

In this final article that concludes my series about best practices for effective site reliability engineering (SRE), I cover some of the practical applications of site reliability engineering.
There are some significant differences between software engineering and systems engineering.
Software engineering
- Focuses on software development and engineering only.
- Involves writing code to create useful functionality.
- Time is spent on developing repeatable and reusable software that can be easily extended.
- Has problem-solving orientation.
- Software engineering aids the SRE.
Systems engineering
- Focuses on the whole system including software, hardware and any associated technologies.
- Time is spent on building, analyzing, and managing solutions.
- Deals with defining characteristics of a system and feeds requirements to software engineering.
- Has systems-thinking orientation.
- Systems engineering enables SRE.
The site reliability engineer (SRE) utilizes both software engineering and system engineering skills, and in so doing adds value to an organization.
As the SRE team runs production systems, an SRE produces the most impactful tools to manage and automate manual processes. Software can be built faster when an SRE is involved, because most of the time the SRE creates software for their own use. As most of the tasks for an SRE are automated, which entails a lot of coding, this introduces a healthy mix of development and operations, which is great for site reliability.
Finally, an SRE enables an organization to automatically scale rapidly whether it's scaling up or scaling down.
SRE and DevSecOps
An SRE helps build end to end effective monitoring systems by utilizing logs, metrics and traces. An SRE enables fast, effective, and reliable rollbacks and automatic scaling up or down infrastructure as needed. These are especially effective during a security breach.
With the advent of cloud and container-based architectures, data processing pipelines have become a prominent component in IT architectures. An SRE helps configure the most restrictive access to data processing pipelines.
[ Download now: A guide to implementing DevSecOps ]
Finally, an SRE helps develop tools and procedures to handle incidents. While most of these incidents focus on IT operations and reliability, it can be easily extended to security. For example, DevSecOps deals with integrating development, security, and operations with heavy emphasis on automation. It's a field where development, security and operations teams work together to support and maintain an organization's applications and infrastructure.
Designing SRE and pre-production computing environments
A pre-production or non-production environment is an environment used by an SRE to develop, deploy, and test.
The non-production environment is the testing ground for automation. But it's not just application code that requires a non-production environment. Any associated automated processes, primarily the ones that an SRE develops, requires a pre-production environment. Most organizations have more than one pre-production environment. By resembling production as much as possible, the pre-production environment improves confidence in releases. At least one of your non-production environments should resemble the production environment. In many cases it's not possible to replicate production data, but you should try your best to make the non-production environments match the production environments as closely as possible.
Pre-production computing and the SRE
An SRE helps spin-up identical application serving environments by using automation and specialized tools. This is essential, as you can quickly spin up a non-production environment in a matter of seconds using scripts and tools developed by SREs.
A smart SRE treats configuration as code to ensure fast implementation of testing and deployment. Through the use of automated CI/CD pipelines, application releases and hot fixes can be made seamlessly.
Finally, by developing effective monitoring solutions, an SRE helps to ensure the reliability of a pre-production computing environment.
One of the closely related fields to pre-production computing is inner loop development.
Executing on inner loop development
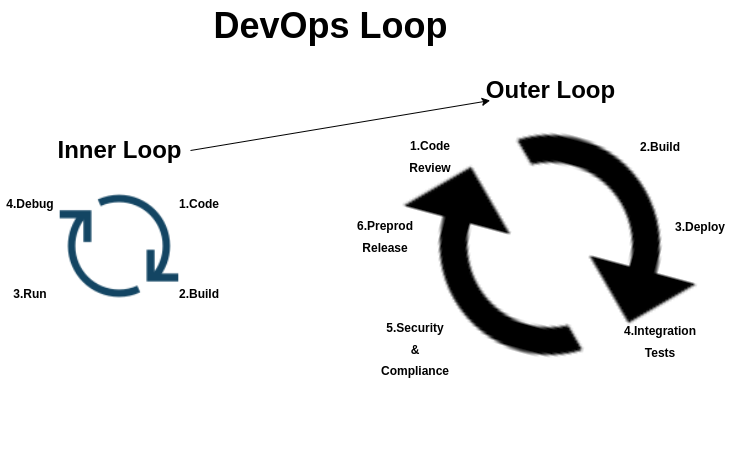
Picture two loops, an inner loop and an outer loop, forming the DevOps loop. In the inner loop, you code, build, run, and debug. This cycle mostly happens in a developer's workstation or some other non-production environment.
Once the code is ready, it is moved to the outer loop, where the process starts with code review, build, deploy, integration tests, security and compliance, and finally pre-production release.
Many of the processes in the outer loop and inner loop are automated by the SRE.
(Robert Kimani, CC BY-SA 40)
SRE and inner loop development
The SRE speeds up inner loop development by enabling fast, iterative development by providing tools for containerized deployment. Many of the tools an SRE develops revolve around container automation and container orchestration, using tools such as Podman, Docker, Kubernetes, or platforms like OpenShift.
An SRE also develops tools to help debug crashes with tools such as Java heap dump analysis tools, and Java thread dump analysis tools.
Overall value of SRE
By utilizing both systems engineering and software engineering, an SRE organization delivers impactful solutions. An SRE helps to implement DevSecOps where development, security, and operations intersect with a primary focus on automation.
SRE principles help maximize the function of pre-production environments by utilizing tools and processes that the SRE organizations deliver, so one can easily spin up non-production environment in a matter of seconds. An SRE organization enables efficient inner loop development by developing and providing necessary tools.
- Improved end user experience: It's all about ensuring that the users of the applications and services, get the best experience as possible. This includes uptime of the applications or services. Applications should be up and running all the time and should be healthy.
- Minimizes or eliminates outages: It's better for users and developers alike.
- Automation: As the saying goes, you should always be trying to automate yourself out of the job that you are currently performing manually.
- Scale: In the age of cloud-native applications and containerized services, massive automated scalability is critical for an SRE to scale up or down in a safe and fast manner.
- Integrated: The principles and processes that the SRE organization embraces can be, and in many cases should be, extended to other parts of the organization, as with DevSecOps.
The SRE is a valuable component in an efficient organization. As demonstrated over the course of this series, the benefits of SRE affect many departments and processes.
Further reading
Below are some GitHub links to a few of my favorite SRE resources:










Comments are closed.