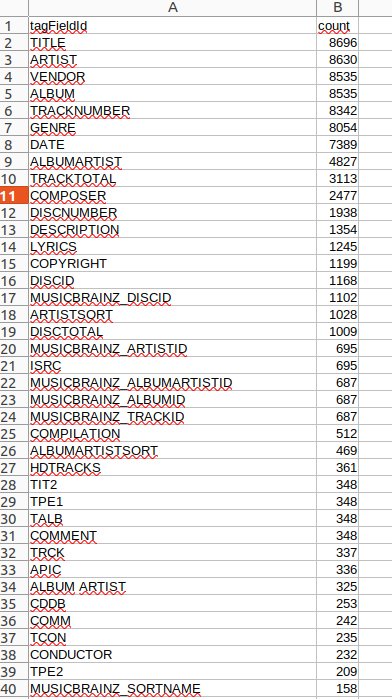
(Chris Hermansen, CC BY-SA 4.0)
On row 2, you can see that there are 8,696 occurrences of the TITLE field tag ID, which is the ID that FLAC files (and Vorbis, generally) uses for a song title. Down on row 28, you also see 348 occurrences of the TIT2 field tag ID, which is the ID3 tag field that contains the "actual" name of the song. At this point, it's worth going away to look at the JavaDoc for org.jaudiotagger.tag.ide.framebody.FrameBodyTIT2 to learn more about this tag and the way in which JAudiotagger recognizes it. There, you also see the mechanisms to handle other ID3 tag fields.
In that list of field tag IDs, there are lots that I'm not interested in and that could affect the ability of various music players to display my music collection in what I consider to be a reasonable order.
The org.jaudiotagger.tag.Tag interface
I'm going to take a moment to explore the way JAudiotagger provides a generic mechanism to access tag fields. This mechanism is described in the JavaDocs for org.jaudiotagger.tag.Tag. There are two methods that would help clean up the tag field situation:
void setField(FieldKey genericKey,String value)This is used to set the value for a particular tag field.
This line is used to delete all instances of a particular tag field (turns out some tag fields in some tagging schemes permit multiple occurrences).
void deleteField(FieldKey fieldKey)However, this particular deleteField() method requires us to supply a FieldKey value, and as I have discovered, not all field key IDs in my music collection correspond to a known FieldKey value.
Looking around the JavaDocs, I see there's a FlacTag which "uses Vorbis Comment for most of its metadata," and declares its tag field to be of type VorbisCommentTag.
VorbisCommentTag itself extends org.jaudiotagger.audio.generic.AbstractTag, which offers:
protected void deleteField(String key)As it turns out, this is accessible from the tag instance returned by AudioFileIO.read(f).getTag(), at least for FLAC and MP3 tag bodies.
In theory, it should be possible to do this:
-
Get the tag body using
def af = AudioFileIO.read(contentFile) def tagBody = af.tag -
Get the values of the (known) tag fields I want using:
def album = tagBody.getFirst(FieldKey.ALBUM) def artist = tagBody.getFirst(FieldKey.ARTIST) // etc -
Delete all tag fields (both wanted and unwanted) using:
def originalTagFieldIdList = tagBody.fields.collect { tagField -> tagField.id } originalTagFieldIdList.each { tagFieldId -> tagBody.deleteField(tagFieldId) } -
Put only the desired tag fields back:
tagBody.setField(FieldKey.ALBUM, album) tagBody.setField(FieldKey.ARTIST, artist) // etc
Of course there are few wrinkles here.
First, notice the use of the originalTagFieldIdList. I can't use each() to iterate over the iterator returned by tagBody.getFields() at the same time I modify those fields; so I get the tag field IDs into a list using collect(), then iterate over that list of tag field IDs to do the deletions.
Second, not all files are going to have all the tag fields I want. For example, some files might not have ALBUM_SORT_ORDER defined, and so on. I might not wish to write those tag fields in with empty values. Additionally, I can probably safely default some fields. For example, if ALBUM_ARTIST isn't defined, I can set it to ARTIST.
Third, and for me most obscure, is that Vorbis Comment tags always include a VENDOR field tag ID; if I try to delete it, I end up simply unsetting the value. Huh.
Trying it all out
Considering these lessons, I decided to create a test music directory that contains just a few artists and their albums (because I don't want to wipe out my music collection.)
WARNING: Because this script will alter music tags it is very important to have a backup of the music collection so that when I discover I have deleted an essential tag, I can recover the backup, modify the script and rerun it.
Here's the script:
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music library directory
7 def musicLibraryDirName = '/work/Test/Music'
8 // Print the CSV file header
9 println "artistDir|albumDir|contentFile|tagField.id|tagField.toString()"
10 // Iterate over each directory in the music libary directory
11 // These are assumed to be artist directories
12 new File(musicLibraryDirName).eachDir { artistDir ->
13 // Iterate over each directory in the artist directory
14 // These are assumed o be album directories
15 artistDir.eachDir { albumDir ->
16 // Iterate over each file in the album directory
17 // These are assumed to be content or related18 // (cover.jpg, PDFs with liner notes etc)
19 albumDir.eachFile { contentFile ->
20 // Analyze the file and print the analysis
21 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
22 def af = AudioFileIO.read(contentFile)
23 def tagBody = af.tag
24 def album = tagBody.getFirst(FieldKey.ALBUM)
25 def albumArtist = tagBody.getFirst(FieldKey.ALBUM_ARTIST)
26 def albumArtistSort = tagBody.getFirst(FieldKey.ALBUM_ARTIST_SORT)
27 def artist = tagBody.getFirst(FieldKey.ARTIST)
28 def artistSort = tagBody.getFirst(FieldKey.ARTIST_SORT)
29 def composer = tagBody.getFirst(FieldKey.COMPOSER)
30 def composerSort = tagBody.getFirst(FieldKey.COMPOSER_SORT)
31 def genre = tagBody.getFirst(FieldKey.GENRE)
32 def title = tagBody.getFirst(FieldKey.TITLE)
33 def titleSort = tagBody.getFirst(FieldKey.TITLE_SORT)
34 def track = tagBody.getFirst(FieldKey.TRACK)
35 def trackTotal = tagBody.getFirst(FieldKey.TRACK_TOTAL)
36 def year = tagBody.getFirst(FieldKey.YEAR)
37 if (!albumArtist) albumArtist = artist
38 if (!albumArtistSort) albumArtistSort = albumArtist
39 if (!artistSort) artistSort = artist
40 if (!composerSort) composerSort = composer
41 if (!titleSort) titleSort = title
42 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM|${album}"
43 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM_ARTIST|${albumArtist}"
44 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ALBUM_ARTIST_SORT|${albumArtistSort}"
45 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ARTIST|${artist}"
46 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.ARTIST_SORT|${artistSort}"
47 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.COMPOSER|${composer}"
48 println "${artistDir.name}|${albumDir.name}|${contentFile.name}
|FieldKey.COMPOSER_SORT|${composerSort}"
49 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.GENRE|${genre}"
50 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TITLE|${title}"
51 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TITLE_SORT|${titleSort}"
52 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TRACK|${track}"
53 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.TRACK_TOTAL|${trackTotal}"
54 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|FieldKey.YEAR|${year}"
55 def originalTagIdList = tagBody.fields.collect {
56 tagField -> tagField.id
57 }
58 originalTagIdList.each { tagFieldId ->
59 println "${artistDir.name}|${albumDir.name}|${contentFile.name}|${tagFieldId}|XXX"
60 if (tagFieldId != 'VENDOR')
61 tagBody.deleteField(tagFieldId)
62 }
63 if (album) tagBody.setField(FieldKey.ALBUM, album)
64 if (albumArtist) tagBody.setField(FieldKey.ALBUM_ARTIST, albumArtist)
65 if (albumArtistSort) tagBody.setField(FieldKey.ALBUM_ARTIST_SORT, albumArtistSort)
66 if (artist) tagBody.setField(FieldKey.ARTIST, artist)
67 if (artistSort) tagBody.setField(FieldKey.ARTIST_SORT, artistSort)
68 if (composer) tagBody.setField(FieldKey.COMPOSER, composer)
69 if (composerSort) tagBody.setField(FieldKey.COMPOSER_SORT, composerSort)
70 if (genre) tagBody.setField(FieldKey.GENRE, genre)
71 if (title) tagBody.setField(FieldKey.TITLE, title)
72 if (titleSort) tagBody.setField(FieldKey.TITLE_SORT, titleSort)
73 if (track) tagBody.setField(FieldKey.TRACK, track)
74 if (trackTotal) tagBody.setField(FieldKey.TRACK_TOTAL, trackTotal)
75 if (year) tagBody.setField(FieldKey.YEAR, year)
76 af.commit()77 }
78 }
79 }
80 }Lines 1-21 are already familiar. Note that my music directory defined in line 7 refers to a test directory though!
Lines 22-23 get the tag body.
Lines 24-36 get the fields of interest to me (but maybe not the fields of interest to you, so feel free to adjust for your own requirements!)
Lines 37-41 adjust some values for missing ALBUM_ARTIST and sort order.
Lines 42-54 print out each tag field key and adjusted value for posterity.
Lines 55-57 get the list of all tag field IDs.
Lines 58-62 prints out each tag field id and deletes it, with the exception of the VENDOR tag field ID.
Lines 63-75 set the desired tag field values using the known tag field keys.
Finally, line 76 commits the changes to the file.
The script produces output that can be imported into a spreadsheet.
I'm just going to mention one more time that this script alters music tags! It is very important to have a backup of the music collection so that when you discover you've deleted an essential tag, or somehow otherwise trashed your music files, you can recover the backup, modify the script, and rerun it.
Check the results with this Groovy script
I have a handy little Groovy script to check the results:
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 import org.jaudiotagger.tag.*
4 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
5 logger.setLevel(java.util.logging.Level.OFF);
6 // Define the music libary directory
7 def musicLibraryDirName = '/work/Test/Music'
8 // Print the CSV file header
9 println "artistDir|albumDir|tagField.id|tagField.toString()"
10 // Iterate over each directory in the music libary directory
11 // These are assumed to be artist directories
12 new File(musicLibraryDirName).eachDir { artistDir ->
13 // Iterate over each directory in the artist directory
14 // These are assumed to be album directories
15 artistDir.eachDir { albumDir ->
16 // Iterate over each file in the album directory
17 // These are assumed to be content or related
18 // (cover.jpg, PDFs with liner notes etc)
19 albumDir.eachFile { contentFile ->
20 // Analyze the file and print the analysis
21 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
22 def af = AudioFileIO.read(contentFile)
23 af.tag.fields.each { tagField ->
24 println "${artistDir.name}|${albumDir.name}|${tagField.id}|${tagField.toString()}"
25 }
26 }
27 }
28 }
29 }This should look pretty familiar by now!
Running it produces results like this before running the fixer script in the previous section:
St Germain|Tourist|VENDOR|reference libFLAC 1.1.4 20070213
St Germain|Tourist|TITLE|Land Of...
St Germain|Tourist|ARTIST|St Germain
St Germain|Tourist|ALBUM|Tourist
St Germain|Tourist|TRACKNUMBER|04
St Germain|Tourist|TRACKTOTAL|09
St Germain|Tourist|GENRE|Electronica
St Germain|Tourist|DISCID|730e0809
St Germain|Tourist|MUSICBRAINZ_DISCID|jdWlcpnr5MSZE9H0eibpRfeZtt0-
St Germain|Tourist|MUSICBRAINZ_SORTNAME|St GermainOnce the fixer script is run, it produces results like this:
St Germain|Tourist|VENDOR|reference libFLAC 1.1.4 20070213
St Germain|Tourist|ALBUM|Tourist
St Germain|Tourist|ALBUMARTIST|St Germain
St Germain|Tourist|ALBUMARTISTSORT|St Germain
St Germain|Tourist|ARTIST|St Germain
St Germain|Tourist|ARTISTSORT|St Germain
St Germain|Tourist|GENRE|Electronica
St Germain|Tourist|TITLE|Land Of...
St Germain|Tourist|TITLESORT|Land Of...
St Germain|Tourist|TRACKNUMBER|04
St Germain|Tourist|TRACKTOTAL|09That's it! Now I just have to work up the nerve to run my fixer script on my full music library…




Comments are closed.